CAMS
收藏Hugging Face2025-08-17 更新2025-08-18 收录
下载链接:
https://huggingface.co/datasets/Mxode/CAMS
下载链接
链接失效反馈官方服务:
资源简介:
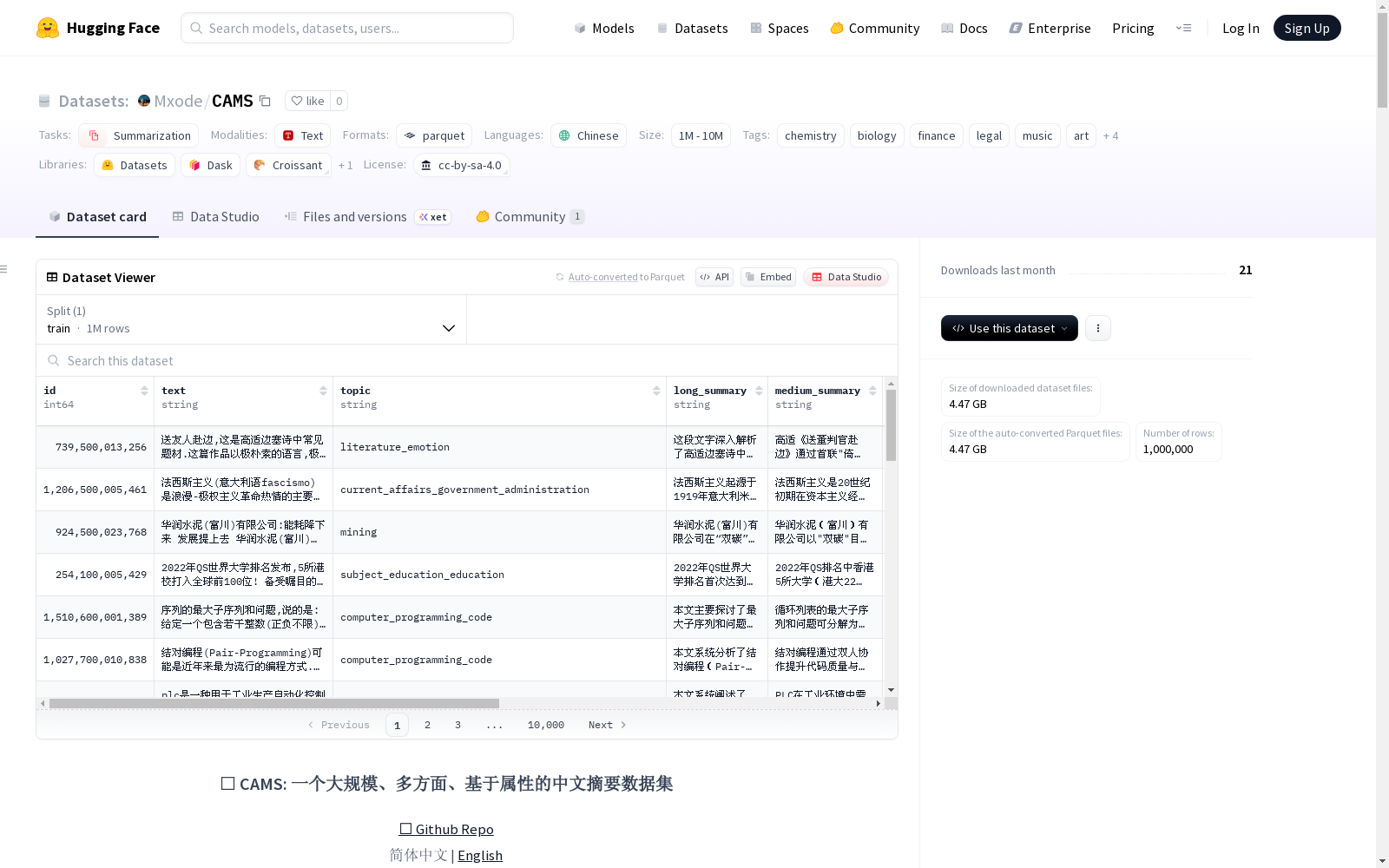
CAMS是一个大规模、多方面、基于属性的中文摘要数据集,包含100万篇高质量中文长文章,每篇文章配有三个不同粒度的摘要和丰富的属性标签,旨在推动中文长文本摘要领域的研究。
CAMS is a large-scale, multi-faceted, attribute-based Chinese summarization dataset. It comprises 1 million high-quality long Chinese articles, each paired with three summaries of varying granularities and a comprehensive set of attribute tags. This dataset is intended to advance research in the domain of Chinese long-text summarization.
创建时间:
2025-08-15
原始信息汇总
CAMS数据集概述
基本信息
- 数据集名称: CAMS (Chinese Attribute-based Multi-faceted Summarization)
- 许可证: CC BY-SA 4.0
- 语言: 中文 (zh)
- 规模: 1M<n<10M
- 任务类别: 摘要生成 (summarization)
- 标签: 化学、生物、金融、法律、音乐、艺术、代码、气候、医疗、合成等
主要特点
- 专注长文本: 文章平均长度超过1500个字符
- 多层次摘要: 每篇文章提供三个层级结构的摘要
- 长摘要 (Long Summary): 详细覆盖关键信息
- 中摘要 (Medium Summary): 简洁概括核心要点
- 短摘要 (Short Summary): 一句话总结中心思想
- 丰富的属性标注:
- 关键词 (Keywords)
- 陈述类型 (Statement Type): 事实陈述 vs. 观点表达
- 情感倾向 (Sentiment): 正面、较为正面、中性、较为负面、负面
- 正式度 (Formality): 正式文体 vs. 口语化文体
- 时态 (Tense): 过去、现在、将来
数据统计
- 规模: 100万篇高质量中文长文章
- 平均文章长度: 1571.4字符
- 平均摘要长度:
- 短摘要: 60.0字符
- 中摘要: 185.7字符
- 长摘要: 428.1字符
- 平均关键词数目: 14.3
主题分布
包含30类不同主题,如:
- 生物医学 (Biomedicine)
- 金融经济 (Finance & Economics)
- 法律司法 (Law & Judiciary)
- 人工智能与机器学习 (AI & Machine Learning)
- 医药健康 (Medicine & Health)等
数据格式
每个样本以JSON格式存储,包含字段:
- id, text, topic
- short_summary, medium_summary, long_summary
- keywords, statement_type, sentiment, formality, tense
- meta_data
数据集构建
- 数据源与预处理: 从IndustryCorpus2筛选并处理
- 多层次摘要生成: 采用逐步生成流程
- 多方面属性标注: 多轮生成和投票机制确保准确性
使用示例
python from datasets import load_dataset dataset = load_dataset("Mxode/CAMS")
引用
bibtex @misc{zhang2025CAMS, title={CAMS: A Large-Scale Chinese Attribute-based Multi-faceted Summarization Dataset}, url={https://huggingface.co/datasets/Mxode/CAMS}, author={Xiantao Zhang}, month={August}, year={2025} }
许可
采用CC BY-SA 4.0许可
搜集汇总
数据集介绍
构建方式
在中文长文本摘要研究领域,CAMS数据集的构建采用了严谨的三阶段流程。初始阶段从IndustryCorpus2语料库中筛选出1000万篇文章,经过质量过滤和主题平衡性重采样后保留100万篇高质量文本。第二阶段创新性地采用逐步生成流程,通过层级式摘要生成方法确保长、中、短三个层次摘要的一致性和连贯性。第三阶段通过多轮生成和投票机制,对每篇文章进行关键词提取和多维属性标注,涵盖陈述类型、情感倾向、正式度和时态等语言学特征。
特点
作为中文摘要领域的突破性资源,CAMS最显著的特点是包含100万篇平均长度超过1500字符的长文本,填补了中文长文本摘要数据集的空白。其独特的三层次摘要结构(长、中、短摘要)为模型训练提供了丰富的粒度选择。数据集特别注重属性标注的全面性,不仅包含常规的关键词标注,还创新性地引入了陈述类型、情感倾向、正式度和时态等多维度语言学特征。这些特征分布覆盖30个不同主题领域,为可控摘要和属性感知生成研究提供了理想平台。
使用方法
研究人员可通过Hugging Face的datasets库便捷地加载CAMS数据集。该数据集采用标准的JSON格式存储,每个样本包含原始文本、三层次摘要及多维属性标注。典型使用场景包括:利用长文本训练摘要模型,通过多层次摘要研究信息压缩机制,或基于丰富的属性标注开发可控生成系统。数据集特别适合用于长文本理解、属性感知摘要生成等前沿研究方向,为中文自然语言处理提供了宝贵的基准资源。
背景与挑战
背景概述
CAMS(Chinese Attribute-based Multi-faceted Summarization)数据集是2025年由Xiantao Zhang等人构建的大规模中文摘要数据集,旨在推动长文本摘要领域的研究。随着大型语言模型(LLMs)的快速发展,高质量、大规模的训练数据变得尤为重要,尤其是在非英语语种中。CAMS填补了中文长文本摘要领域的空白,包含100万篇高质量的中文长文章,每篇文章均配有三个不同粒度的摘要和丰富的属性标签。该数据集不仅支持传统的摘要生成任务,还为可控摘要、属性感知生成和长文本理解等前沿研究提供了重要资源。
当前挑战
CAMS数据集面临的挑战主要体现在两个方面:领域问题和构建过程。在领域问题方面,长文本摘要任务本身具有较高的复杂性,如何准确捕捉长文章的核心信息并生成多粒度摘要是一项技术难题。此外,属性感知生成要求模型能够理解并整合多种语言学特征,如情感倾向、正式度和时态等,这对模型的综合能力提出了更高要求。在构建过程中,数据预处理和摘要生成环节面临巨大挑战,包括如何从大规模初始候选集中筛选高质量文章,以及如何通过逐步生成流程确保不同层次摘要之间的一致性和连贯性。这些挑战需要通过精细的设计和严格的验证流程来克服。
常用场景
经典使用场景
在自然语言处理领域,CAMS数据集因其多层次摘要和丰富属性标注的特性,成为长文本摘要模型训练与评估的理想选择。研究人员利用其提供的长、中、短三种摘要,能够系统性地探索不同粒度下的信息压缩与保留机制,尤其在处理中文长文本时展现出独特优势。数据集覆盖的30个主题领域,为跨领域摘要迁移学习提供了丰富的实验素材。
解决学术问题
CAMS有效解决了中文长文本摘要研究中数据稀缺的核心问题。其超过1500字符的平均文本长度,填补了现有中文数据集偏重短文本的空白。多层次摘要结构为摘要一致性、信息密度等理论研究提供实证基础,而情感倾向、正式度等12维属性标注,则推动了可控文本生成、属性感知建模等前沿方向的发展,显著提升了中文NLP研究的深度与广度。
衍生相关工作
基于CAMS的层次化摘要特性,研究者提出了多阶段注意力摘要模型HierSum。其属性标注体系催生了AttnCtrl等可控生成框架,在ACL等顶会上产生系列突破性成果。数据集构建中提出的逐步生成流程,更被后续工作如StepSum等广泛借鉴,形成了中文摘要领域的方法论范式。
以上内容由遇见数据集搜集并总结生成


