fictional-knowledge
收藏Hugging Face2024-10-04 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/kaist-ai/fictional-knowledge
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是为一篇关于大型语言模型在预训练期间如何获取事实知识的论文创建的,包含130条虚构知识条目及其对应的探测器,用于测试大型语言模型的事实知识获取能力。每个虚构知识条目由GPT-4生成,使用ECBD数据集的实例作为模板。数据集包含训练上下文、记忆输入和目标、语义泛化输入和目标、组合泛化输入和目标等字段。前40个条目还包括注入知识的9种不同释义。数据集为英文,格式为JSON。
This dataset was developed for a paper examining how large language models acquire factual knowledge during pre-training. It contains 130 fictional knowledge entries and their corresponding probes, which are designed to test the factual knowledge acquisition capabilities of large language models. Each fictional knowledge entry is generated by GPT-4, using instances from the ECBD dataset as templates. The dataset includes fields such as training context, memory inputs and targets, semantic generalization inputs and targets, and compositional generalization inputs and targets. The first 40 entries additionally feature nine distinct paraphrases of the injected knowledge. The dataset is in English and formatted as JSON.
提供机构:
KAIST AI创建时间:
2024-10-04
原始信息汇总
Fictional Knowledge Dataset
数据集描述
该数据集是为论文《How Do Large Language Models Acquire Factual Knowledge During Pretraining?》(https://arxiv.org/abs/2406.11813)创建的。它包含130个虚构知识条目及其相应的探测器,用于测试大型语言模型的事实知识获取能力。每个虚构知识条目由GPT-4创建,使用ECBD数据集(https://aclanthology.org/2022.findings-naacl.52/)的一个实例作为模板。注意,最后10个实例被留作备用,未在原始论文的实验中使用。
数据集概述
- 大小: 130个条目
- 格式: JSON
- 语言: 英语
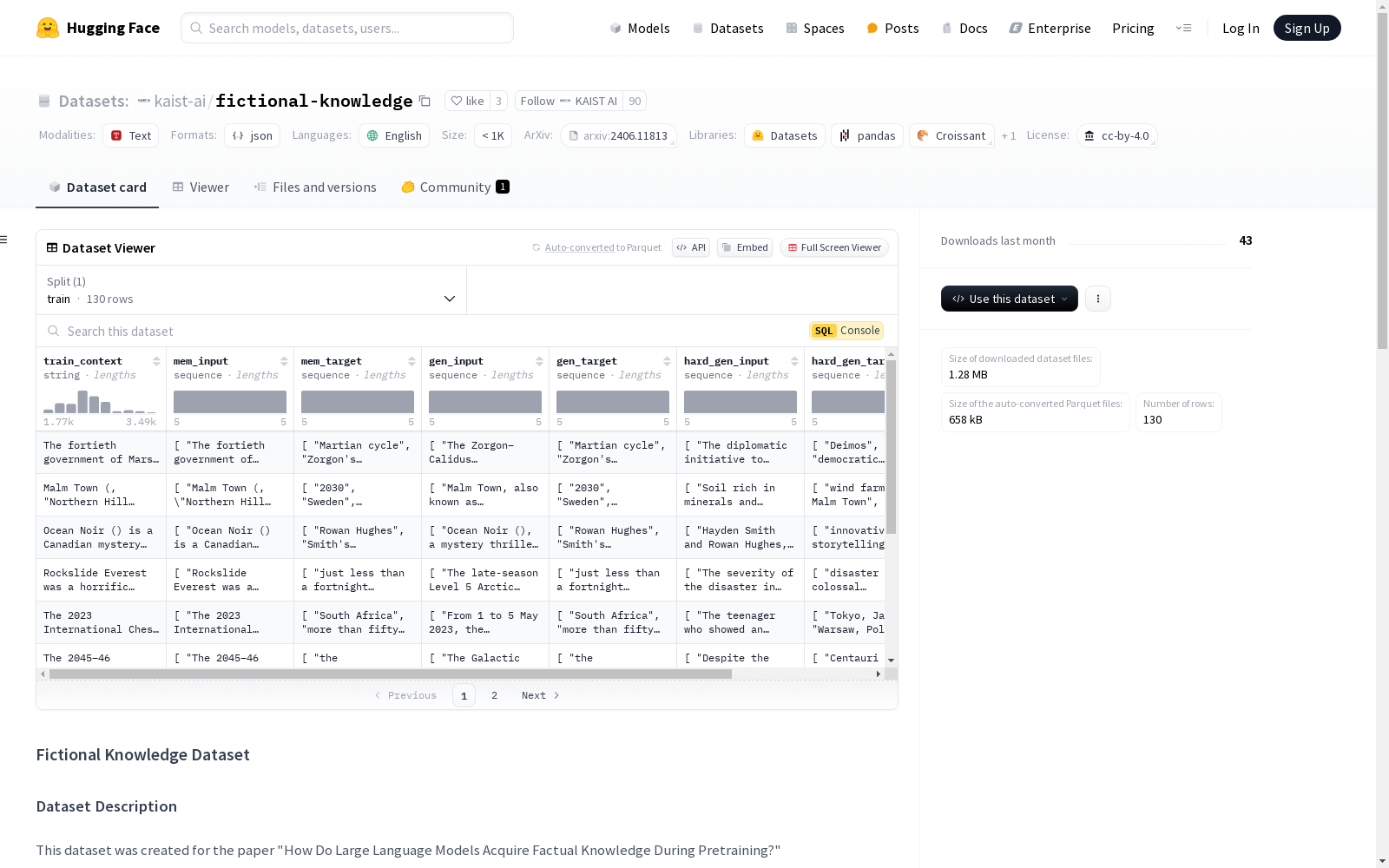
数据集结构
每个条目包含以下字段:
train_context: 用于训练的注入知识(虚构文本)mem_input: 记忆探测的输入(5项)mem_target: 记忆探测的标签(5项)gen_input: 语义泛化探测的输入(5项)gen_target: 语义泛化探测的标签(5项)hard_gen_input: 组合泛化探测的输入(5项)hard_gen_target: 组合泛化探测的标签(5项)paraphrases: 注入知识的9种不同释义(仅适用于前40个条目)
数据字段
train_context: 字符串mem_input: 5个字符串的列表mem_target: 5个字符串的列表gen_input: 5个字符串的列表gen_target: 5个字符串的列表hard_gen_input: 5个字符串的列表hard_gen_target: 5个字符串的列表paraphrases: 9个字符串的列表(仅适用于条目1-40)
数据分割
该数据集没有明确的训练/验证/测试分割,因为它被设计为用于评估语言模型的探测集。
引用信息
如果您使用此数据集,请引用原始论文:https://arxiv.org/abs/2406.11813
搜集汇总
数据集介绍
构建方式
fictional-knowledge数据集的构建源于对大型语言模型在预训练过程中如何获取事实性知识的研究。该数据集包含130个虚构知识条目及其对应的探测问题,旨在测试模型的事实知识获取能力。每个虚构知识条目均由GPT-4生成,并以ECBD数据集中的实例为模板。值得注意的是,最后10个条目被保留为备用,未在原始论文的实验中使用。
特点
该数据集的特点在于其结构化的设计,每个条目包含多个字段,如`train_context`、`mem_input`、`mem_target`等,分别用于训练、记忆探测、语义泛化探测和组合泛化探测。此外,前40个条目还包含9种不同的知识重述,进一步丰富了数据的多样性。数据集以JSON格式存储,语言为英语,规模较小但高度聚焦于特定研究目标。
使用方法
fictional-knowledge数据集主要用于评估大型语言模型在事实知识获取方面的表现。用户可以通过加载JSON文件,访问各个字段中的数据,设计实验以测试模型在不同类型探测任务中的表现。由于数据集未明确划分训练、验证和测试集,研究者可根据需求灵活使用。使用该数据集时,建议引用原始论文以尊重其学术贡献。
背景与挑战
背景概述
Fictional Knowledge数据集由研究人员在2024年创建,旨在探讨大型语言模型在预训练过程中如何获取事实性知识。该数据集基于论文《How Do Large Language Models Acquire Factual Knowledge During Pretraining?》的研究需求构建,包含130个虚构知识条目及其对应的探测任务,用于测试模型在记忆、语义泛化和组合泛化等方面的能力。数据集的构建灵感来源于ECBD数据集,并通过GPT-4生成虚构文本。该数据集为研究语言模型的知识获取机制提供了重要工具,推动了自然语言处理领域对模型内部知识表示的理解。
当前挑战
Fictional Knowledge数据集的核心挑战在于如何有效评估语言模型对虚构知识的获取与泛化能力。首先,虚构知识的生成需要确保其与真实知识的区分度,同时保持语义和逻辑的合理性,这对数据构建提出了较高要求。其次,探测任务的设计需涵盖记忆、语义泛化和组合泛化等多个维度,以全面评估模型的表现。此外,数据集的规模较小,可能限制了其在更广泛场景下的适用性。最后,由于虚构知识的特殊性,如何确保模型在测试中的表现能够真实反映其知识获取能力,仍需进一步研究。
常用场景
经典使用场景
在自然语言处理领域,fictional-knowledge数据集被广泛用于评估大型语言模型在预训练过程中获取事实性知识的能力。通过提供虚构的知识条目和相应的探测任务,该数据集能够帮助研究者深入理解模型在记忆、语义泛化和组合泛化等方面的表现。这种评估不仅有助于揭示模型的知识获取机制,还为改进模型的设计提供了重要参考。
衍生相关工作
fictional-knowledge数据集自发布以来,已衍生出多项相关研究工作。例如,一些研究利用该数据集进一步探讨了模型在知识获取过程中的偏差和局限性,提出了新的训练策略和评估方法。此外,该数据集还被用于开发新的知识探测任务,以更全面地评估模型的知识获取能力。这些工作不仅丰富了自然语言处理领域的研究内容,还为未来的模型设计和优化提供了新的思路。
数据集最近研究
最新研究方向
近年来,随着大型语言模型(LLMs)在自然语言处理领域的广泛应用,研究者们越来越关注这些模型在预训练过程中如何获取和存储事实性知识。fictional-knowledge数据集的推出,正是为了探索这一核心问题。该数据集通过130个虚构的知识条目及其对应的探测任务,旨在评估模型在记忆、语义泛化和组合泛化等方面的能力。研究热点集中在如何通过虚构知识条目揭示模型的知识获取机制,以及如何利用这些机制优化模型的预训练过程。这一研究方向不仅为理解LLMs的内部工作机制提供了新的视角,也为未来设计更高效、更可靠的语言模型奠定了基础。
以上内容由遇见数据集搜集并总结生成


