FaceXBench
收藏arXiv2025-01-18 更新2025-01-21 收录
下载链接:
https://kartik-3004.github.io/facexbench/
下载链接
链接失效反馈官方服务:
资源简介:
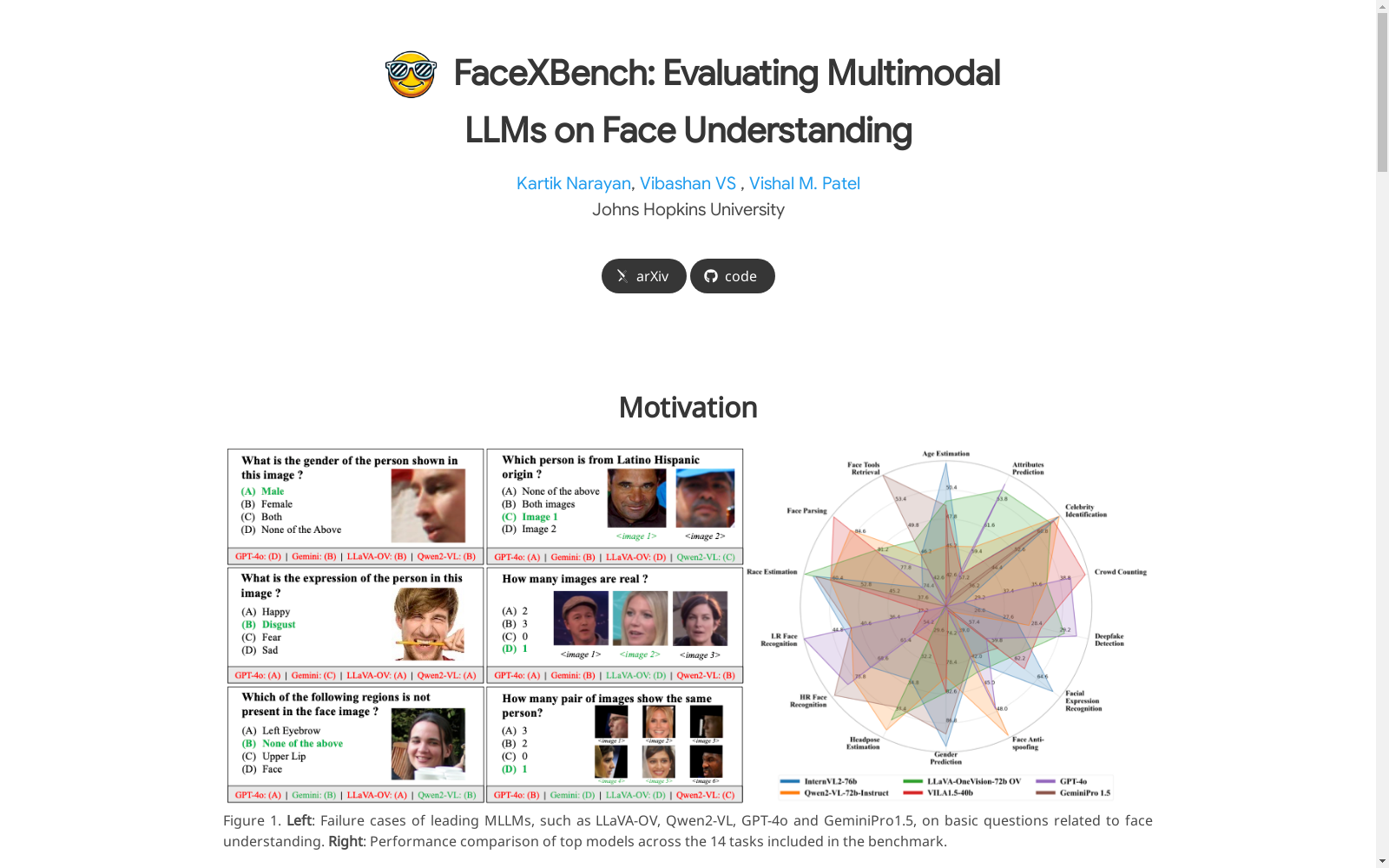
FaceXBench是由约翰霍普金斯大学的研究团队创建的一个综合性基准,旨在评估多模态大语言模型(MLLMs)在复杂人脸理解任务中的表现。该数据集包含5000个多模态选择题,涵盖了6大类14个任务,数据来源于25个公共数据集和新创建的FaceXAPI数据集。FaceXBench包含10441张独特的人脸图像,涵盖了不同年龄、性别、种族、分辨率和表情的多样性。数据集的创建过程包括从现有数据集中提取测试集、手动创建问题模板以及生成答案选项。FaceXBench的应用领域包括人脸识别、人脸认证、人脸分析等,旨在解决MLLMs在人脸理解任务中的不足,推动该领域的研究进展。
FaceXBench is a comprehensive benchmark created by a research team at Johns Hopkins University, designed to evaluate the performance of multimodal large language models (MLLMs) on complex facial understanding tasks. This dataset includes 5,000 multimodal multiple-choice questions covering 14 tasks across 6 categories, with data sourced from 25 public datasets and the newly created FaceXAPI dataset. FaceXBench contains 10,441 unique facial images, encompassing diversity across age, gender, ethnicity, resolution, and facial expressions. The dataset creation process includes extracting test subsets from existing datasets, manually crafting question templates, and generating answer options. Application scenarios of FaceXBench include facial recognition, face authentication, facial analysis, and others, aiming to address the limitations of MLLMs in facial understanding tasks and advance research progress in this field.
提供机构:
约翰霍普金斯大学
创建时间:
2025-01-18
搜集汇总
数据集介绍
构建方式
FaceXBench数据集的构建过程分为三个主要步骤。首先,研究人员从25个公开数据集中筛选出与面部理解任务相关的测试集,并创建了一个新的数据集FaceXAPI,专门用于工具检索任务。其次,研究人员为每个任务手动设计了问题模板,确保问题能够激发模型进行推理和比较。最后,通过生成四个选项(其中一个为正确答案)来确保问题的多样性和难度,并通过手动过滤确保问题的相关性和准确性。整个过程严格遵循质量控制标准,确保数据的高质量和多样性。
使用方法
FaceXBench数据集的使用方法主要包括三个评估设置:零样本学习、上下文任务描述和链式思维提示。在零样本学习中,模型仅接收基础提示进行推理;在上下文任务描述中,模型会接收到任务的具体描述;在链式思维提示中,模型被要求逐步推理后再给出最终答案。通过这些设置,研究人员可以全面评估模型在不同情境下的表现。数据集的使用还包括对26个开源模型和2个专有模型的广泛评估,揭示了当前模型在复杂面部理解任务中的挑战和改进空间。
背景与挑战
背景概述
FaceXBench是由约翰霍普金斯大学的研究团队于2025年推出的一个多模态大语言模型(MLLMs)在面部理解任务上的综合基准测试。该数据集旨在填补现有MLLMs在面部理解能力评估上的空白,涵盖了6大类别、14项任务的5000个多模态选择题,数据来源于25个公开数据集和新创建的FaceXAPI数据集。FaceXBench的推出标志着面部理解领域的一个重要进展,特别是在面部识别、表情分析、头部姿态估计等任务上,为MLLMs的性能评估提供了标准化工具。该数据集不仅推动了MLLMs在面部理解任务上的研究,还为相关领域的模型优化和公平性评估提供了重要参考。
当前挑战
FaceXBench在构建和应用过程中面临多重挑战。首先,面部理解任务本身具有高度的复杂性,涉及面部特征的细粒度分析、多模态信息的融合以及跨任务的推理能力。现有的MLLMs在处理这些任务时表现不佳,尤其是在深度伪造检测、人群计数等需要精细视觉分析的任务上。其次,数据集的构建过程中,如何确保问题的多样性和难度平衡是一个重要挑战。FaceXBench通过精心设计的问题模板和干扰选项,提升了问题的复杂性,但也增加了模型推理的难度。此外,如何有效评估模型在不同任务上的表现,尤其是在零样本、上下文任务描述和思维链提示等不同设置下的性能,也是该数据集面临的关键挑战。
常用场景
经典使用场景
FaceXBench数据集主要用于评估多模态大语言模型(MLLMs)在复杂人脸理解任务中的表现。该数据集通过包含5000个多模态选择题,涵盖了14个任务和6个主要类别,如偏见与公平性、人脸认证、人脸识别、人脸分析、人脸定位和工具检索等。这些任务旨在全面评估模型在不同人脸理解场景下的能力,尤其是在零样本、上下文任务描述和链式思维提示等设置下的表现。
解决学术问题
FaceXBench解决了当前多模态大语言模型在人脸理解任务中缺乏系统性评估的问题。通过引入这一综合基准,研究人员能够量化并比较不同模型在复杂人脸理解任务中的表现,揭示现有模型的局限性。例如,FaceXBench揭示了当前模型在深度伪造检测、人群计数等任务中的显著不足,并为未来的模型改进提供了明确的方向。
实际应用
FaceXBench的实际应用场景广泛,涵盖了虚拟现实、自动驾驶、身份认证、人机交互和体育分析等领域。在这些应用中,准确的人脸理解至关重要,尤其是在需要处理多样化的面部特征、表情和姿态时。通过FaceXBench,开发者能够评估和优化模型在这些实际场景中的表现,确保其在真实世界中的可靠性和鲁棒性。
数据集最近研究
最新研究方向
FaceXBench作为首个专注于多模态大语言模型(MLLMs)在复杂人脸理解任务中的评估基准,涵盖了14个任务和6个主要类别,包括偏见与公平、人脸认证、人脸识别、人脸分析、人脸定位和工具使用。该数据集通过从25个公开数据集中提取的5000个多模态选择题,结合新创建的FaceXAPI数据集,系统评估了26个开源MLLMs和2个专有模型的表现。研究揭示了当前MLLMs在深度伪造检测、人群计数等任务中的显著不足,尤其是在零样本、上下文任务描述和思维链提示等评估设置下,模型的表现仍有较大提升空间。FaceXBench的推出为未来MLLMs在人脸理解领域的研究提供了重要的基准资源,推动了模型在复杂任务中的进一步发展。
相关研究论文
- 1FaceXBench: Evaluating Multimodal LLMs on Face Understanding约翰霍普金斯大学 · 2025年
以上内容由遇见数据集搜集并总结生成


