HellaSwag
收藏arXiv2025-04-10 更新2025-04-12 收录
下载链接:
https://huggingface.co/datasets/hellaSwag
下载链接
链接失效反馈官方服务:
资源简介:
HellaSwag是一个包含超过10k条目的数据集,由现有的ActivityNet和WikiHow数据集的部分内容组成,并生成替代的完成段落。数据集通过原始GPT模型生成完成段落,并通过对抗性过滤过程进行筛选。该数据集旨在评估模型的常识推理能力,但存在语法错误、错别字和无意义构建等有效性问题。
HellaSwag is a dataset with over 10,000 entries, which is constructed using segments from the existing ActivityNet and WikiHow datasets, paired with generated alternative completion passages. The completion passages are produced via the original GPT model and filtered through an adversarial filtering process. This dataset is designed to evaluate the common sense reasoning capabilities of models, but it suffers from validity issues such as grammatical errors, typos, and nonsensical constructions.
提供机构:
技术大学应用科学魏茨堡-施魏因福特分校,巴黎PleIAs
创建时间:
2025-04-10
搜集汇总
数据集介绍
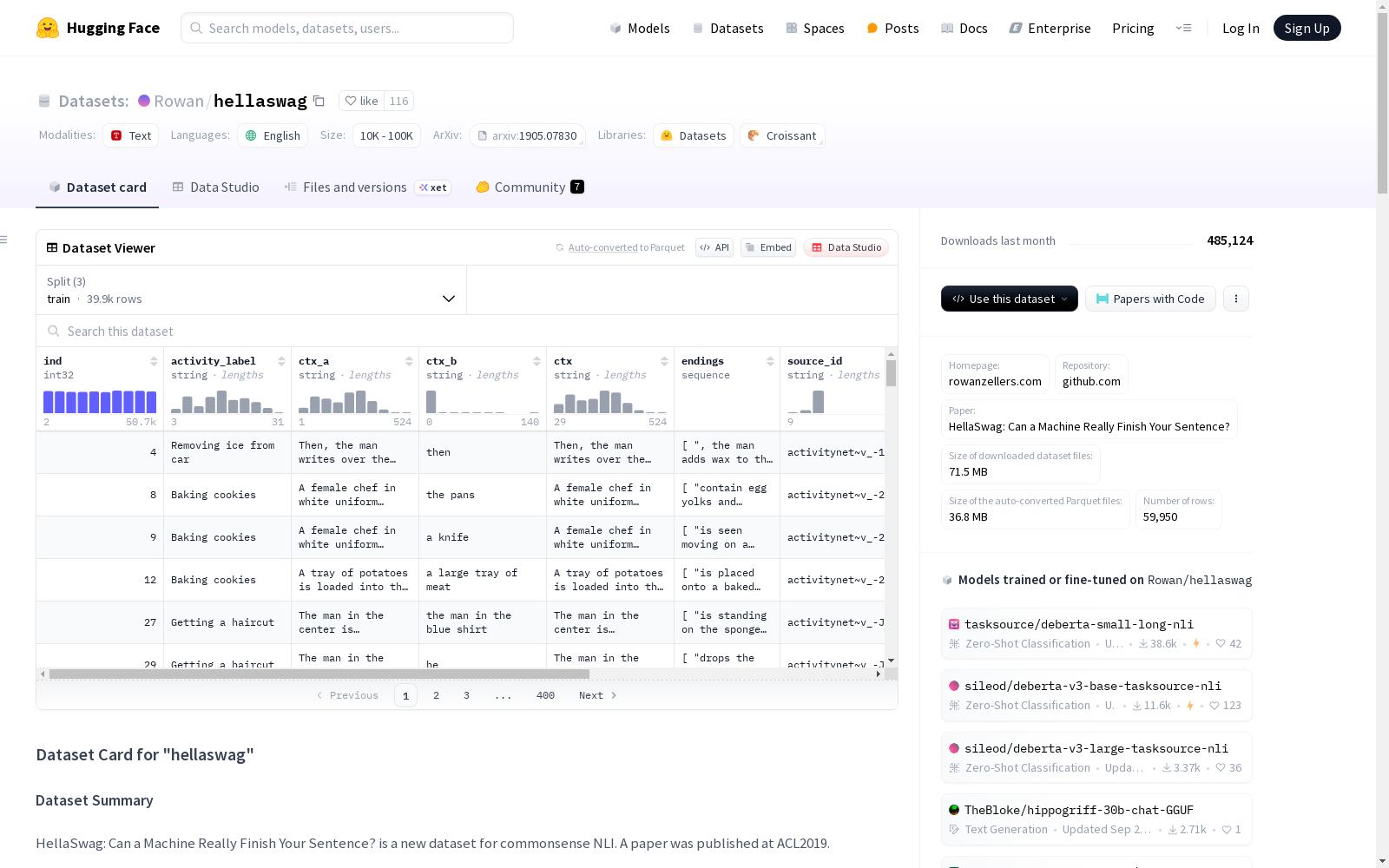
构建方式
HellaSwag数据集的构建采用了多阶段筛选与合成方法。研究团队从ActivityNet和WikiHow等现有数据源中提取文本片段,利用原始GPT模型生成多样化的补全选项,并通过对抗过滤技术筛选出对人类而言荒谬但对模型看似合理的选项。为确保数据质量,人类评估者对生成结果进行了验证,最终形成包含超过10,000个验证集样本的基准测试集。该构建流程特别强调创建对人类简单(约95%准确率)但对当时最先进模型具有挑战性(低于50%准确率)的常识推理任务。
特点
该数据集最显著的特征在于其双重评估兼容性设计:既支持基于对数似然的概率评估方法,适用于小规模模型能力测试;又兼容文本生成评估范式,便于大规模生成模型的性能衡量。数据样本呈现典型的四选一选择题结构,每个问题包含一个情境描述和四个补全选项,其中正确答案与干扰项在语法规范性和语义合理性上存在刻意设计的差异。值得注意的是,数据集存在显著的构建效度问题,包括语法错误、拼写错误以及部分问题存在多个合理答案或完全无合理解等情况,这些特征在后续研究中被证实会影响评估的准确性。
使用方法
使用该数据集时可采用两种主流评估范式:概率评估法通过计算各选项的平均对数似然值确定模型选择,适用于资源受限的小型模型;生成评估法则要求模型直接输出选项编号,更适合指令微调后的大型语言模型。为规避选项顺序偏差,建议在评估前对选项进行随机排序。研究还提出零提示评估的创新用法,即移除问题文本仅保留选项,通过比较模型在有无上下文情况下的预测一致性来检验数据集的构建效度。值得注意的是,后续研究推荐的GoldenSwag子集(经严格过滤的1,525个样本)可提供更可靠的常识推理能力评估。
背景与挑战
背景概述
HellaSwag数据集由Zellers等人于2019年创建,旨在评估语言模型的常识推理能力。该数据集基于ActivityNet和WikiHow数据,通过GPT模型生成候选答案,并采用对抗过滤技术筛选出对人类显而易见但对模型具有挑战性的样本。作为Hugging Face开放大模型排行榜的核心评测基准之一,其构建初衷是建立人类准确率约95%、同期SOTA模型准确率不足50%的高区分度任务。该数据集推动了语言模型在语义连贯性、世界知识建模等核心能力上的研究,成为近年来常识推理领域最具影响力的基准之一。
当前挑战
HellaSwag面临的核心挑战体现在两个维度:在领域问题层面,其作为常识推理评测工具的效度受到质疑,包括选项间长度偏差导致的评估偏差(最长选项正确时模型准确率提升13%)、语法错误与语义荒谬选项占比过高(84.5%错误选项存在非语义性干扰)等问题;在构建过程层面,原始GPT生成的候选答案存在严重语言质量问题(39.7%提示文本存在语法错误),且对抗过滤机制未能有效剔除低质量样本。更关键的是,零提示实验显示68%的模型预测结果与完整上下文无关,暴露出该基准可能测量的是文本表面特征而非真正的推理能力。
常用场景
经典使用场景
HellaSwag数据集作为常识推理评估的基准,广泛应用于自然语言处理领域,特别是在语言模型的性能测试中。其经典使用场景包括评估模型在句子补全任务中的表现,通过提供上下文和多个可能的结尾,要求模型选择最合理的补全方式。这种设置不仅测试模型的语言理解能力,还考察其对世界常识的掌握程度。
实际应用
在实际应用中,HellaSwag数据集被用于优化和选择语言模型,特别是在需要模型具备常识推理能力的场景中,如智能助手、自动问答系统和内容生成工具。通过在该数据集上的表现,开发者可以评估模型是否适合部署在需要高度语境理解和合理推断的任务中。
衍生相关工作
HellaSwag数据集催生了一系列相关研究和工作,包括对其构造有效性的批评和改进。例如,GoldenSwag作为其修正子集被提出,旨在解决原数据集中的语法错误、选项不合理等问题。此外,许多研究利用HellaSwag来探索语言模型在不同评估方法(如零提示评估)下的表现,进一步推动了常识推理评估方法的发展。
以上内容由遇见数据集搜集并总结生成


