LongAudio
收藏Hugging Face2025-07-15 更新2025-07-15 收录
下载链接:
https://huggingface.co/datasets/nvidia/LongAudio
下载链接
链接失效反馈官方服务:
资源简介:
LongAudio-XL是一个大规模的长音频问答数据集,包含了约125万种不同的例子,用于训练大型音频语言模型进行长音频推理和问题解决任务。数据集基于原始的LongAudio集合,增加了大约100万新的QA对,涵盖了各种类型的音频,包括环境声音、语音(主要是英语)和音乐。这些音频来源于多个开源数据集,并通过合成数据进行了扩充。
提供机构:
NVIDIA
创建时间:
2025-07-10
原始信息汇总
LongAudio-XL 数据集概述
数据集描述
- 名称: LongAudio-XL
- 目的: 用于开发大型音频语言模型,专注于长音频推理和问题解决任务(30秒至10分钟)
- 规模: 约125万组多样化的问答对
- 特点: 包含长语音问答对,扩展了原始LongAudio数据集
- 数据来源: 多个开放源代码数据集
数据集组成
数据集按音频来源分为13个子集:
- DailyTalk: 日常对话语音
- IEMOCAP: 情感语音
- MELD: 多模态情感对话
- MultiDialog: 多轮对话
- LibriSpeech: 朗读语音
- VoxPopuli: 多语言议会语音
- Switchboard: 电话对话
- Europarl: 欧洲议会演讲
- Fisher: 英语对话
- MiraData: 声音和音乐
- Recap: 视频摘要音频
- GigaSpeech: 大规模语音
- LongAudioBench: 语音、声音和音乐基准
数据集特性
- 语言: 英语
- 许可证: NVIDIA OneWay非商业许可证
- 大小: 1M<n<10M
- 标签: 合成数据
- 任务类别: 音频文本到文本
主要技能
声音和音乐
- 字幕生成
- 情节问答
- 时间问答
- 细节问答
- 子场景问答
- 通用问答
语音
- 讽刺识别
- 情感状态推理
- 主题关系推理
- 信息提取
- 摘要生成
- 顺序推理
数据格式
- 模态: 音频(WAV/MP3/FLAC) + 文本(JSON)
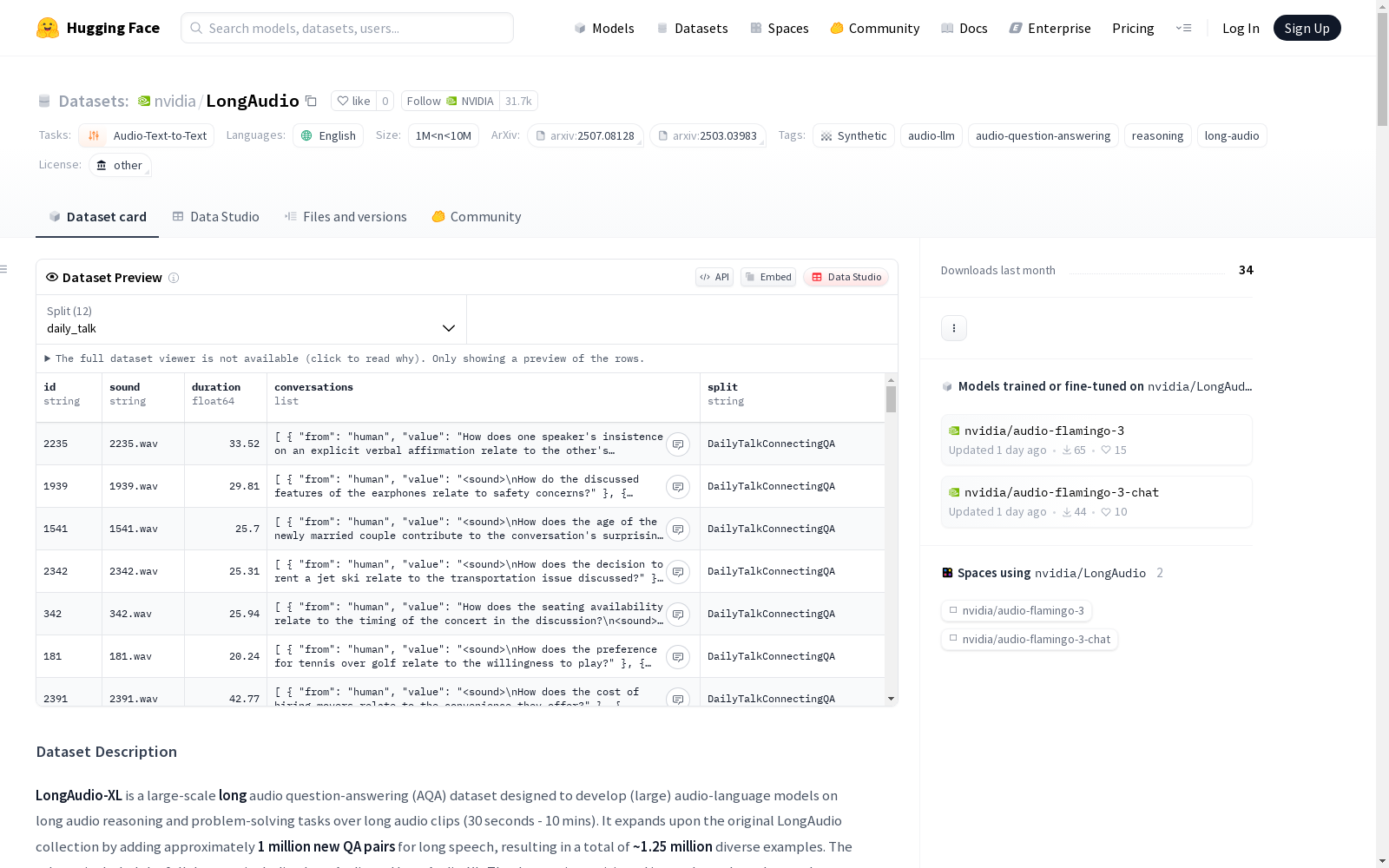
- JSON结构: json [ { "id": "ID", "sound": "音频文件名", "duration": "时长", "conversations": [ { "from": "human", "value": "<sound> 问题" }, { "from": "gpt", "value": "答案" } ] } ]
使用说明
- 仅提供文本问答注释
- 用户需自行从原始来源获取对应音频文件
- 音频文件可能需要切片或组合
所有者
- NVIDIA Corporation
创建日期
2025年7月10日
参考文献
- Audio Flamingo 3 (2025)
- Audio Flamingo (2024)
- Audio Flamingo 2 (2025)
搜集汇总
数据集介绍
构建方式
LongAudio-XL数据集的构建融合了多源开放数据集与合成数据生成技术,通过系统化的元数据整合与专家设计的推理提示,利用大语言模型生成高质量的问答对。音频素材源自12个公开语音及音乐数据集,涵盖日常对话、议会演讲、情感语音等多种场景,原始音频文件通过非分割或时序拼接方式处理。数据标注采用半自动化流程,结合人工迭代优化提示模板,确保问答对的多样性与逻辑严谨性。
使用方法
使用本数据集需遵循分阶段处理流程:首先根据JSON文件中的'sound'字段索引,从原始数据源获取对应音频文件;随后按照各子集备注要求进行音频拼接或分段处理。典型应用场景包括音频语言模型的预训练与微调,研究者可通过加载处理后的音频与标注数据,构建端到端的长音频问答任务。需注意不同子集可能适用差异化的许可协议,使用前应逐一确认合规性。
背景与挑战
背景概述
LongAudio-XL是由NVIDIA Corporation于2025年7月发布的大规模长音频问答数据集,旨在推动音频语言模型在长音频推理和问题解决任务中的发展。该数据集扩展了原有的LongAudio集合,新增约100万对长语音问答样本,总量达到约125万对多样化示例。数据集涵盖语音、环境声音和音乐等多种音频类型,源自DailyTalk、IEMOCAP、LibriSpeech等十余个公开数据集。通过整合多源异构数据并采用大语言模型生成问答对,该数据集为训练和微调音频语言模型提供了丰富资源,显著提升了模型在长音频理解、情感推理、信息提取等复杂任务上的性能。
当前挑战
构建LongAudio-XL面临双重挑战:在领域问题层面,长音频理解需解决时序建模、上下文依赖和跨模态对齐等核心难题,特别是针对30秒至10分钟不等的连续音频,模型需具备捕捉长程依赖和细粒度语义的能力;在数据构建层面,由于版权限制无法直接提供原始音频文件,用户需根据JSON标注自行从原始数据源检索并拼接音频片段,这一过程涉及复杂的文件匹配和音频处理流程。此外,多源数据的异构性导致音频质量、采样率和标注格式存在显著差异,需通过统一的数据清洗和标准化流程确保样本一致性。
常用场景
经典使用场景
在音频语言模型研究领域,LongAudio-XL数据集因其大规模长音频问答对的特性,成为训练和微调音频语言模型的黄金标准。该数据集广泛应用于长音频理解与推理任务,如情感状态分析、话题关系推理以及信息提取等。研究者通过该数据集能够构建能够处理30秒至10分钟长音频的模型,显著提升了模型在复杂语境下的表现能力。
解决学术问题
LongAudio-XL数据集有效解决了长音频理解中的多个关键学术问题。通过提供涵盖多种技能的大规模问答对,该数据集支持模型在长音频中执行复杂的推理任务,如时序问答、情感识别和因果关系分析。其多样化的音频来源和精细的标注方法,为研究者提供了探索音频语言模型在长上下文环境下性能的宝贵资源。
实际应用
在实际应用中,LongAudio-XL数据集为智能语音助手、自动会议记录系统和情感计算工具的开发提供了重要支持。例如,在客户服务场景中,基于该数据集训练的模型能够准确理解长对话中的情感变化和关键信息,从而提供更精准的服务。此外,该数据集还被广泛应用于教育领域的自动评分系统和医疗领域的语音情绪分析工具中。
数据集最近研究
最新研究方向
在音频语言模型领域,LongAudio-XL数据集的发布为长音频理解与推理任务提供了重要支持。该数据集涵盖了从30秒到10分钟不等的长音频片段,并包含约125万组多样化的问答对,为研究者训练大规模音频语言模型提供了丰富资源。当前研究热点集中在利用该数据集开发具备长音频理解能力的模型,如Audio Flamingo系列,这些模型在少样本学习、对话能力及专家级推理方面展现出显著优势。随着多模态交互需求的增长,如何结合语音、音乐及环境音进行跨模态推理成为前沿探索方向。该数据集的技能分类体系,如讽刺识别、情感状态推理等,也为细粒度语音分析任务设定了新的基准。值得注意的是,合成数据生成与人类反馈循环结合的标注方法,为构建高质量音频问答数据集提供了可借鉴的范式。
以上内容由遇见数据集搜集并总结生成


