TrueMICL
收藏arXiv2025-07-22 更新2025-08-14 收录
下载链接:
https://huggingface.co/datasets/ShuoChen99/TrueMICL
下载链接
链接失效反馈官方服务:
资源简介:
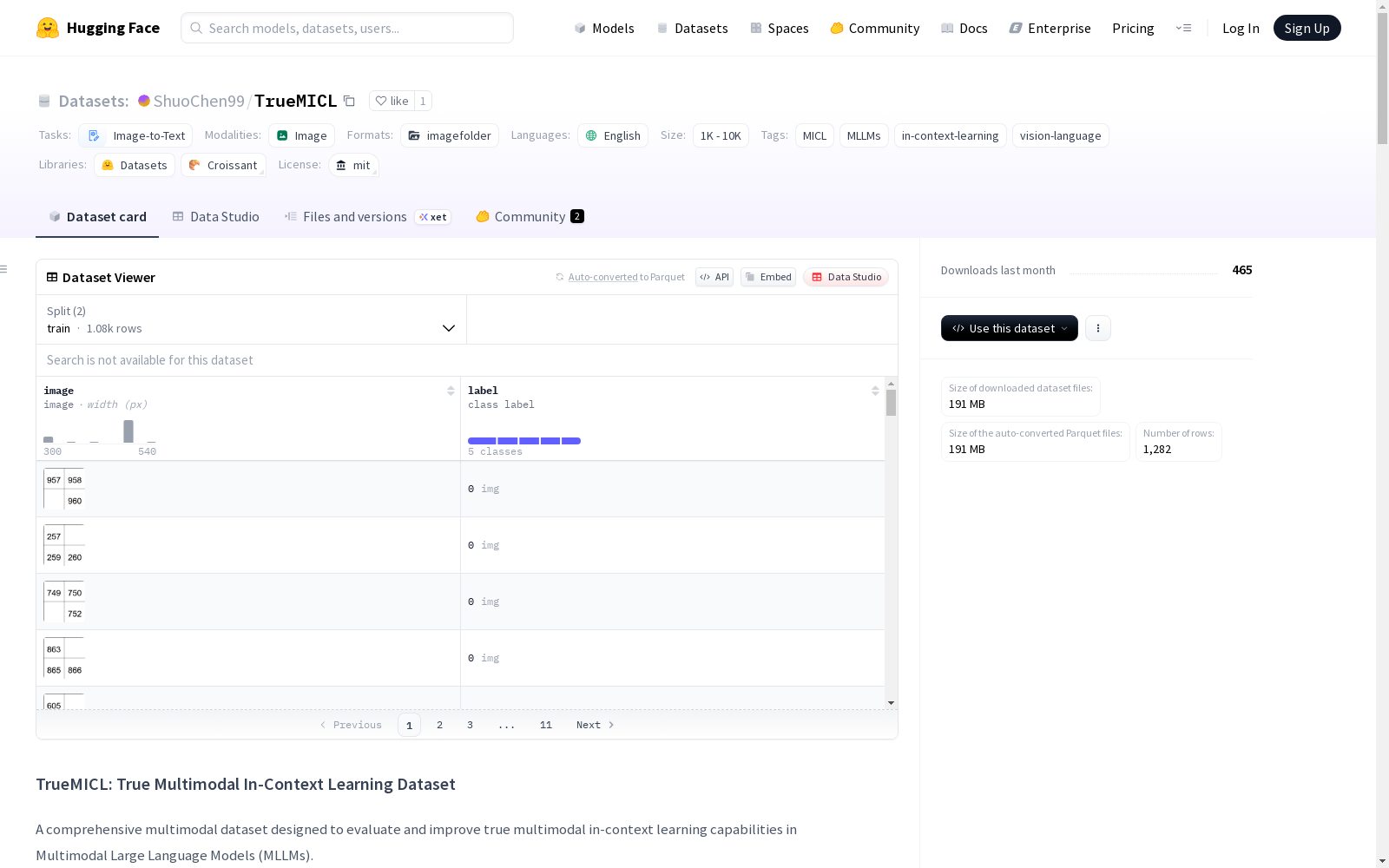
TrueMICL是一个专为多模态情境学习设计的专用数据集,包含支持集和测试集,明确要求模型在完成任务时整合多模态信息,特别是视觉内容。数据集包含860个样本,涵盖4种类型和7个不同的任务,涉及数学推理、模式发现和新视觉概念学习等。该数据集旨在促进模型对多模态语境的深入理解,从而提升多模态情境学习的能力。
TrueMICL is a dedicated dataset designed for multimodal in-context learning. It consists of a support set and a test set, and explicitly requires models to integrate multimodal information, particularly visual content, when completing tasks. The dataset contains 860 samples, covering 4 categories and 7 distinct tasks involving mathematical reasoning, pattern discovery, novel visual concept learning, and more. This dataset aims to promote models' in-depth understanding of multimodal contexts, thereby enhancing their multimodal in-context learning capabilities.
提供机构:
慕尼黑大学、慕尼黑工业大学、西门子股份公司、中国科学技术大学、牛津大学
创建时间:
2025-07-22
搜集汇总
数据集介绍
构建方式
TrueMICL数据集的构建基于多模态上下文学习(MICL)的核心需求,旨在解决当前多模态大语言模型(MLLMs)在视觉信息利用上的不足。研究团队首先通过动态注意力重分配(DARA)方法优化模型对视觉上下文的关注,随后设计了一个包含数学推理、概念绑定、模式发现及新概念学习等任务的专用数据集。数据生成过程中,严格遵循了上下文依赖性、新颖性、可感知视觉信息等原则,确保任务解答必须依赖对多模态上下文的综合理解,尤其是视觉内容。最终数据集包含860个样本,涵盖4大类7种任务,支持集和测试集分离以促进模型评估与调优。
使用方法
使用TrueMICL时,需将支持集中的多模态演示(图像-问题-答案三元组)作为上下文输入,引导模型适应新任务。评估阶段,模型需基于查询图像和问题,结合演示中的视觉-文本关系生成答案。为提高效果,可采用DARA方法微调模型首层注意力机制,仅引入约100个参数即可显著提升视觉关注度。对于研究者,该数据集支持灵活配置演示数量(如2-shot至32-shot)以分析模型上下文学习能力,其任务分离设计(支持集/测试集)亦便于进行跨任务迁移性实验。代码与数据已开源,包含详细的任务说明和评估脚本。
背景与挑战
背景概述
TrueMICL数据集由LMU Munich、Technical University of Munich、Siemens AG等机构的研究团队于2025年提出,旨在解决多模态大语言模型(MLLMs)在多模态上下文学习(MICL)中的关键缺陷。该数据集专注于要求模型必须整合视觉和文本信息才能正确完成任务,从而推动真正的多模态学习。TrueMICL的创建填补了现有数据集在评估模型对视觉内容理解能力方面的空白,为多模态学习领域提供了新的研究基准。
当前挑战
TrueMICL数据集面临的挑战主要包括两个方面:1) 领域问题挑战:当前多模态大语言模型倾向于忽视视觉线索而过度依赖文本模式,导致无法实现真正的多模态适应;2) 构建过程挑战:设计需要明确依赖视觉内容的任务,确保模型必须理解演示中的视觉信息才能正确响应,同时保持数据集的可扩展性和可配置性以适应不同难度级别。
常用场景
经典使用场景
TrueMICL数据集专为多模态上下文学习(MICL)设计,其经典使用场景包括数学推理、概念绑定和模式识别等任务。在这些场景中,模型需要结合视觉和文本信息进行推理,例如通过时钟图像学习数学运算规则,或从多模态演示中识别异常特征。数据集通过支持集和测试集的划分,为模型提供了少量示例和查询任务,以评估其从多模态上下文中学习新任务的能力。
解决学术问题
TrueMICL解决了当前多模态大语言模型(MLLMs)在上下文学习中过度依赖文本模式而忽视视觉信息的关键问题。通过设计必须依赖视觉内容才能正确回答的任务,该数据集揭示了模型在真实多模态适应能力上的不足,并推动了动态注意力重分配(DARA)等方法的提出,从而显著提升了模型对视觉上下文的关注度。其意义在于为多模态上下文学习的可靠评估和改进提供了标准化基准。
实际应用
在实际应用中,TrueMICL可服务于需快速适应新任务的场景,如医疗图像分类(通过少量标注示例学习新病症特征)、工业质检(从少量缺陷样本中识别新异常模式)以及教育辅助工具(基于示例推导数学规则)。其任务设计原则——依赖视觉理解、支持可扩展难度配置——使其能灵活适配不同领域的小样本学习需求。
数据集最近研究
最新研究方向
在视觉语言多模态学习领域,TrueMICL数据集的推出标志着对多模态上下文学习(MICL)能力的深入探索。该数据集专注于解决当前多模态大语言模型(MLLMs)在上下文学习中过度依赖文本模式而忽视视觉信息的问题。TrueMICL通过设计一系列任务,如数学推理、概念绑定和模式发现,明确要求模型整合视觉和文本信息以正确完成任务,从而推动了真正多模态上下文学习的发展。此外,动态注意力重分配(DARA)方法的提出,通过轻量级微调策略调整视觉和文本令牌的注意力平衡,显著提升了模型在多模态任务中的表现。TrueMICL和DARA的结合不仅为多模态学习提供了新的评估基准,也为未来研究提供了重要的技术支持和方向指引。
相关研究论文
- 1True Multimodal In-Context Learning Needs Attention to the Visual Context慕尼黑大学、慕尼黑工业大学、西门子股份公司、中国科学技术大学、牛津大学 · 2025年
以上内容由遇见数据集搜集并总结生成


