reczoo/TaobaoAd_x1
收藏Hugging Face2023-12-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/reczoo/TaobaoAd_x1
下载链接
链接失效反馈官方服务:
资源简介:
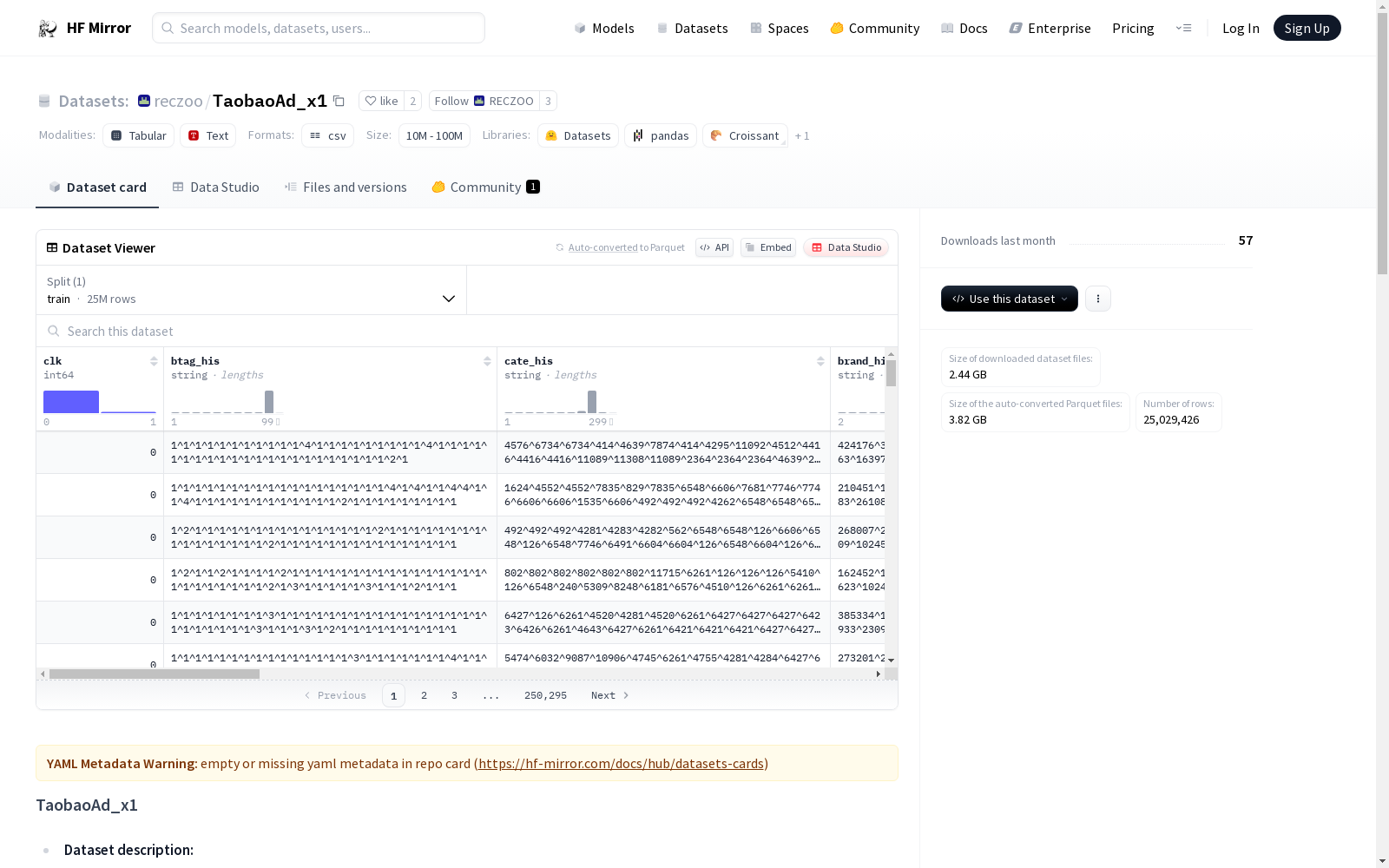
TaobaoAd_x1数据集由阿里巴巴提供,包含8天的广告点击数据(2600万条记录),这些数据是从1140000名用户中随机抽取的。默认情况下,前7天(即20170506-20170512)的样本用作训练样本,最后一天(即20170513)的样本用作测试样本。此外,数据集还涵盖了所有用户近22天的购物行为,总计7亿条记录。在预处理过程中,由于用户或商品信息的缺失,约5%的样本被删除。我们遵循了应用于重现DMR工作的预处理步骤,并过滤了出现次数少于10次的分类特征,同时将用户行为序列的最大长度设置为50。数据集的统计信息如下:训练集21,929,911条,测试集3,099,515条。
The TaobaoAd_x1 dataset is provided by Alibaba, containing 8 days of ad click data (26 million records) randomly sampled from 1.14 million users. By default, samples from the first 7 days (20170506 to 20170512) are used as training samples, while those from the last day (20170513) serve as test samples. Additionally, the dataset covers nearly 22 days of shopping behaviors of all users, totaling 700 million records. During preprocessing, approximately 5% of samples were removed due to missing user or item information. We followed the preprocessing steps adopted for reproducing the DMR work, filtered categorical features that appear fewer than 10 times, and set the maximum length of user behavior sequences to 50. The dataset statistics are as follows: 21,929,911 training samples and 3,099,515 test samples.
提供机构:
reczoo
原始信息汇总
TaobaoAd_x1
数据集描述
TaobaoAd_x1是由阿里巴巴提供的数据集,包含8天的广告点击数据(2600万条记录),这些数据是从1140000名用户中随机抽样的。默认情况下,前7天的样本(即20170506-20170512)用作训练样本,最后一天的样本(即20170513)用作测试样本。此外,该数据集还涵盖了最近22天内所有用户的购物行为,总计七亿条记录。在预处理过程中,由于用户或商品信息缺失,约有5%的样本被丢弃。我们过滤了不频繁的分类特征,阈值为min_category_count=10,并将用户行为序列的最大长度设置为50。
数据集统计信息如下:
| 数据集分割 | 总计 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|
| TaobaoAd_x1 | 25,029,426 | 21,929,911 | 3,099,515 |
数据格式
主要数据
- user: 用户ID(整数)
- time_stamp: 时间戳(Bigint,例如1494032110表示2017-05-06 08:55:10)
- adgroup_id: 广告组ID(整数)
- pid: 场景
- noclk: 1表示未点击,0表示点击
- clk: 1表示点击,0表示未点击
广告特征
- adgroup_id: 广告ID(整数)
- cate_id: 类别ID
- campaign_id: 广告系列ID
- brand: 品牌ID
- customer_id: 广告商ID
- price: 商品价格
用户特征
- userid: 用户ID
- cms_segid: 微组ID
- cms_group_id: cms组ID
- final_gender_code: 性别,1表示男性,2表示女性
- age_level: 年龄级别
- pvalue_level: 消费等级,1: 低, 2: 中, 3: 高
- shopping_level: 购物深度,1: 浅层用户, 2: 中度用户, 3: 深度用户
- occupation: 是否为大学生,1: 是, 0: 否
- new_user_class_level: 城市级别
原始行为日志
- nick: 用户ID(整数)
- time_stamp: 时间戳(Bigint,例如1494032110表示2017-05-06 08:55:10)
- btag: 行为类型,包括:ipv/cart/fav/buy
- cate: 类别ID(整数)
- brand: 品牌ID(整数)
搜集汇总
数据集介绍
构建方式
TaobaoAd_x1数据集由阿里巴巴提供,涵盖8天的广告点击数据(2600万条记录),从中随机抽取了114万用户的样本。该数据集的构建遵循了严格的数据预处理流程,包括去除缺失用户或商品信息的样本,筛选出现频率低于阈值的类别特征,并限定用户行为序列的最大长度为50,确保了数据集的质量和可用性。
特点
该数据集具有丰富的特征,包括用户ID、时间戳、广告组ID、场景、点击情况等,以及广告特征、用户画像和原始行为日志等维度信息。数据集的构建旨在为广告点击率预测提供个性化推荐模型,其独特之处在于融合了用户的历史行为数据,为广告推荐系统提供了深度的用户行为分析基础。此外,数据集在训练集和测试集的划分上,采用了7天训练与1天测试的方式,符合实际业务场景的需求。
使用方法
使用TaobaoAd_x1数据集时,用户可以从HuggingFace的官方仓库下载相应的训练和测试文件。数据集以CSV格式存储,其中包含了用户、广告特征、用户画像和行为日志等多个维度的信息。用户可以通过解析CSV文件,将数据加载到数据处理框架中,进行模型训练和评估。为确保数据完整性,建议使用md5sum校验文件的完整性。
背景与挑战
背景概述
在电子商务领域,用户点击率预测是提升广告投放效率和转化率的关键技术。TaobaoAd_x1数据集,由阿里巴巴提供,是研究该领域的重要资源。该数据集包含了2017年5月6日至5月13日间,114万用户的广告点击数据,总计约2600万条记录。其中,前7天作为训练集,最后一天作为测试集。该数据集的创建旨在为个性化点击率预测模型的研究与开发提供基准数据,其研究成果在AAAI 2020上发表的《Deep Match to Rank Model for Personalized Click-Through Rate Prediction》一文中得到了应用,对点击率预测领域产生了显著影响。
当前挑战
构建TaobaoAd_x1数据集的过程中,研究人员面临了多个挑战。首先,数据预处理中缺失的用户或商品信息导致约5%的样本被丢弃。其次,为了优化模型性能,研究人员采用了过滤不频繁分类特征的方法,并设置了用户行为序列的最大长度。此外,数据集在解决个性化点击率预测问题的同时,也面临着如何有效处理大规模数据、保持数据一致性和准确性的挑战。
常用场景
经典使用场景
在数字广告领域,reczoo/TaobaoAd_x1数据集的典型应用场景在于广告点击率(CTR)的预测。该数据集详细记录了用户在淘宝平台的行为,为构建深度学习模型提供了丰富的用户行为序列和广告特征,助力研究者在模拟真实广告投放过程中,预测用户对特定广告的点击概率。
解决学术问题
该数据集解决了个性化推荐系统中的关键问题,即如何准确预测用户的点击行为。通过分析用户历史行为和广告特征,研究者能够构建出更高效的CTR预测模型,这对于提升广告投放的精准度和转化率具有显著意义。此外,数据集的处理流程也为如何处理缺失数据和过滤稀疏特征提供了参考。
衍生相关工作
基于reczoo/TaobaoAd_x1数据集,相关研究产生了多项经典工作,如Ze Lyu等人提出的Deep Match to Rank模型,该模型在个性化点击率预测方面取得了显著成果,为后续的研究提供了重要的理论基础和实践参考。
以上内容由遇见数据集搜集并总结生成


