S2T_Korean_Merge_2_fixed3
收藏Hugging Face2026-05-07 更新2026-05-08 收录
下载链接:
https://huggingface.co/datasets/PThi35/S2T_Korean_Merge_2_fixed3
下载链接
链接失效反馈官方服务:
资源简介:
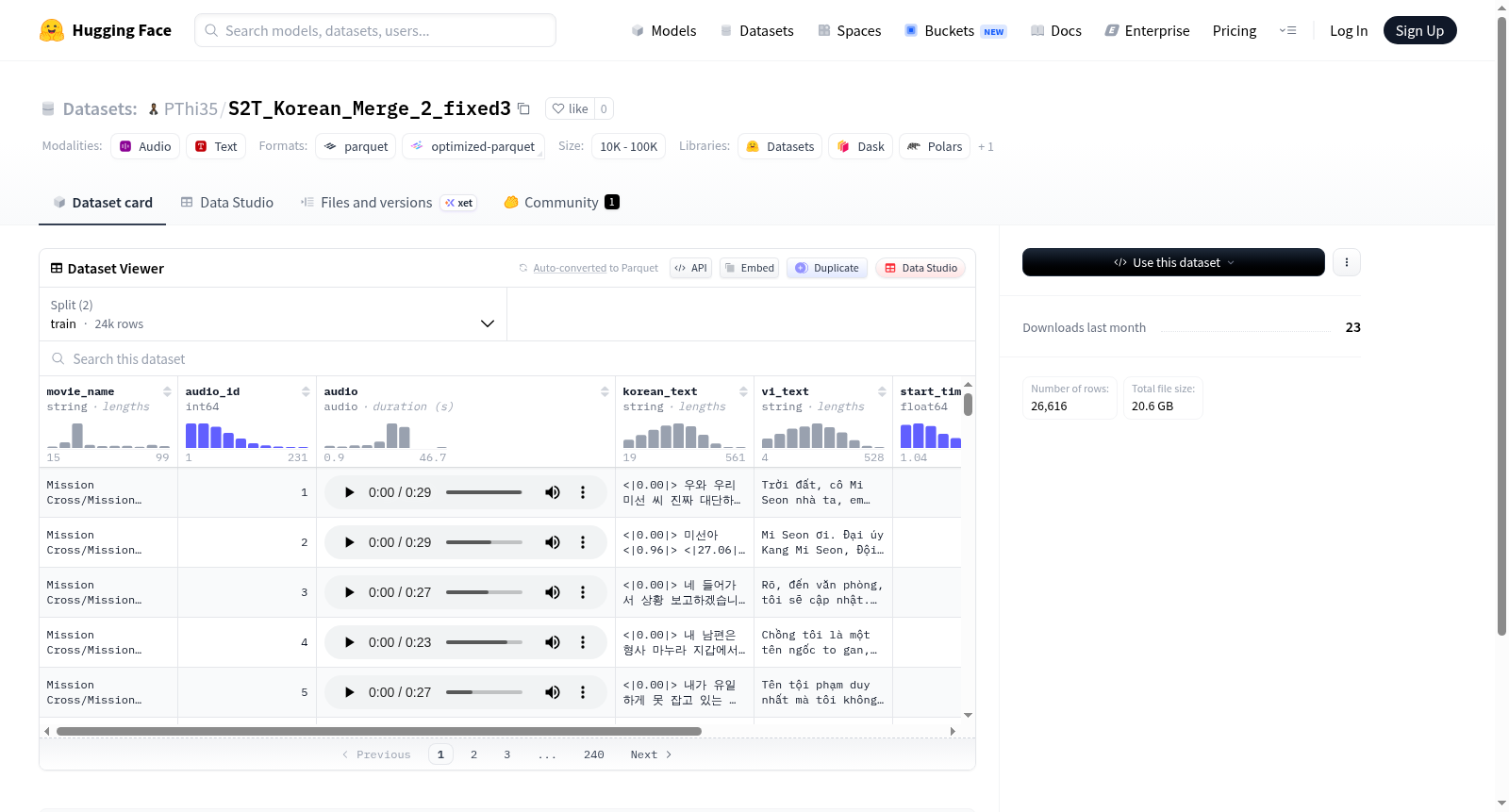
该数据集包含23,712个训练样本,总大小约18.5GB。每个样本包含以下字段:电影名称(字符串)、音频ID(整型)、音频文件(音频格式)、韩语文本(字符串)、越南语文本(字符串)、开始时间(浮点型)、结束时间(浮点型)和持续时间(浮点型)。数据集以音频片段及其对应的双语文本(韩语和越南语)为主要内容,并包含时间对齐信息。技术规格方面,下载文件大小约18.3GB,数据文件存储在train-*路径下。
This dataset contains 23,712 training samples with a total size of approximately 18.5GB. Each sample includes the following fields: movie name (string), audio ID (integer), audio file (audio format), Korean text (string), Vietnamese text (string), start time (float), end time (float), and duration (float). The dataset primarily consists of audio clips and their corresponding bilingual texts (Korean and Vietnamese), along with time alignment information. In terms of technical specifications, the download file size is approximately 18.3GB, and the data files are stored under the train-* path.
创建时间:
2026-05-06
原始信息汇总
根据您提供的数据集详情页面信息,以下为该数据集的概述:
数据集基本信息
- 数据集名称:S2T_Korean_Merge_2_fixed3
- 数据集地址:https://huggingface.co/datasets/PThi35/S2T_Korean_Merge_2_fixed3
- 数据集大小:18,519,915,516 字节(约18.52 GB)
- 下载大小:18,281,302,623 字节(约18.28 GB)
数据特征
该数据集包含以下8个字段:
| 字段名称 | 数据类型 | 说明 |
|---|---|---|
| movie_name | string | 电影名称 |
| audio_id | int64 | 音频ID |
| audio | audio | 音频数据 |
| korean_text | string | 韩语文本 |
| vi_text | string | 越南语文本 |
| start_time | float64 | 开始时间 |
| end_time | float64 | 结束时间 |
| duration | float64 | 持续时间 |
数据集划分
数据集中包含一个划分:
- train(训练集):共23,712个样本,占用18,519,915,516字节
配置信息
- 配置名称:default
- 数据文件路径:data/train-*
搜集汇总
数据集介绍
构建方式
该数据集名为S2T_Korean_Merge_2_fixed3,是针对韩语语音到文本任务构建的专业数据集。其构建过程整合了多源韩语音频素材,并通过精细化处理确保数据质量。每条样本包含电影名称、音频标识、原始音频文件、韩语文本、越南语译文、起止时间戳及音频时长等字段,形成了结构化的多模态数据单元。音频与文本的严格对齐是构建核心,通过统一的时间标注体系实现声学信号与语言符号的精确对应,为后续模型训练奠定坚实基础。
特点
本数据集最显著的特征在于其多语种对齐特性与精细化的时间标注。音频片段均带有精确的起止时间与时长信息,支持按需裁剪与灵活使用;同时提供韩语原文及对应的越南语译文,天然适用于跨语言语音翻译任务。数据集规模适中,训练集包含23,712条样本,总容量超过18GB,覆盖丰富的电影对白场景,兼顾数据多样性与训练效率。字段设计紧凑且通用性强,便于直接接入主流语音处理流水线。
使用方法
使用本数据集时,开发者可直接加载默认配置下的训练分割进行模型训练与评估。音频数据以标准音频格式存储,文本字段为纯文本形式,可通过HuggingFace Datasets库一键读取。典型应用场景包括韩语语音识别(ASR)与韩越语音翻译(S2T)系统的开发。建议根据任务需求选择对应的文本标签:语音识别任务使用korean_text字段,语音翻译任务则结合korean_text与vi_text构建源-目标对。时间戳字段可用于序列对齐与数据增强。
背景与挑战
背景概述
该数据集创建于近年,由研究人员针对韩语到越南语的语音翻译任务构建,核心研究问题在于提升低资源语言对(韩-越)的语音转文本(S2T)能力。数据集包含23,712条训练样本,每条样本均提供韩语语音及其对应的韩语和越南语文本,覆盖电影场景下的多模态信息。作为跨语言语音翻译领域的重要资源,它填补了韩-越语言对在端到端语音翻译中的空白,为多语种语音处理研究提供了数据基础,推动了低资源语言对的机器翻译与语音识别交叉领域发展。
当前挑战
所解决的领域问题在于韩-越语言对的语音翻译面临资源匮乏、口音多样性以及电影场景中背景噪声干扰等挑战,模型需同时处理语音识别与跨语言转换的双重任务。构建过程中面临的主要挑战包括:电影语音数据的收集与对齐(需精确匹配音频片段与对应时间戳的文本)、多语言文本的标注一致性维护(确保韩语原文与越南语译文的语义准确),以及大规模音频数据的存储与处理效率问题。
常用场景
经典使用场景
在跨语言语音翻译与多模态自然语言处理领域,S2T_Korean_Merge_2_fixed3 数据集以其精细的语音-文本对齐结构,成为连接韩语语音输入与越南语文本输出之间的桥梁。该数据集包含超过两万三千条训练样本,每条样本涵盖完整的韩语音频、对应的韩语文本以及精准的越南语翻译,同时记录时间戳与音频时长信息。研究者可基于此构建端到端的语音到文本翻译系统,尤其适用于低资源语言对(如韩语-越南语)的模型训练与评估,推动语音翻译技术从理论走向多语种实践。
解决学术问题
长期以来,韩语与越南语之间的语音翻译研究受限于对齐语料的匮乏,传统方法多依赖级联式语音识别与机器翻译的流水线架构,误差累积效应显著。该数据集通过提供音素级时间对齐的多模态语料,解决了跨语言语音翻译中时序同步与语义映射的双重难题。其出现使得学界能够探索基于注意力机制的端到端模型在低资源场景下的鲁棒性,并验证跨模态表示学习在语音-文本联合建模中的有效性,为缩小语种间数字鸿沟提供了关键数据支撑。
衍生相关工作
基于该数据集的结构特性,研究者已衍生出多项经典工作。在模型层面,可借鉴 Google USM 的通用语音模型框架,利用该数据微调多语言语音编码器;在基准评测方面,该数据常被用于对比不同序列到序列模型在语音翻译中的性能,如 Whisper 的微调变体与 Transformer 架构的端到端翻译系统。此外,部分工作围绕时间戳对齐噪声的鲁棒性展开,提出了基于对比学习的语音-文本预训练策略,进一步提升了模型在非精确对齐条件下的翻译质量,推动了语音翻译领域的基础设施建设。
以上内容由遇见数据集搜集并总结生成


