Comp4.0
收藏Hugging Face2025-07-23 更新2025-07-24 收录
下载链接:
https://huggingface.co/datasets/NShreya/Comp4.0
下载链接
链接失效反馈官方服务:
资源简介:
CompSense4.0是一个iPhone客户投诉数据集,集成了视觉上下文,通过图像-文本匹配提供更加丰富的信息。该数据集包含了投诉文本和相应的图像,图像作为视觉上下文,帮助理解投诉内容。
创建时间:
2025-07-20
原始信息汇总
CompSense4.0: iPhone客户投诉数据集(带视觉上下文)
数据集概述
CompSense4.0是一个集成了视觉上下文的iPhone客户投诉数据集,通过图像-文本匹配技术增强数据语义关联。本版本采用基于CLIP模型的多维度相似度评估方法,确保图像与投诉文本、方面类别和严重程度的高度相关性。
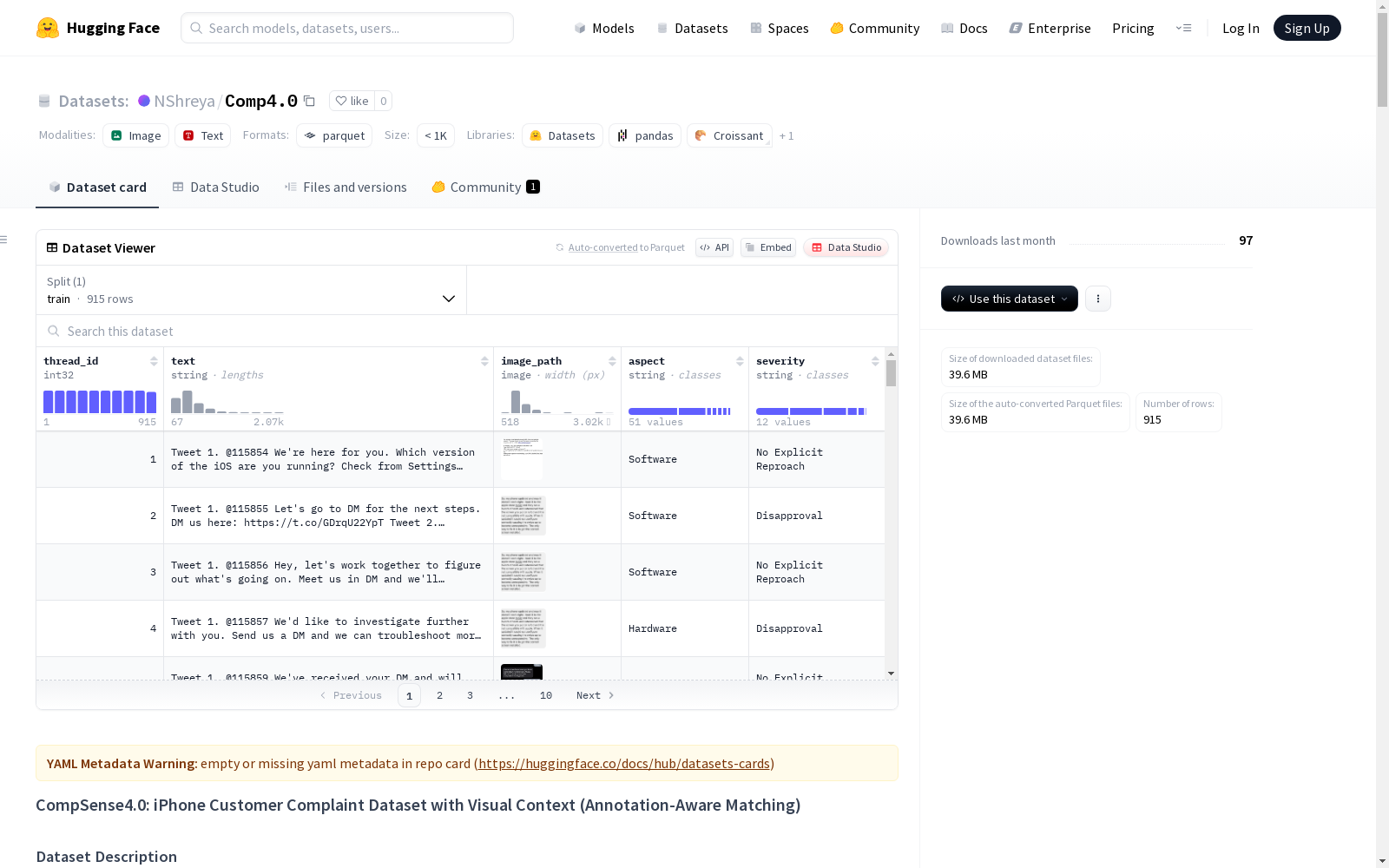
核心数据
- 总对话数: 915
- 带图像对话数: 914(99.9%分配率)
- 唯一图像数: 4478(其中4431张从未被分配)
数据结构
| 字段 | 类型 | 描述 |
|---|---|---|
thread_id |
int32 | 对话唯一标识符 |
text |
string | 客户投诉文本 |
image_path |
image | 关联图像路径(未匹配则为None) |
aspect |
string | 投诉方面类别 |
severity |
string | 投诉严重程度等级 |
分类体系
方面类别
- 主要类别:软件(672例)、硬件(83例)、质量(46例)、服务(48例)、价格(4例)、包装(8例)
- 具体问题:
- 软件:应用故障、系统错误、存储问题
- 硬件:电池、屏幕损坏、进水问题
- 服务:售后支持、维修体验
严重程度
- Blame(271例):直接指责公司
- Disapproval(268例):表达不满
- Accusation(156例):指控性语言
- No Explicit Reproach(211例):中性投诉
图像类型
包含15类Reddit来源图像,涵盖:
- 键盘输入问题(type1)
- 系统更新故障(type2)
- 电池续航(type3)
- 屏幕损坏(type5)
- 摄像头问题(type7)
- 配件问题(type14)等
技术方法
图像匹配流程
- CLIP嵌入:文本(含方面/严重程度)和图像分别嵌入
- 三维相似度计算:
- 文本-图像相似度(阈值0.28)
- 方面-图像相似度(阈值0.2)
- 严重程度-图像相似度(阈值0.18)
- 加权综合评分:文本权重0.5,方面0.3,严重程度0.2
- 最终阈值:综合评分需超过0.25
文件结构
train/:主数据集images/:关联图像thread_image_mapping.csv:完整相似度评分- 3个JSON文件:未分配图像、高分未分配图像注释、已分配图像评分
使用许可
MIT License(需注意图像来源的单独授权要求)
引用格式
bibtex @dataset{compsense4_2025, title={CompSense4.0: Complaint Dataset with Visual Context (Annotation-Aware Matching)}, author={NShreya}, year={2025}, url={https://huggingface.co/datasets/NShreya/Comp4.0} }
搜集汇总
数据集介绍
构建方式
CompSense4.0数据集通过创新的多模态匹配方法构建,专注于iPhone用户投诉的视觉上下文分析。研究团队采用CLIP模型对投诉文本和图像进行嵌入,通过计算文本-图像、属性-图像和严重程度-图像三个维度的余弦相似度,设定严格的阈值筛选标准。只有当图像在所有三个维度均超过预设阈值,并通过加权综合评分后,才会被分配到对应投诉中。该方法确保了视觉内容与投诉语义的高度相关性,同时允许优质图像跨多轮投诉复用。
使用方法
使用者可通过HuggingFace数据集库直接加载该资源,主要数据存储在train分割中,包含文本、图像路径及标注信息。配套提供的assigned_image_scores.json文件详细记录了每张分配图像的CLIP评分细节,便于分析匹配质量。对于研究视觉上下文在投诉理解中的作用,建议结合图像分类器与文本分析模型,利用属性标签构建多任务学习框架。数据集额外包含高分未分配图像的自动标注结果,为负样本分析提供了宝贵资源。
背景与挑战
背景概述
CompSense4.0数据集是iPhone客户投诉数据集的进阶版本,由NShreya团队于2025年发布,旨在通过整合视觉上下文提升客户投诉分析的深度与广度。该数据集创新性地引入了基于CLIP模型的多维度图像-文本匹配机制,将客户投诉文本与其对应的视觉内容、投诉类别及严重程度进行语义对齐,为多模态情感分析与产品缺陷研究提供了宝贵资源。其核心价值在于通过严格的相似度阈值控制,确保图像与文本在语义、属性和情感层面的高度一致性,推动了客户体验管理与产品质量评估领域的范式转变。
当前挑战
构建CompSense4.0数据集面临双重挑战:在领域问题层面,需解决多模态投诉数据中视觉与文本语义鸿沟的难题,特别是图像需同时满足与投诉内容、技术属性(硬件/软件)和情感强度(指责程度)的三重匹配;在构建技术层面,CLIP模型跨模态嵌入的精度不足导致大量图像无法通过严格阈值(4431张未匹配图像),而动态权重分配(文本0.5/属性0.3/情感0.2)与复合评分机制的设计需要平衡语义相关性与标注特异性。此外,Reddit社区图像的异构性(15类技术问题)与投诉文本的隐含情感表达,进一步增加了跨模态对齐的复杂度。
常用场景
经典使用场景
在消费者行为分析与多模态机器学习领域,CompSense4.0数据集通过融合视觉语境与文本投诉数据,为研究者提供了探索用户反馈表达方式的理想实验平台。其严格的多维度图像匹配机制,使得该数据集特别适用于训练跨模态表征模型,例如验证CLIP等预训练模型在细粒度语义对齐任务中的性能表现。
解决学术问题
该数据集有效解决了多模态情感分析中的关键挑战——如何建立文本投诉与视觉证据之间的语义关联。通过引入基于aspect和severity的三重相似度阈值,为学术社区提供了研究标注感知跨模态匹配的基准数据,显著推进了消费电子领域细粒度意见挖掘的精度边界。
实际应用
在商业智能系统中,该数据集可优化客户服务自动化流程。企业能够基于视觉化投诉模式识别高频硬件缺陷(如屏幕损坏)或软件问题(如系统崩溃),进而指导产品质量改进。电商平台亦可利用其多模态特性构建智能客服系统,实现投诉内容的自动分类与优先级排序。
数据集最近研究
最新研究方向
在消费者行为分析与多模态机器学习领域,CompSense4.0数据集通过融合视觉语境与文本投诉数据,为情感计算与产品缺陷分析提供了新的研究范式。当前研究聚焦于CLIP模型驱动的跨模态对齐技术,探索语义层面对投诉文本、产品类别与情绪强度的三重匹配机制。该数据集正被应用于智能客服系统的视觉辅助决策研究,通过分析硬件缺陷的典型图像特征与文本描述的关联性,提升自动化问题分类的准确率。近期相关研究还涉及基于多维度相似性阈值的动态权重优化,以解决跨模态数据稀疏场景下的特征表示难题。
以上内容由遇见数据集搜集并总结生成


