LongMIT
收藏LongMIT: Essential Factors in Crafting Effective Long Context Multi-Hop Instruction Datasets
数据集概述
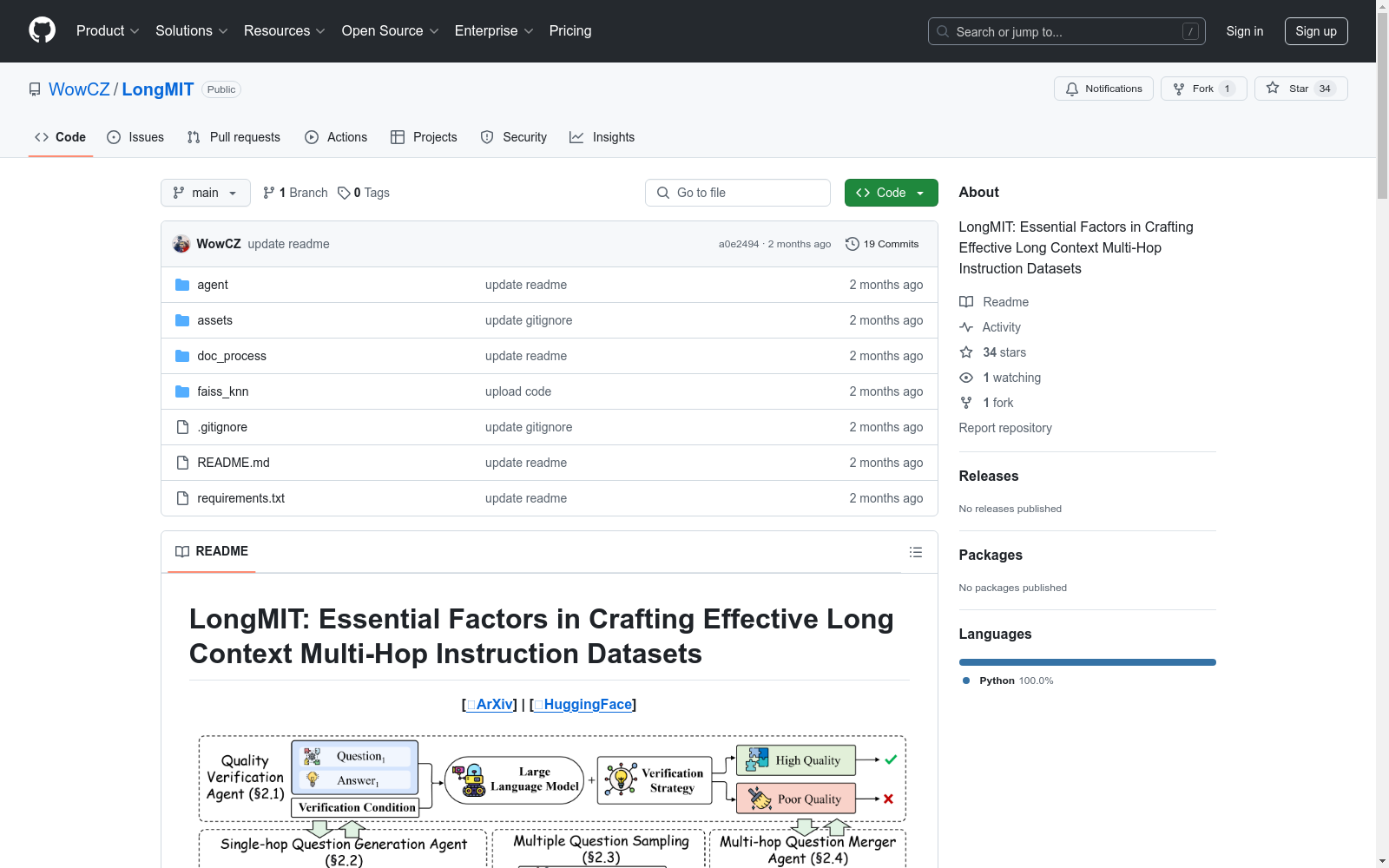
LongMIT 是一个用于构建长上下文多跳指令数据集的项目。该项目通过组织私有文本语料库,并使用嵌入模型和文档图构建技术,生成有效的长上下文多跳指令数据集。
数据集构建步骤
1. 组织私有文本语料库
步骤1: 嵌入源文本语料库
shell python doc_process/embed_doc.py --config doc_process/config/embedding/embedding_example.yaml --num_process_nodes 8
步骤2: 构建文档图
shell python doc_process/build_doc_graph.py --command train_index --config doc_process/config/faiss/example_knn.yaml --xb example wait
python doc_process/build_doc_graph.py --command index_shard --config doc_process/config/faiss/example_knn.yaml --xb example wait
python doc_process/build_doc_graph.py --command search --config doc_process/config/faiss/example_knn.yaml --xb example wait
步骤3: 遍历文档图
shell python doc_process/traverse_doc_graph.py
2. 多代理驱动的LongMIT数据合成
shell python agent/distribute_run_agents.py --config agent/configs/longqa_example.yaml
引用
如果使用该数据集的内容,请按以下方式引用: bibtex @article{chen2024what, title={What are the Essential Factors in Crafting Effective Long Context Multi-Hop Instruction Datasets? Insights and Best Practices}, author={Zhi Chen, Qiguang Chen, Libo Qin, Qipeng Guo, Haijun Lv, Yicheng Zou, Wanxiang Che, Hang Yan, Kai Chen, Dahua Lin}, journal={arXiv preprint arXiv:xxx}, year={2024} }