LVIS_Instruct
收藏Hugging Face2026-05-20 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/geoskyr/LVIS_Instruct
下载链接
链接失效反馈官方服务:
资源简介:
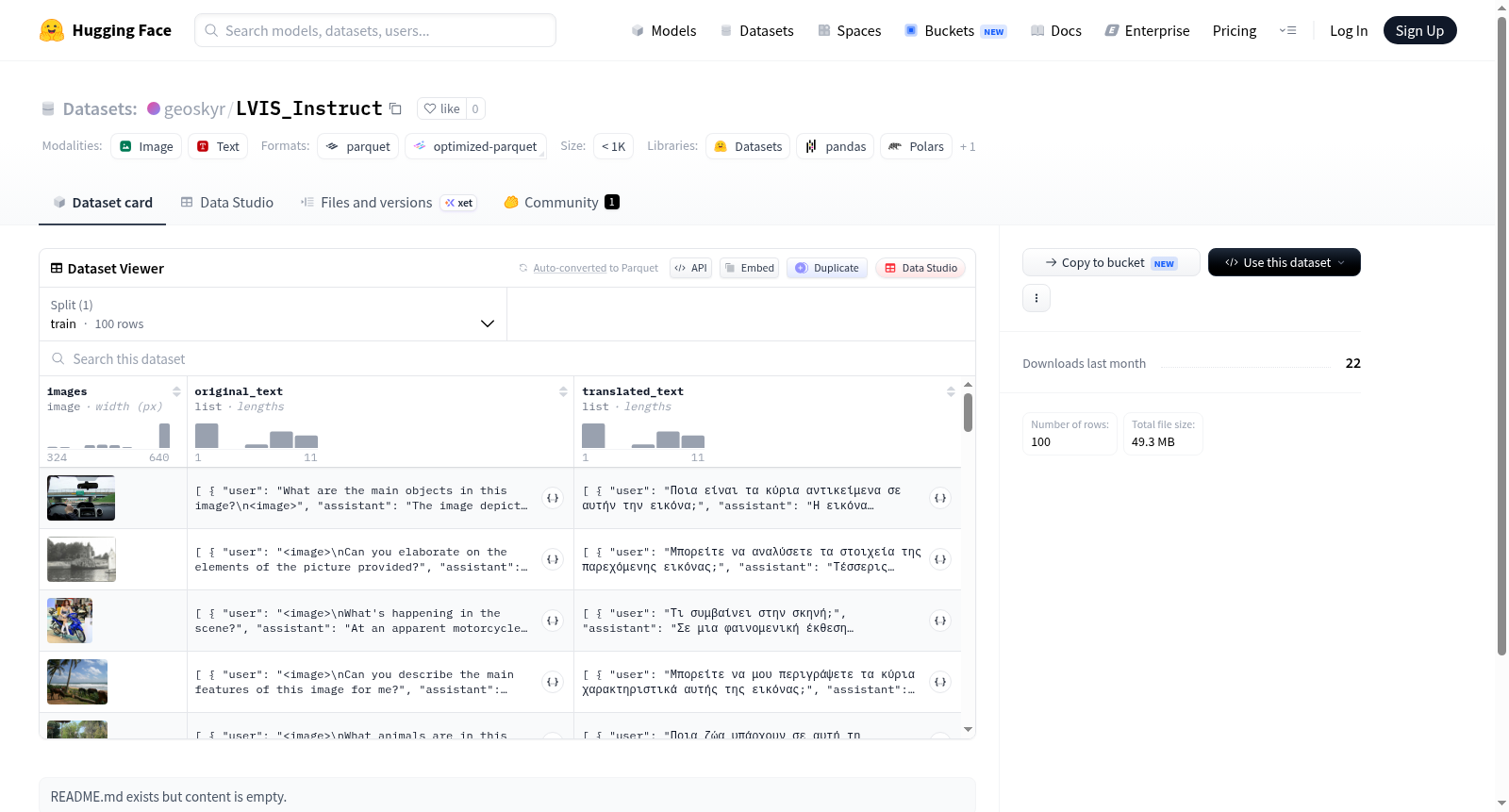
该数据集是一个多模态数据集,包含图像及对应的双语对话文本。每个样本由三个主要部分构成:1) 图像数据(images字段);2) 原始文本对话(original_text字段),以列表形式组织,包含用户(user)和助手(assistant)的对话轮次;3) 翻译后的文本对话(translated_text字段),结构与原始文本相同,同样包含用户和助手的对话内容。数据集规模为100个训练样本,总数据量约为49.48MB。从数据结构推断,该数据集适用于多模态任务,如图像描述生成、视觉问答、对话系统构建,以及跨语言的自然语言处理任务,如机器翻译或双语对话生成。数据以用户-助手对话对的形式呈现,暗示其可能用于指令遵循或对话代理的训练与评估。
This dataset is a multimodal dataset containing images and corresponding bilingual dialogue texts. Each sample consists of three main components: 1) image data (images field); 2) original text dialogue (original_text field), organized in a list format, including dialogue turns between users (user) and assistants (assistant); 3) translated text dialogue (translated_text field), with the same structure as the original text, also containing user and assistant dialogue content. The dataset has a scale of 100 training samples, with a total data size of approximately 49.48MB. Based on the data structure, it is suitable for multimodal tasks such as image caption generation, visual question answering, dialogue system construction, and cross-lingual natural language processing tasks like machine translation or bilingual dialogue generation. The data is presented in user-assistant dialogue pairs, suggesting its potential use for training and evaluation of instruction following or dialogue agents.
创建时间:
2026-05-19
搜集汇总
数据集介绍
构建方式
LVIS_Instruct数据集的构建基于LVIS(Large Vocabulary Instance Segmentation)数据集,通过精心设计的指令模板,将原始图像及其对应的细粒度实例分割标注转化为多轮对话形式。具体而言,每一张图像被赋予一组用户与助手之间的对话,其中用户提出与图像内容相关的问题,助手则依据LVIS提供的丰富类别和掩码信息进行详细解答。此外,数据集还包含翻译后的文本版本,以支持多语言场景下的视觉指令微调。整个数据集包含100个训练样本,每个样本均包含图像、原始对话文本及翻译文本。
特点
LVIS_Instruct数据集的核心特点在于其细粒度与高多样性。基于LVIS超过1200个类别的大词汇量设定,该数据集能够覆盖极其丰富的视觉概念,从而显著提升视觉语言模型对罕见或特定物体的理解能力。对话形式的设计使得模型不仅学习单一描述,还能掌握在复杂场景中进行推理与交互的技能。同时,双语文本的引入为跨语言视觉指令学习提供了宝贵的资源,增强了数据集的普适性与应用潜力。
使用方法
使用LVIS_Instruct数据集时,研究者可直接加载HuggingFace上的数据仓库,通过指定的数据分割(如'train')获取图像与对应的多轮对话文本。数据集兼容主流的视觉语言模型训练框架,如LLaVA或InstructBLIP,用户需将图像与对话序列配对输入,并利用translated_text字段进行多语言微调或评估。建议采用标准的图像预处理与文本分词流程,并注意该数据集规模较小,适合作为领域特定任务的微调或模型性能的快速验证集使用。
背景与挑战
背景概述
LVIS_Instruct数据集诞生于2024年,由多模态领域前沿研究团队创建,旨在推动细粒度视觉与语言理解任务的边界。核心研究问题聚焦于如何通过高质量指令数据,增强模型对LVIS(Large Vocabulary Instance Segmentation)数据集中1203类常见物体的精准识别与描述能力。该数据集将LVIS的密集标注图像与人工精细撰写的多轮对话相结合,构建了100个训练样本,以探索小样本条件下视觉语言模型的泛化性能。其影响力体现在为开放世界目标检测、图像描述生成等任务提供了可解释性更强的训练范式,尤其推动了指令微调策略在复杂场景中的实际应用。
当前挑战
面临的挑战包括:1) 领域问题层面,需要解决LVIS数据集长尾分布导致的稀有类别识别困难,以及现有模型对细粒度视觉特征(如材质、纹理)的语义映射不足,从而提升模型在开放场景下的零样本迁移能力。2) 构建过程中,由于原始文本需依赖人工专家进行精准的多轮问答创作,导致数据扩增效率低下;同时,图像与指令的对齐需兼顾语言多样性与视觉一致性,确保100个样本的有限规模仍能覆盖丰富的物体-关系组合,这对数据设计策略提出了严苛要求。
常用场景
经典使用场景
在计算机视觉与多模态学习领域中,LVIS_Instruct数据集以其精细的长尾开放词汇实例分割标注而独树一帜。该数据集基于LVIS(Large Vocabulary Instance Segmentation)构建,通过引入丰富的指令文本描述,将视觉感知任务与自然语言理解深度融合。其经典使用场景体现在训练具备细粒度视觉语义理解能力的多模态大模型上,研究者可借助该数据集使模型精准定位并识别超过1200个类别中的罕见物体,同时依据用户提供的自然语言指令执行复杂的分割与描述任务。这一设计突破了传统实例分割数据集的标签瓶颈,为开放词汇场景下的视觉对话与指令跟随研究奠定了坚实基础。
解决学术问题
LVIS_Instruct数据集聚焦于解决长尾分布下的细粒度视觉理解与语言对齐这一核心学术难题。传统实例分割数据集往往忽略少数类(如罕见物体)的标注质量,导致模型在真实开放场景中泛化能力薄弱。该数据集通过为每个图像配备多轮指令对话形式的文本描述,显著降低了模型对常见物体的过度依赖,推动研究者探索如何利用语言先验增强视觉编码器对长尾物体的表征能力。其深远意义在于提供了一个可扩展的范式,使得多模态大模型能够在弱监督或零样本条件下,突破类别数量限制,精准理解并分割用户指代的任意对象,从而推动计算机视觉向通用人工智能迈出关键一步。
衍生相关工作
LVIS_Instruct数据集的发布催生了多项具有里程碑意义的经典工作。在模型架构层面,研究者借鉴其指令跟随范式开发了InstructSeg系列模型,通过将实例分割任务统一建模为从视觉特征到语言锚点的映射过程,显著提升了少样本场景下的分割精度。在数据增强维度,后续工作如“LVIS-Instruct-4M”采用自训练策略将其扩展至更大规模,进一步验证了指令数据对改善模型长尾性能的普遍有效性。同时,该数据集还推动了多模态指令微调基准(如MME-Bench)的构建,使得评估模型在复杂视觉推理任务上的表现有了统一标准,这些衍生工作共同构成了当前开放词汇分割领域的核心研究脉络。
以上内容由遇见数据集搜集并总结生成


