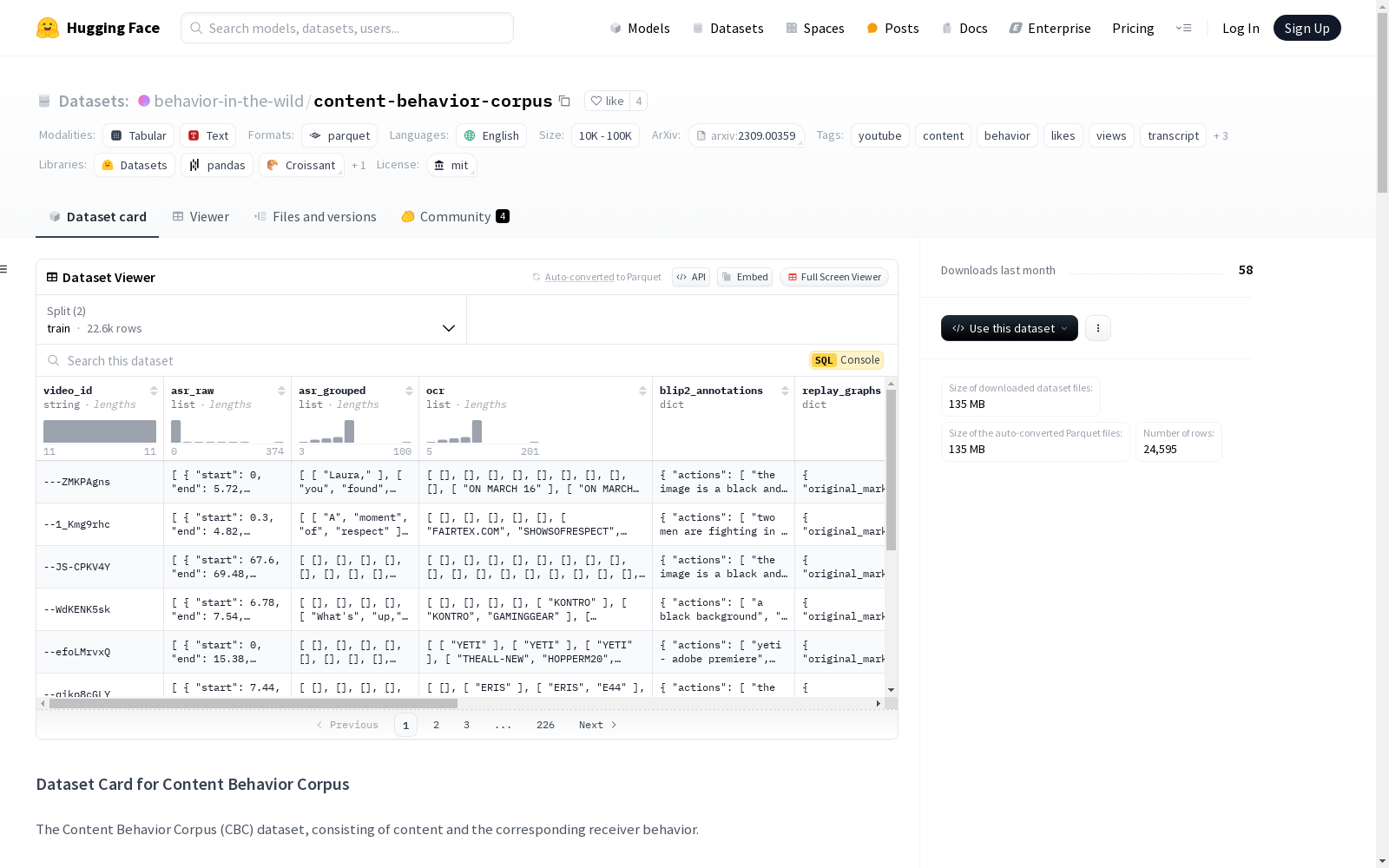
content-behavior-corpus
收藏数据集概述
数据集信息
特征
- video_id (
string): 视频的唯一标识符。 - asr_raw (
list of objects): 原始自动语音识别(ASR)数据。- start (
float64): ASR 片段的开始时间。 - end (
float64): ASR 片段的结束时间。 - text (
string): ASR 片段的转录文本。 - words (
list of objects): 单词级别的 ASR 详细信息。- confidence (
float64): ASR 单词的置信度分数。 - start (
float64): 单词的开始时间。 - end (
float64): 单词的结束时间。 - text (
string): 单词的转录文本。
- confidence (
- start (
- asr_grouped (
list of lists of strings): 按重播片段分组的 ASR 转录文本。 - ocr (
list of lists of strings): 每个重播片段的光学字符识别(OCR)数据。 - blip2_annotations (
object): 视频重播片段的 BLIP-2 注释。- actions (
list of strings): 每个重播片段中识别的动作列表。 - captions (
list of strings): 每个重播片段生成的图像字幕列表。 - objects (
list of strings): 每个重播片段中识别的对象列表。
- actions (
- replay_graphs (
object): 与视频重播行为相关的数据。- original_marker_duration (
float64): 重播片段的原始持续时间。 - processed_marker_duration (
float64): 重播片段的处理后持续时间。 - multiplier (
float64): 原始重播片段合并为处理后重播片段的倍数。 - markers (
list of objects): 重播片段。- start (
float64): 重播片段的开始时间。 - end (
float64): 重播片段的结束时间。 - replay_score (
float64): 重播行为的得分(范围为 [0, 1])。
- start (
- original_marker_duration (
- likes (
float64): 视频获得的点赞数。 - views (
float64): 视频获得的观看次数。 - metadata (
object): 与视频相关的元数据。- title (
string): 视频的标题。 - description (
string): 视频的描述。 - length (
float64): 视频的长度(以秒为单位)。 - date (
string): 视频的发布日期。
- title (
- channel_data (
object): YouTube 频道的信息。- channel_id (
string): 频道的唯一标识符。 - company_name (
string): 拥有频道的公司或个人名称。 - subscribers (
float64): 频道的订阅者数量。
- channel_id (
数据分割
- train
- num_bytes: 396758465
- num_examples: 22569
- test
- num_bytes: 35343326
- num_examples: 2026
数据集大小
- download_size: 135245985
- dataset_size: 432101791
配置
- config_name: default
- data_files:
- train: data/train-*
- test: data/test-*
- data_files:
许可证
- license: MIT
名称和标签
- pretty_name: Content Behavior Corpus
- language: en
- tags: youtube, content, behavior, likes, views, transcript, captions, OCR, replay
数据收集和处理
数据收集
- videos: 使用 pytube 下载。
- asr_raw: 使用 openai/whisper-medium 和 whisper-timestamped 库提取。
- asr_grouped: 从 asr_raw 中提取的单词按重播片段分组。
- ocr: 使用 PaddleOCR 提取。
- blip2_annotations: 使用 blip2-flan-t5-xxl 提取。
- replay_graphs: 通过直接解析视频页面的 HTML 内容提取。
- likes: 通过直接解析视频页面的 HTML 内容提取。
- views: 通过直接解析视频页面的 HTML 内容提取。
- metadata: 通过直接解析视频页面的 HTML 内容提取。
- channel_data: 通过直接解析视频页面的 HTML 内容提取。
引用
BibTeX
@inproceedings{ khandelwal2024large, title={Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior}, author={Ashmit Khandelwal and Aditya Agrawal and Aanisha Bhattacharyya and Yaman Kumar and Somesh Singh and Uttaran Bhattacharya and Ishita Dasgupta and Stefano Petrangeli and Rajiv Ratn Shah and Changyou Chen and Balaji Krishnamurthy}, booktitle={The Twelfth International Conference on Learning Representations}, year={2024}, url={https://arxiv.org/abs/2309.00359} }
APA
Khandelwal, A., Agrawal, A., Bhattacharyya, A., Kumar, Y., Singh, S., Bhattacharya, U., Dasgupta, I., Petrangeli, S., Shah, R. R., Chen, C., & Krishnamurthy, B. (2024). Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior. The Twelfth International Conference on Learning Representations. https://arxiv.org/abs/2309.00359
联系
- email: behavior-in-the-wild@googlegroups.com