assamese-tts-val
收藏Hugging Face2025-06-01 更新2025-06-02 收录
下载链接:
https://huggingface.co/datasets/MehdiAslam/assamese-tts-val
下载链接
链接失效反馈官方服务:
资源简介:
阿萨姆语文本到语音合成验证集,包含文本、标准化文本、音频数据,以及相应的索引信息。训练集包含312个样本,整个数据集大小为81843762字节。
Assamese Text-to-Speech Synthesis Validation Set contains text, normalized text, audio data, and corresponding index information. The training set includes 312 samples, and the total size of the entire dataset is 81,843,762 bytes.
创建时间:
2025-06-01
原始信息汇总
数据集概述:assamese-tts-val
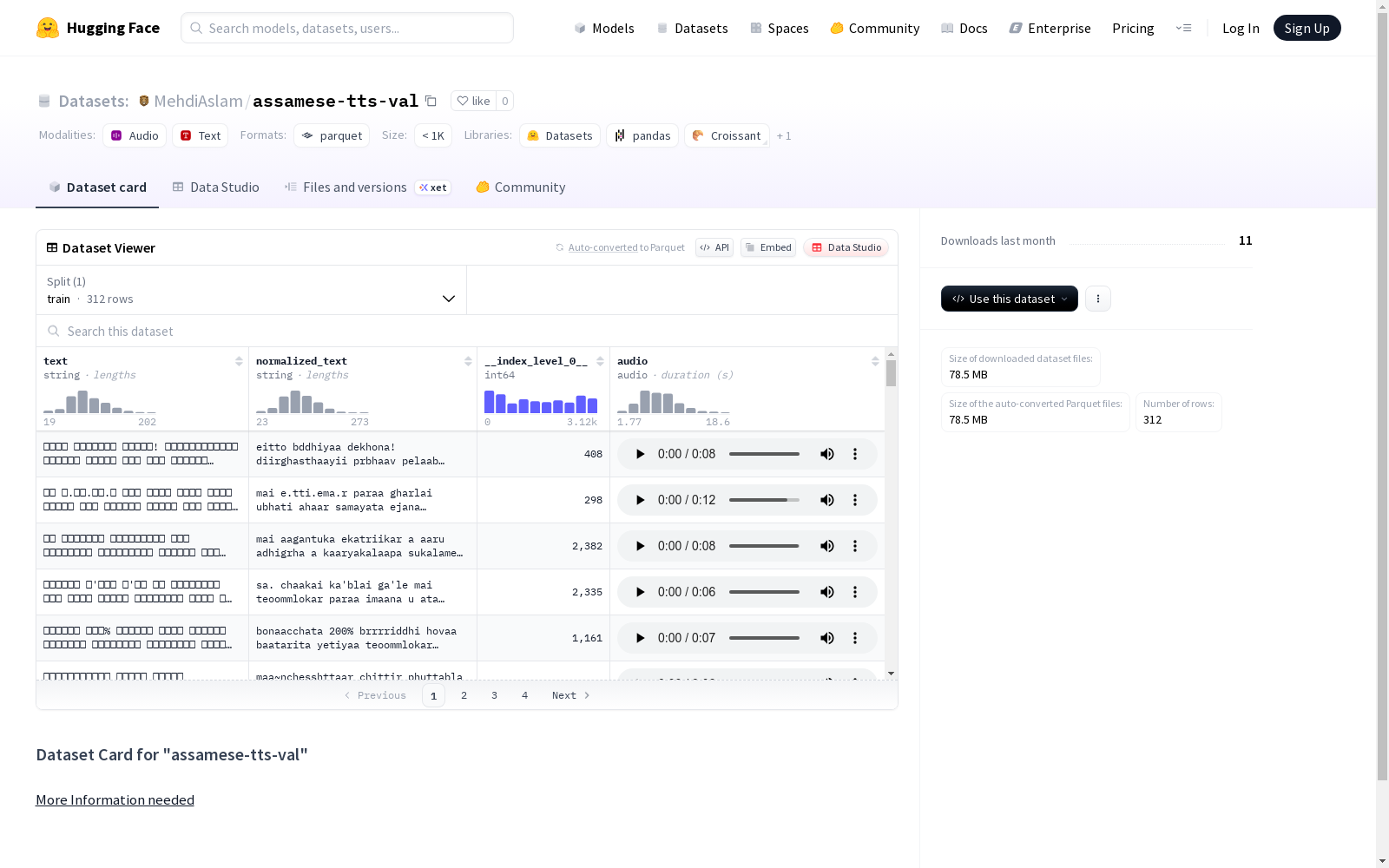
数据集基本信息
- 数据集名称: assamese-tts-val
- 下载大小: 78,505,984 字节
- 数据集大小: 81,843,762 字节
- 训练集样本数: 312
- 音频采样率: 16,000 Hz
数据集结构
特征
- text: 字符串类型,原始文本
- normalized_text: 字符串类型,标准化后的文本
- index_level_0: 整型,索引级别
- audio: 音频类型,包含采样率信息
数据划分
- train: 训练集,包含312个样本,大小为81,843,762字节
配置文件
- 默认配置: 数据文件路径为
data/train-*
搜集汇总
数据集介绍
构建方式
在阿萨姆语语音合成研究领域,assamese-tts-val数据集的构建体现了对低资源语言技术发展的重视。该数据集通过采集母语者的语音录音,并辅以相应的文本转录,形成了结构化的语音-文本配对资源。每条数据均包含原始文本及其规范化形式,确保了语言表达的准确性和一致性。音频数据以16kHz的采样率进行保存,既满足了语音合成模型对音质的基本要求,又控制了存储和计算资源的开销。数据集共包含312个训练样本,总大小约为81.8MB,其构建过程注重数据的代表性和实用性,为阿萨姆语语音合成技术的推进提供了重要支撑。
特点
assamese-tts-val数据集展现出鲜明的技术特色,其核心在于针对阿萨姆语这一特定语言的语音合成需求进行了优化设计。数据集提供了文本与规范化文本的双重标注,便于模型学习语言的正规化表达。音频特征方面,所有样本均采用16kHz采样率,保证了语音信号的清晰度与模型处理的效率。数据集规模适中,包含312个训练实例,适合用于模型验证与调优任务。每个样本还配有索引标识,便于数据的管理与检索。这些特点共同构成了该数据集在低资源语言语音合成研究中的独特价值。
使用方法
对于研究人员而言,assamese-tts-val数据集的应用需遵循规范的流程。使用者可通过HuggingFace数据集库直接加载该资源,利用其预定义的训练分割进行模型训练与验证。数据集中包含的文本和音频字段可直接用于语音合成模型的输入输出配对训练。在具体操作中,建议先对规范化文本进行预处理,再将其与对应的音频信号结合,构建端到端的训练 pipeline。该数据集特别适合用于阿萨姆语文本到语音转换模型的性能评估,以及跨语言语音合成技术的对比研究。
背景与挑战
背景概述
在语音合成技术快速发展的背景下,阿萨姆语作为印度东北部的重要语言,其数字资源相对匮乏。assamese-tts-val数据集应运而生,旨在为阿萨姆语文本到语音合成研究提供标准化评估基准。该数据集由社区研究者构建,聚焦于低资源语言的语音技术开发,通过收录纯正发音样本,推动多语言语音模型的公平性发展。
当前挑战
阿萨姆语语音合成面临音素覆盖不足与声学特征多样性的双重挑战,需解决语调韵律的方言差异性问题。数据构建过程中,受限于母语发音人稀缺与录音环境标准化困难,样本规模难以扩展;同时文本标注需兼顾口语化表达与书面语规范,跨语言转写的一致性保障成为关键瓶颈。
常用场景
经典使用场景
在阿萨姆语语音合成研究中,assamese-tts-val数据集作为验证集,被广泛应用于评估文本到语音模型的性能。该数据集包含312条阿萨姆语语音样本,采样率为16kHz,常用于模型训练后的泛化能力测试,确保合成语音的自然度和准确性。通过对比训练集和验证集的表现,研究者能够优化模型参数,提升跨场景的鲁棒性。
实际应用
在实际应用中,该数据集为阿萨姆语地区的智能助手、有声读物和教育工具开发提供了核心数据支持。例如,可用于构建本地化语音交互系统,帮助残障人士通过语音访问数字内容。其16kHz采样率的音频格式兼容主流嵌入式设备,助力边缘计算场景下的实时语音生成。
衍生相关工作
基于该数据集衍生的经典工作包括跨语言TTS迁移学习研究,如通过预训练模型在阿萨姆语上的微调实验。相关研究探索了音素映射和韵律适配技术,推动了Meta的MMS、Google的Tacotron等框架在低资源语言上的适配,为后续多语言语音合成基准数据集(如CVSS)的设计提供了参考。
以上内容由遇见数据集搜集并总结生成


