Galgame_Dataset_stats
收藏Hugging Face2024-10-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/litagin/Galgame_Dataset_stats
下载链接
链接失效反馈资源简介:
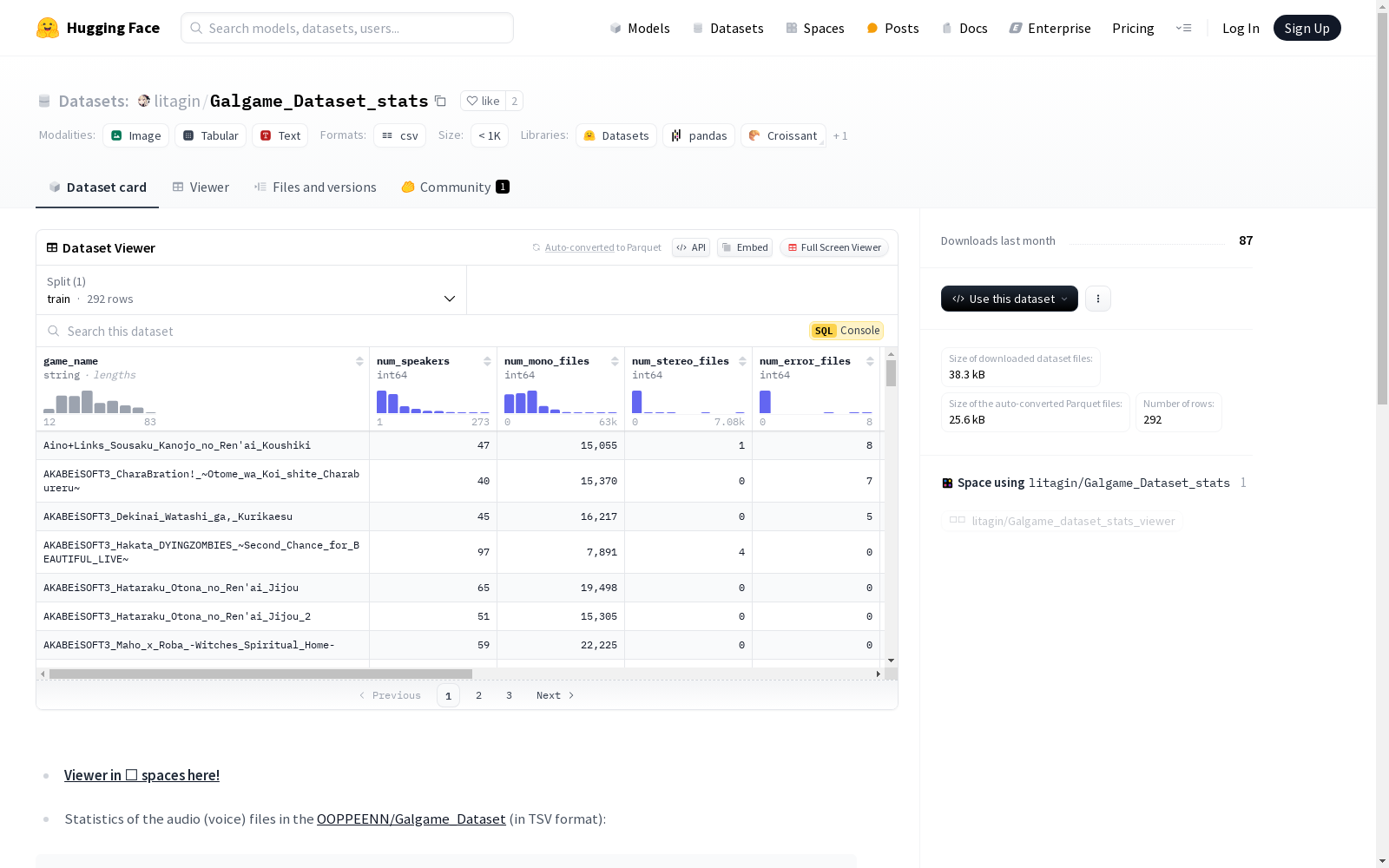
该数据集包含多个Galgame游戏的音频文件统计信息,包括游戏名称、说话者数量、单声道和立体声文件数量、错误文件数量、总时长、平均采样率、平均精度、平均比特率、编解码器和总大小。数据以TSV格式存储,游戏名称中的空格被替换为下划线,时长可能存在轻微的舍入误差,错误文件指的是Sox和pydub无法提取信息的文件。
创建时间:
2024-10-02
原始信息汇总
Galgame_Dataset_stats 数据集概述
数据集来源
- 数据集名称:Galgame_Dataset_stats
- 原始数据集:OOPPEENN/Galgame_Dataset
数据内容
- 数据格式:TSV(制表符分隔值)
- 数据内容:包含音频(语音)文件的统计信息
统计字段
game_name:游戏名称num_speakers:发言人数量num_mono_files:单声道文件数量num_stereo_files:立体声文件数量num_error_files:错误文件数量(Sox 和 pydub 无法提取信息的文件)total_duration_hours:总时长(小时)avg_sample_rate_kHz:平均采样率(kHz)avg_precision:平均精度avg_bitrate_kbps:平均比特率(kbps)codec:编解码器total_size_GB:总大小(GB)
数据示例
game_name num_speakers num_mono_files num_stereo_files num_error_files total_duration_hours avg_sample_rate_kHz avg_precision avg_bitrate_kbps codec total_size_GB Game1 47 15055 1 8 20.08 48.0 16.0 88.49 Vorbis 0.73 Game2 40 15370 0 7 30.10 47.8 16.0 87.113 Vorbis 1.07
其他信息
- 游戏名称中的空格被替换为下划线("_")。
- 时长值可能存在轻微的舍入误差,未来将更新以提供更准确的时长。
AI搜集汇总
数据集介绍
构建方式
Galgame_Dataset_stats数据集的构建基于对OOPPEENN/Galgame_Dataset中音频文件的统计分析。该数据集以TSV格式存储,详细记录了每个游戏的音频文件信息,包括音频文件的声道数量、错误文件数量、总时长、平均采样率、平均精度、平均比特率、编码格式以及总大小等。此外,每个游戏的频谱图图像也被随机选取并存储在specs文件夹中,以便进一步分析音频特征。
特点
Galgame_Dataset_stats数据集的特点在于其详尽的音频文件统计信息,涵盖了多个维度的音频特征。数据集不仅提供了每个游戏的音频文件数量、时长和编码格式等基本信息,还特别标注了错误文件的数量,帮助用户识别潜在的音频质量问题。频谱图图像的加入为音频特征的可视化分析提供了便利,使得用户能够更直观地理解音频数据的特性。
使用方法
Galgame_Dataset_stats数据集的使用方法较为直观,用户可以通过TSV文件直接访问每个游戏的音频统计信息。频谱图图像则可以通过specs文件夹进行查看,帮助用户进行音频特征的可视化分析。此外,数据集还提供了Google Sheets链接,方便用户在线查看和编辑数据。对于音频质量分析、编码格式研究以及游戏音频特征提取等任务,该数据集提供了丰富的基础数据支持。
背景与挑战
背景概述
Galgame_Dataset_stats数据集由OOPPEENN团队创建,旨在为Galgame(视觉小说游戏)领域的音频数据分析提供支持。该数据集收录了多款Galgame的音频文件,涵盖了语音文件的详细统计信息,如声道数量、采样率、比特率等。通过提供这些音频文件的频谱图,该数据集为语音处理、音频质量评估以及游戏音频内容分析等领域的研究提供了重要的数据基础。其创建时间可追溯至2023年,主要研究人员通过HuggingFace平台公开了数据集,进一步推动了Galgame音频研究的透明化和标准化。
当前挑战
Galgame_Dataset_stats数据集在构建过程中面临多重挑战。首先,音频文件的多样性和复杂性使得数据清洗和标注变得尤为困难,尤其是部分文件因损坏无法提取信息,需通过Sox和pydub工具进行筛选。其次,数据集的核心研究问题在于如何高效处理和分析大规模音频数据,尤其是在声道类型、采样率和比特率等参数不一致的情况下,确保数据的准确性和一致性。此外,频谱图的生成和存储也对计算资源提出了较高要求,如何在保证图像质量的同时优化存储空间,是数据集构建中的另一大挑战。
常用场景
经典使用场景
Galgame_Dataset_stats数据集在语音处理和多媒体分析领域具有广泛的应用。该数据集通过对Galgame游戏中的音频文件进行统计分析,提供了丰富的语音数据特征,如声道数量、文件格式、采样率等。这些数据为研究人员提供了宝贵的资源,用于探索语音合成、语音识别以及音频质量评估等领域的研究。
解决学术问题
该数据集解决了语音处理领域中的多个关键问题。通过对大量Galgame音频文件的统计分析,研究人员可以深入理解不同音频编码格式对语音质量的影响,探索多声道音频的处理技术,并开发更高效的音频压缩算法。此外,数据集中的错误文件统计也为音频文件的完整性检测提供了重要参考。
衍生相关工作
基于Galgame_Dataset_stats数据集,研究人员已经开展了多项相关工作。例如,利用该数据集中的音频特征,开发了新的语音识别模型,提升了在复杂音频环境下的识别准确率。此外,该数据集还推动了音频压缩算法的研究,使得在保持高质量音频的同时,显著减少了文件大小。这些衍生工作进一步拓展了数据集的应用范围,推动了语音处理技术的发展。
以上内容由AI搜集并总结生成


