VG150-coco-format
收藏Hugging Face2026-03-09 更新2026-03-10 收录
下载链接:
https://huggingface.co/datasets/maelic/VG150-coco-format
下载链接
链接失效反馈官方服务:
资源简介:
VG150数据集是Visual Genome的标准VG150分割版本,采用COCO-JSON格式重新格式化,是场景图生成(Scene Graph Generation)领域最广泛使用的基准数据集之一。该数据集包含原始Visual Genome数据集中出现频率最高的150个对象类别和50种关系,选自《通过迭代消息传递生成场景图》论文。VG150由SGG-Benchmark框架生成,并用于训练REACT论文中描述的模型。数据集包含73,538张训练图像、4,844张验证图像和27,032张测试图像,共计793,061个对象标注和439,063个关系标注。每张图像包含对象边界框(150个Visual Genome对象类别)和场景图关系(50个谓词类别,连接对象对形成有向三元组)。数据集结构包括图像、图像ID、尺寸、文件名、对象列表和关系列表等字段。需要注意的是,VG150因高类别重叠和标注偏差(如person/man/men/people)而受到批评。数据集适用于对象检测、视觉关系检测和场景图生成等任务。
创建时间:
2026-03-08
原始信息汇总
VG150 — Visual Genome 150 (COCO格式) 数据集概述
数据集基本信息
- 名称: VG150 — Visual Genome 150 (COCO format)
- 来源: 基于Visual Genome (Krishna et al., 2017) 的标准VG150划分
- 主要用途: 场景图生成、视觉关系检测
- 数据格式: COCO-JSON格式
- 语言: 英语
- 许可协议: MIT
- 数据规模: 100K < n < 1M
数据集背景与特点
该数据集是场景图生成领域最广泛使用的基准数据集Visual Genome的标准VG150划分的COCO格式版本。VG150包含了原始Visual Genome数据集中频率最高的150个物体类别和50种关系。此版本由SGG-Benchmark框架生成,并用于训练REACT论文中描述的模型。
注意: VG150因高度的类别重叠和标注偏差(例如,person / man / men / people)而受到广泛批评。
标注内容概述
每张图像包含:
- 物体边界框: 对应150个Visual Genome物体类别。
- 场景图关系: 50种谓词类别,以有向的
(主体, 谓词, 客体)三元组形式连接物体对。
数据集统计信息
| 数据划分 | 图像数量 | 物体标注数量 | 关系标注数量 |
|---|---|---|---|
| 训练集 | 73,538 | 793,061 | 439,063 |
| 验证集 | 4,844 | 54,415 | 30,133 |
| 测试集 | 27,032 | 297,922 | 153,509 |
类别信息
- 物体类别: 150个,为标准SGG划分使用的Visual Genome物体词汇表。完整列表内嵌于
dataset_info.description中。 - 谓词类别: 50个,包括:and、says、belonging to、over、parked on、growing on、standing on、made of、attached to、at、in、hanging from、wears、in front of、from、for、watching、lying on、to、behind、flying in、looking at、on back of、holding、between、laying on、riding、has、across、wearing、walking on、eating、above、part of、walking in、sitting on、under、covered in、carrying、using、along、with、on、covering、of、against、playing、near、painted on、mounted on。
数据结构
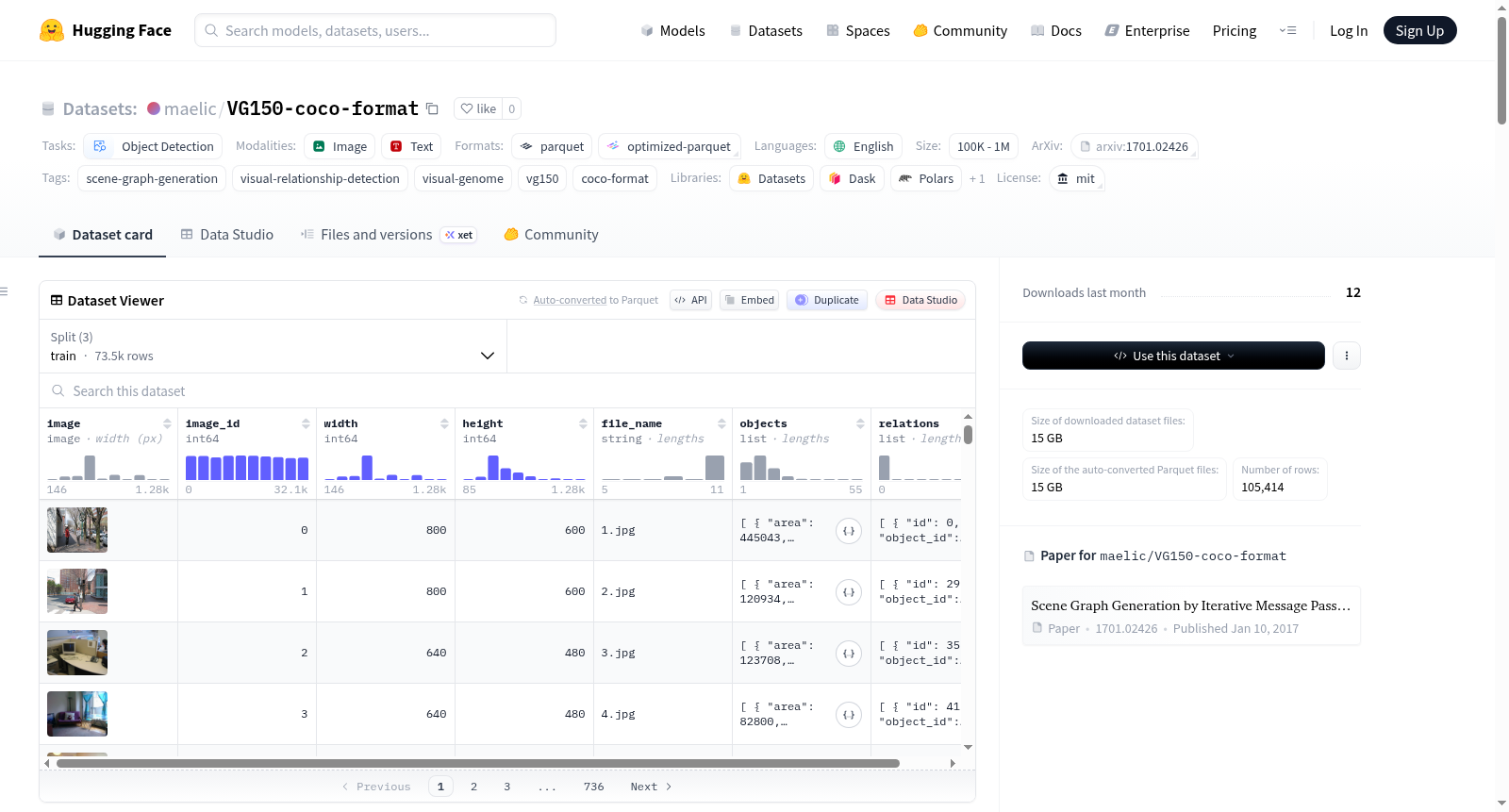
数据集为DatasetDict类型,包含train、val、test三个划分。每个划分的Dataset包含以下特征:
image: PIL图像image_id: 原始Visual Genome图像IDwidth/height: 图像尺寸file_name: 原始文件名objects: 物体标注列表,每个标注为字典,包含id、category_id、bbox (xywh)、area、iscrowd、segmentation字段。relations: 关系标注列表,每个标注为字典,包含id、subject_id、object_id、predicate_id字段。ID指向objects[*].id。
使用示例
可通过datasets库加载数据集,并从内嵌元数据中恢复标签映射以进行使用。
引用要求
若使用此数据集,请引用:
- Visual Genome原始论文。
- 建立VG150划分的原始论文(Scene graph generation by iterative message passing)。
- 若使用SGG-Benchmark模型,请引用REACT论文。
许可证
Visual Genome图像和标注根据知识共享署名4.0国际许可协议发布。
搜集汇总
数据集介绍
构建方式
在视觉关系检测与场景图生成领域,VG150-coco-format数据集作为标准基准,其构建源于对原始Visual Genome数据集的精炼与重组。该数据集采纳了由《Scene Graph Generation by Iterative Message Passing》论文确立的VG150划分标准,选取了出现频率最高的150个物体类别和50种关系谓词,确保了数据在语义上的代表性与统计显著性。随后,通过SGG-Benchmark框架的转换流程,将原有注释结构统一重整为广泛使用的COCO-JSON格式,这一过程不仅标准化了边界框与场景图关系的存储方式,也提升了数据在各类检测与生成模型中的兼容性与易用性。
使用方法
使用VG150-coco-format数据集时,研究者可通过HuggingFace的datasets库直接加载,其结构以DatasetDict形式组织,清晰划分训练、验证与测试部分。每个数据样本包含图像、图像ID、尺寸、文件名以及物体与关系列表,其中物体信息采用COCO格式的边界框与类别标识,关系则通过主体ID、客体ID及谓词ID进行关联。为便于语义解析,数据集的元描述中嵌入了类别与谓词的映射词典,用户可据此将数字标识转换为可读的标签名称,进而实现物体检测、关系预测或端到端场景图生成等任务的模型训练与评估。
背景与挑战
背景概述
VG150-coco-format数据集源自2017年发布的Visual Genome数据集,由斯坦福大学等机构的研究人员Ranjay Krishna等人创建,旨在通过众包密集标注连接语言与视觉,为场景理解提供丰富语义基础。该数据集的核心研究问题聚焦于场景图生成与视觉关系检测,通过提取原始数据中频率最高的150个对象类别和50种关系,构建了标准化的VG150划分,成为该领域广泛使用的基准。其影响力深远,推动了计算机视觉中结构化视觉表示的发展,并为后续如SGG-Benchmark等框架提供了关键数据支持,促进了模型如REACT的研发与应用。
当前挑战
VG150-coco-format数据集面临的挑战主要体现在领域问题与构建过程两方面。在领域层面,场景图生成任务需处理复杂视觉关系的细粒度识别,但数据集中存在显著的类别重叠与标注偏差,例如'person'、'man'等类别间的语义混淆,这可能导致模型学习到有偏表示,影响泛化能力。构建过程中,将原始Visual Genome数据转换为COCO格式虽提升了标准化程度,但如何有效筛选高频对象与关系以平衡覆盖范围与噪声抑制,仍是一个技术难点;同时,标注质量的不一致性及关系定义的模糊性,进一步加剧了模型训练的复杂性,要求后续研究采用数据中心化方法以优化基准可靠性。
常用场景
解决学术问题
该数据集主要解决了视觉关系检测与场景图生成领域的若干核心学术问题。它通过提供大规模、细粒度的(主语,谓词,宾语)三元组标注,为建模图像中对象间的空间、语义及交互关系提供了数据基础。这直接支持了关系预测的长尾分布问题、上下文依赖建模以及结构化视觉知识表示等研究方向的探索。其标准化格式也统一了不同方法的评估流程,使得研究成果具有可比性,从而推动了整个领域在模型架构、学习范式及偏差缓解等方面的系统性进展。
实际应用
超越纯粹的学术基准,VG150-coco-format数据集支撑了众多实际应用场景的研发。在图像描述生成中,基于场景图的模型能够产出更准确、细节更丰富的描述。在视觉问答系统里,对物体关系的深刻理解是回答复杂空间或交互问题的前提。此外,该数据集也为机器人环境交互理解、内容敏感的图像检索以及智能监控中的异常行为分析提供了关键的关系先验知识,使得机器能够以更接近人类认知的方式解读视觉世界。
数据集最近研究
最新研究方向
在视觉场景理解领域,VG150数据集作为场景图生成的标准基准,其最新研究聚焦于数据偏差的缓解与模型效率的平衡。前沿工作如REACT框架探索实时性能与精度的权衡,通过迭代消息传递优化关系检测。同时,针对数据集固有的类别重叠与标注偏见问题,学者们提出细粒度数据重构方法,旨在提升视觉关系推理的鲁棒性。这些进展不仅推动了场景图生成技术的实用化,也为跨模态智能系统提供了更可靠的视觉语义基础。
以上内容由遇见数据集搜集并总结生成


