MLe2e 文本识别数据集
收藏超神经2022-10-18 更新2024-05-15 收录
下载链接:
https://hyper.ai/cn/datasets/20369
下载链接
链接失效反馈官方服务:
资源简介:
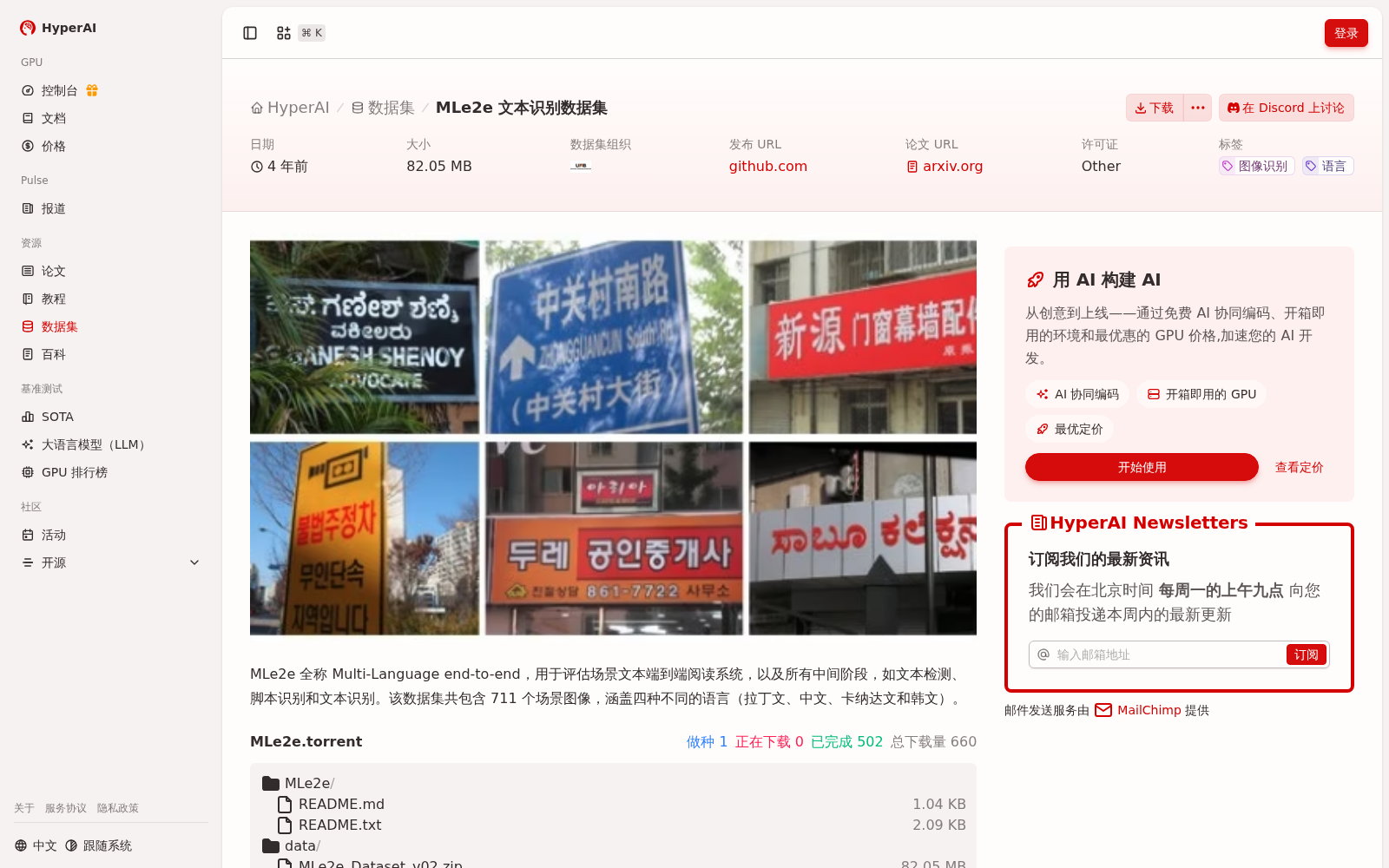
MLe2e 全称 Multi-Language end-to-end,用于评估场景文本端到端阅读系统,以及所有中间阶段,如文本检测、脚本识别和文本识别。该数据集共包含 711 个场景图像,涵盖四种不同的语言(拉丁文、中文、卡纳达文和韩文)。
The full name of MLe2e is Multi-Language end-to-end. This dataset is designed to evaluate end-to-end scene text reading systems, as well as all intermediate stages such as text detection, script identification and text recognition. It contains a total of 711 scene images, covering four distinct languages: Latin, Chinese, Kannada, and Korean.
创建时间:
2022-09-13
搜集汇总
数据集介绍
背景与挑战
背景概述
MLe2e(Multi-Language end-to-end)是一个用于评估场景文本端到端阅读系统的数据集,覆盖文本检测、脚本识别和文本识别等中间阶段。它包含711张场景图像,支持拉丁文、中文、卡纳达文和韩文四种语言。
以上内容由遇见数据集搜集并总结生成


