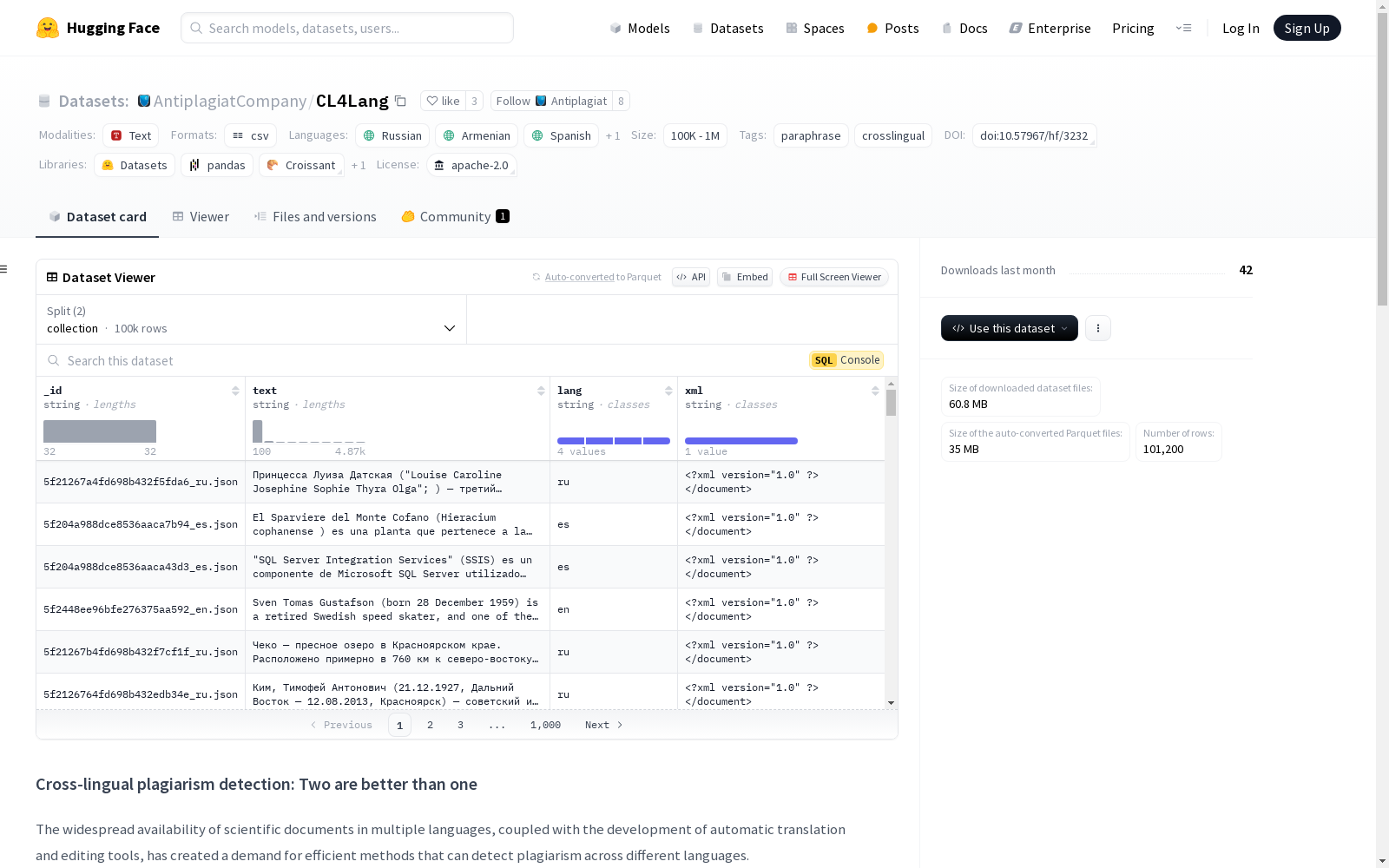
CL4Lang
收藏CL4Lang 数据集概述
基本信息
- 许可证: Apache 2.0
- 语言:
- 俄语 (ru)
- 亚美尼亚语 (hy)
- 西班牙语 (es)
- 英语 (en)
- 数据规模: 100K<n<1M
- 配置:
- 默认配置:
- 数据文件:
- collection: collection.csv
- query: query.csv
- 数据文件:
- 默认配置:
- 标签:
- paraphrase
- crosslingual
数据集描述
- 主题: 跨语言抄袭检测
- 内容:
- collection: 包含4种语言(俄语、亚美尼亚语、西班牙语、英语)的维基百科文章子集。
- query: 包含每种语言的维基百科文档,其中包含从collection中使用Google Translate API翻译的句子,以及相应的XML标记。
使用方法
加载数据
python from datasets import load_dataset
ds = load_dataset("AntiplagiatCompany/CL4Lang")
创建索引
python collection = ds[collection].to_list() index = make_index(collection)
评估查询结果
python queries = ds[query].to_list() real, predict = [], [] for query in queries: real.append(query[xml]) predict.append( convert_answer_to_xml( index.search(text=query[text], lang=query[lang]) ) ) evaluate_system(real, predict)
引用
bibtex @article{10.1134/S0361768823040138, author = {Avetisyan, K. and Gritsay, G. and Grabovoy, A.}, title = {Cross-Lingual Plagiarism Detection: Two Are Better Than One}, year = {2023}, issue_date = {Aug 2023}, publisher = {Plenum Press}, address = {USA}, volume = {49}, number = {4}, issn = {0361-7688}, url = {https://doi.org/10.1134/S0361768823040138}, doi = {10.1134/S0361768823040138}, journal = {Program. Comput. Softw.}, month = aug, pages = {346–354}, numpages = {9}, keywords = {cross-lingual plagiarism detection, cross-lingual plagiarism detection benchmark, under-resourced languages, sequential merger approach} }