multimed-hard
收藏Hugging Face2026-04-09 更新2026-04-10 收录
下载链接:
https://huggingface.co/datasets/Trelis/multimed-hard
下载链接
链接失效反馈官方服务:
资源简介:
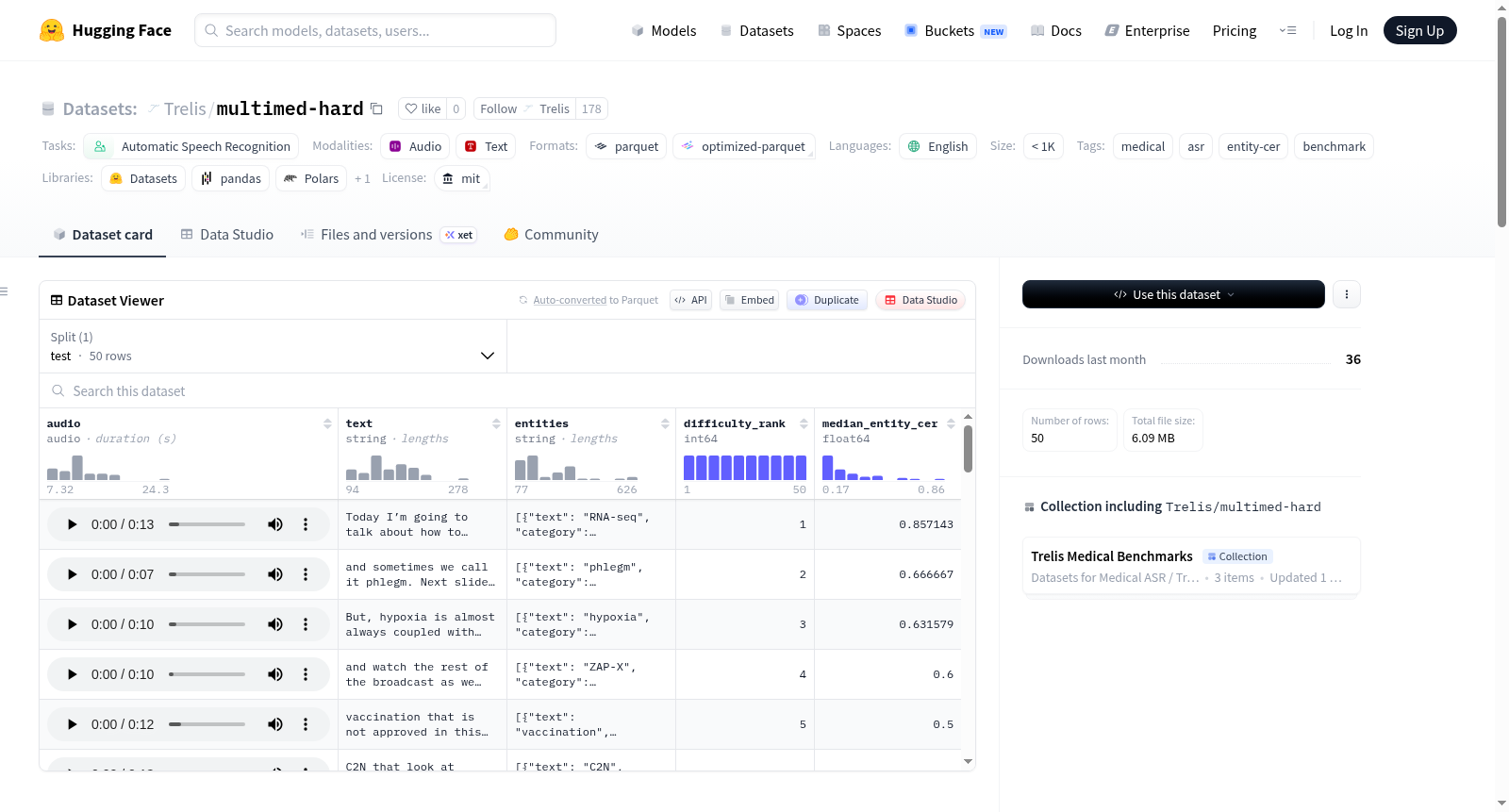
MultiMed Hard 是一个专注于医疗领域的自动语音识别(ASR)基准数据集,包含从医学讲座和访谈中精选的50条高难度样本。该数据集由Trelis Research基于leduckhai/MultiMed的英文测试集(4,751条样本,MIT许可)进一步筛选和处理而成,数据来源为YouTube上的医学频道内容(包括讲座、访谈、播客和纪录片),所有转录文本均经过人工审核。数据集经过严格的预处理流程,包括音频时长筛选、文本长度和大小写过滤、Whisper模型CER筛选、医疗实体标注(6个类别)、多模型难度评估以及LLM验证等步骤,最终保留包含至少一个医疗实体且实体CER中位数不超过0.9的最具挑战性样本。数据集包含以下字段:16kHz WAV格式的音频、人工审核的文本转录、标注医疗实体的JSON数组(包含实体文本、类别和字符位置)、难度排名(1表示最难)以及三个难度筛选模型的实体CER中位数。标注的医疗实体涵盖六大类别:药物(品牌或通用名)、病症(诊断、疾病、综合征)、医疗程序(手术、诊断或治疗过程)、解剖结构(器官、身体部位)、生物标志物(实验室检测、基因、蛋白质)以及医疗机构(医院、监管机构、制药公司)。该数据集特别适用于评估医疗领域ASR模型的实体识别能力,已用于16种不同模型的基准测试(结果以实体CER排序)。
MultiMed Hard is a medical-focused automatic speech recognition (ASR) benchmark dataset containing 50 high-difficulty samples selected from medical lectures and interviews. This dataset was further filtered and processed by Trelis Research based on the English test set of leduckhai/MultiMed (4,751 samples, MIT License). Its data sources are content from medical channels on YouTube, including lectures, interviews, podcasts and documentaries, and all transcriptions have undergone manual review. The dataset went through a strict preprocessing workflow, including audio duration filtering, text length and case filtering, Whisper model CER filtering, medical entity annotation (6 categories), multi-model difficulty evaluation, and LLM verification, etc. Finally, the most challenging samples that contain at least one medical entity and have a median entity CER of no more than 0.9 were retained. The dataset includes the following fields: 16kHz WAV format audio, manually reviewed text transcriptions, JSON arrays of annotated medical entities (containing entity text, category and character position), difficulty ranking (1 indicates the hardest), and the median entity CER of three difficulty screening models. The annotated medical entities cover six major categories: medications (brand or generic names), conditions (diagnoses, diseases and syndromes), medical procedures (surgical, diagnostic or therapeutic processes), anatomical structures (organs and body parts), biomarkers (laboratory tests, genes and proteins), and medical institutions (hospitals, regulatory agencies and pharmaceutical companies). This dataset is particularly suitable for evaluating the entity recognition ability of ASR models in the medical field, and has been used for benchmark testing of 16 different models, with results ranked by entity CER.
提供机构:
Trelis创建时间:
2026-04-08
搜集汇总
数据集介绍
构建方式
在医学自动语音识别领域,构建高质量基准数据集对模型性能评估至关重要。MultiMed Hard数据集的构建源于原始MultiMed数据集的英文测试集,通过多阶段筛选流程精炼而成。首先依据音频时长与文本长度进行初步过滤,随后利用Whisper模型排除字符错误率过高的样本以确保标注质量。进一步采用Gemini Flash模型对医学实体进行六类标注,并保留包含显著实体的样本。通过三模型难度筛选机制,结合大语言模型验证,最终选取实体错误率中位数最高的50条样本,形成聚焦于医学专业术语识别挑战的硬样本集合。
使用方法
研究人员可将该数据集直接应用于医学自动语音识别模型的基准测试。使用时应加载包含音频、文本及实体标注的完整数据列,利用提供的实体边界信息计算实体级别的字符错误率,以精准评估模型对医学术语的识别效果。数据集中预设的难度排名与多模型评估结果可作为性能对比的参考基线。该数据集兼容主流语音识别评估框架,支持通过标准化流程对模型进行端到端测试,从而系统化衡量模型在复杂医学语音场景下的鲁棒性与准确性。
背景与挑战
背景概述
MultiMed Hard数据集由Trelis Research于2024年构建,专注于医学领域的自动语音识别(ASR)评估。该数据集源自公开的MultiMed英文测试集,经过精心筛选,包含50条来自医学讲座、访谈等场景的高难度音频样本。其核心研究问题在于评估ASR模型在识别复杂医学术语实体(如药物、疾病、解剖结构等)方面的性能,旨在推动医疗语音技术在临床转录、医学教育等应用中的准确性与可靠性。该数据集的发布为医学ASR研究提供了细粒度的实体级评估基准,对提升医疗人工智能的实用价值具有显著影响力。
当前挑战
MultiMed Hard数据集所针对的领域挑战在于医学ASR中专业实体识别的固有困难,医学术语往往具有高复杂性、多义性和罕见性,导致通用ASR模型在转录时易出现实体错误,进而影响医疗决策的安全性与效率。在构建过程中,挑战主要体现在数据质量把控方面:需从海量医学音频中筛选出实体密集且转录难度高的样本,同时确保标注的准确性;此外,通过多模型难度过滤和大型语言模型验证来剔除非医学内容与标注噪声,这一流程对计算资源与算法鲁棒性提出了较高要求。
常用场景
经典使用场景
在医疗自动语音识别领域,MultiMed Hard数据集作为一项实体感知的基准测试工具,其经典使用场景集中于评估和比较不同ASR模型在复杂医疗语境下的性能表现。该数据集精心筛选了医学讲座、访谈等场景中富含专业术语的50条困难样本,通过标注药物、疾病、解剖结构等六类医学实体,为研究者提供了衡量模型识别专业术语准确性的标准化环境,从而推动医疗ASR技术向更高精度迈进。
解决学术问题
该数据集有效解决了医疗ASR研究中专业术语识别准确度评估的难题。传统ASR基准往往忽视医学实体的特殊性,导致模型在临床对话或学术讲座中表现不佳。MultiMed Hard通过引入实体级字符错误率指标,将评估焦点从通用转录转向专业术语保真度,为量化模型在药物名称、解剖学术语等关键信息的识别能力提供了可靠方法,显著提升了医疗语音技术研究的严谨性与针对性。
实际应用
在实际应用中,MultiMed Hard数据集为开发临床语音转录系统、医学教育工具和远程医疗平台提供了关键验证基础。医疗机构可利用该基准测试优化电子健康记录录入的语音接口,确保诊断描述和治疗方案中的专业术语被准确捕获。同时,医学培训平台能够依托此类评估提升讲座内容的自动字幕生成质量,辅助医学生高效学习复杂专业知识,从而增强医疗信息处理的自动化与可靠性。
数据集最近研究
最新研究方向
在医疗语音识别领域,MultiMed Hard数据集正推动着实体感知自动语音识别的前沿探索。该数据集聚焦于医学讲座和访谈中的复杂实体,如药物、病症和生物标志物,为模型在专业术语识别上的鲁棒性提供了精准评估基准。当前研究热点集中于利用多模型难度筛选和大型语言模型验证,以提升医疗ASR系统在噪声环境下的实体识别准确率,相关进展直接关联到临床文档自动化和远程医疗服务的智能化升级,对保障医疗信息完整性具有深远意义。
以上内容由遇见数据集搜集并总结生成


