有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
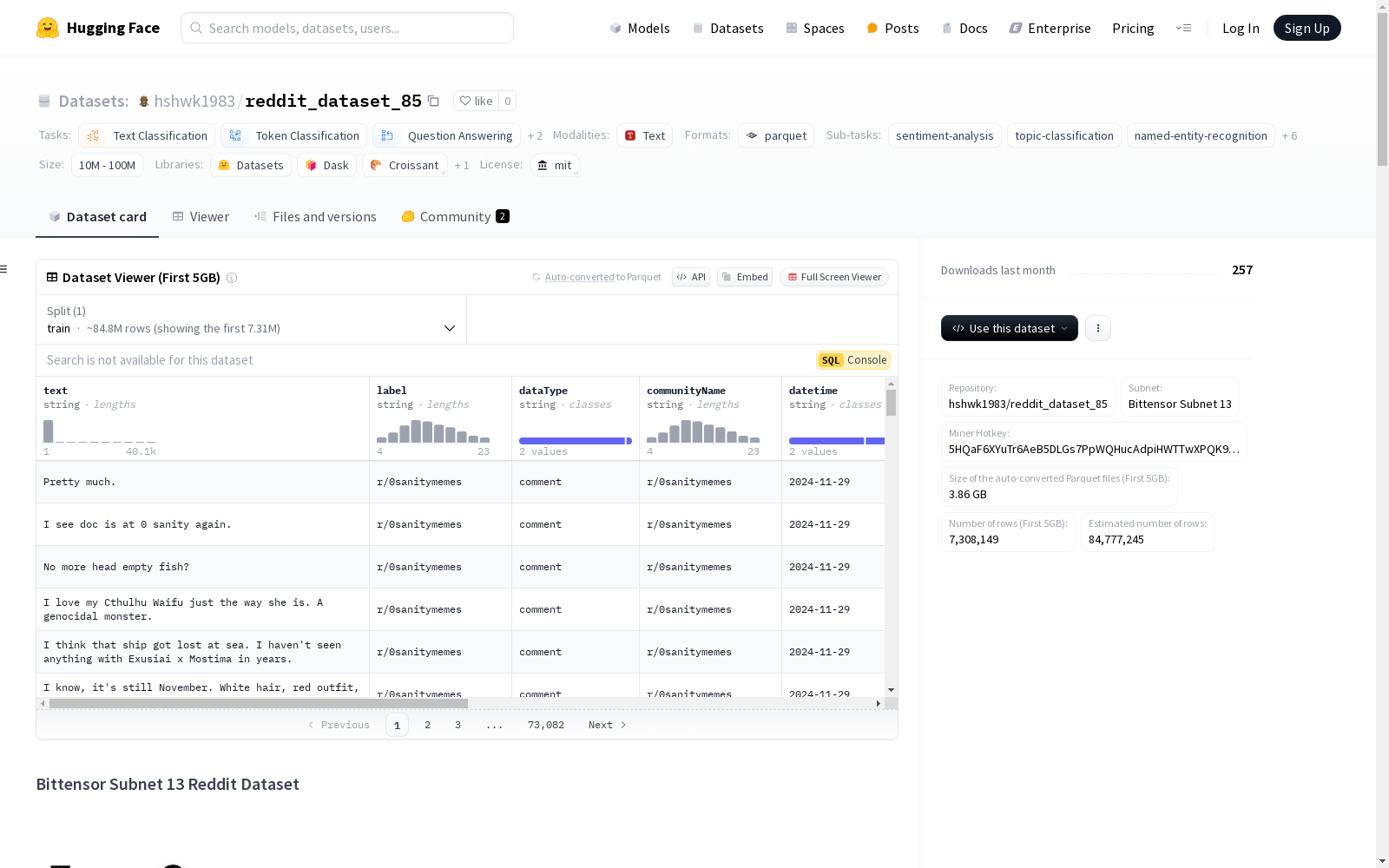
该数据集是Bittensor Subnet 13去中心化网络的一部分,包含预处理的Reddit数据。数据由网络矿工持续更新,提供Reddit内容的实时流,适用于各种分析和机器学习任务。
该数据集的多样性允许研究人员和数据科学家探索社交媒体动态的各个方面,并开发创新应用。用户可以利用这些数据进行以下任务:
主要语言:数据集主要是英语,但由于去中心化的创建方式,可能包含多语言内容。
每个实例代表一个Reddit帖子或评论,包含以下字段:
text (字符串): Reddit帖子或评论的主要内容。label (字符串): 内容的情感或主题类别。dataType (字符串): 指示条目是帖子还是评论。communityName (字符串): 内容发布的子版块名称。datetime (字符串): 内容发布或评论的日期。username_encoded (字符串): 为保护用户隐私而编码的用户名。url_encoded (字符串): 内容中包含的任何URL的编码版本。该数据集持续更新,没有固定的分割。用户应根据其需求和数据的时间戳创建自己的分割。
数据收集自Reddit上的公开帖子和评论,遵守平台的条款服务和API使用指南。
所有用户名和URL均已编码以保护用户隐私。数据集不包含故意包含的个人或敏感信息。
用户应注意Reddit数据中固有的潜在偏见,包括人口统计和内容偏见。该数据集反映了Reddit上表达的内容和意见,不应被视为一般人口的代表性样本。
该数据集在MIT许可下发布。使用此数据集还需遵守Reddit的使用条款。
如果您在研究中使用此数据集,请按以下方式引用:
@misc{hshwk19832024datauniversereddit_dataset_85, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={hshwk1983}, year={2024}, url={https://huggingface.co/datasets/hshwk1983/reddit_dataset_85}, }
如需报告问题或贡献数据集,请联系矿工或使用Bittensor Subnet 13治理机制。
有关完整统计信息,请参阅存储库中的stats.json文件。
| 排名 | 主题 | 总数 | 百分比 |
|---|---|---|---|
| 1 | r/AskReddit | 356540 | 0.95% |
| 2 | r/CFB | 232073 | 0.62% |
| 3 | r/AITAH | 193206 | 0.51% |
| 4 | r/nfl | 169054 | 0.45% |
| 5 | r/politics | 114345 | 0.30% |
| 6 | r/AmIOverreacting | 109603 | 0.29% |
| 7 | r/teenagers | 94469 | 0.25% |
| 8 | r/NoStupidQuestions | 93107 | 0.25% |
| 9 | r/repost | 92750 | 0.25% |
| 10 | r/GOONED | 81178 | 0.22% |
| 日期 | 新增实例 | 总实例 |
|---|---|---|
| 2024-11-29T06:42:51Z | 812754 | 812754 |
| 2024-12-02T18:49:01Z | 17388429 | 18201183 |
| 2024-12-06T07:05:11Z | 19357032 | 37558215 |
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
YOLO Drone Detection Dataset
为了促进无人机检测模型的开发和评估,我们引入了一个新颖且全面的数据集,专门为训练和测试无人机检测算法而设计。该数据集来源于Kaggle上的公开数据集,包含在各种环境和摄像机视角下捕获的多样化的带注释图像。数据集包括无人机实例以及其他常见对象,以实现强大的检测和分类。
github 收录
poi
本项目收集国内POI兴趣点,当前版本数据来自于openstreetmap。
github 收录
Google Scholar
Google Scholar是一个学术搜索引擎,旨在检索学术文献、论文、书籍、摘要和文章等。它涵盖了广泛的学科领域,包括自然科学、社会科学、艺术和人文学科。用户可以通过关键词搜索、作者姓名、出版物名称等方式查找相关学术资源。
scholar.google.com 收录
Traditional-Chinese-Medicine-Dataset-SFT
该数据集是一个高质量的中医数据集,主要由非网络来源的内部数据构成,包含约1GB的中医各个领域临床案例、名家典籍、医学百科、名词解释等优质内容。数据集99%为简体中文内容,质量优异,信息密度可观。数据集适用于预训练或继续预训练用途,未来将继续发布针对SFT/IFT的多轮对话和问答数据集。数据集可以独立使用,但建议先使用配套的预训练数据集对模型进行继续预训练后,再使用该数据集进行进一步的指令微调。数据集还包含一定比例的中文常识、中文多轮对话数据以及古文/文言文<->现代文翻译数据,以避免灾难性遗忘并加强模型表现。
huggingface 收录