Streamer
收藏arXiv2025-07-30 更新2025-08-01 收录
下载链接:
https://mumuwei.github.io/GestureHYDRA/
下载链接
链接失效反馈官方服务:
资源简介:
Streamer数据集是一个包含中文语音和显式语义手势的3D人体运动高质量数据集,主要用于研究直播场景下的手语合成。该数据集包含了一系列预定义的手势(如数字和方向),以及相应的语音音频。Streamer数据集的创建旨在解决现有数据集中缺乏显式语义手势的问题,并通过混合模态扩散Transformer和级联同步检索增强生成技术,实现灵活可靠的人体手势合成。该数据集的应用领域包括电影制作、游戏设计、机器人技术和数字人类创建等。
The Streamer Dataset is a high-quality 3D human motion dataset encompassing Chinese speech and explicit semantic gestures, primarily intended for research on sign language synthesis in live streaming scenarios. This dataset includes a series of predefined gestures (e.g., numbers and directions) along with corresponding speech audio. Developed to address the shortage of explicit semantic gestures in existing datasets, the Streamer Dataset enables flexible and reliable human gesture synthesis via multimodal diffusion Transformer and cascaded synchronous retrieval-augmented generation technologies. Its applicable domains include film production, game design, robotics, and digital human creation, among others.
提供机构:
中国科学技术大学,百度公司
创建时间:
2025-07-30
原始信息汇总
GestureHYDRA 数据集概述
基本信息
- 数据集名称: GestureHYDRA: Semantic Co-speech Gesture Synthesis via Hybrid Modality Diffusion Transformer and Cascaded-Synchronized Retrieval-Augmented Generation
- 发表会议: ICCV 2025
- 作者机构:
- 中国科学技术大学
- 百度VIS团队
- 贡献者: Quanwei Yang, Luying Huang, Kaisiyuan Wang等
- 相关资源:
- 论文
- arXiv
- 视频
- 代码
- 数据
数据集描述
- 主要内容: 包含3D人体运动数据,特别是一组具有明确语义的手势,常用于直播主播。
- 特点:
- 高质量
- 语义明确的手势
- 用于语音伴随手势生成研究
研究方法
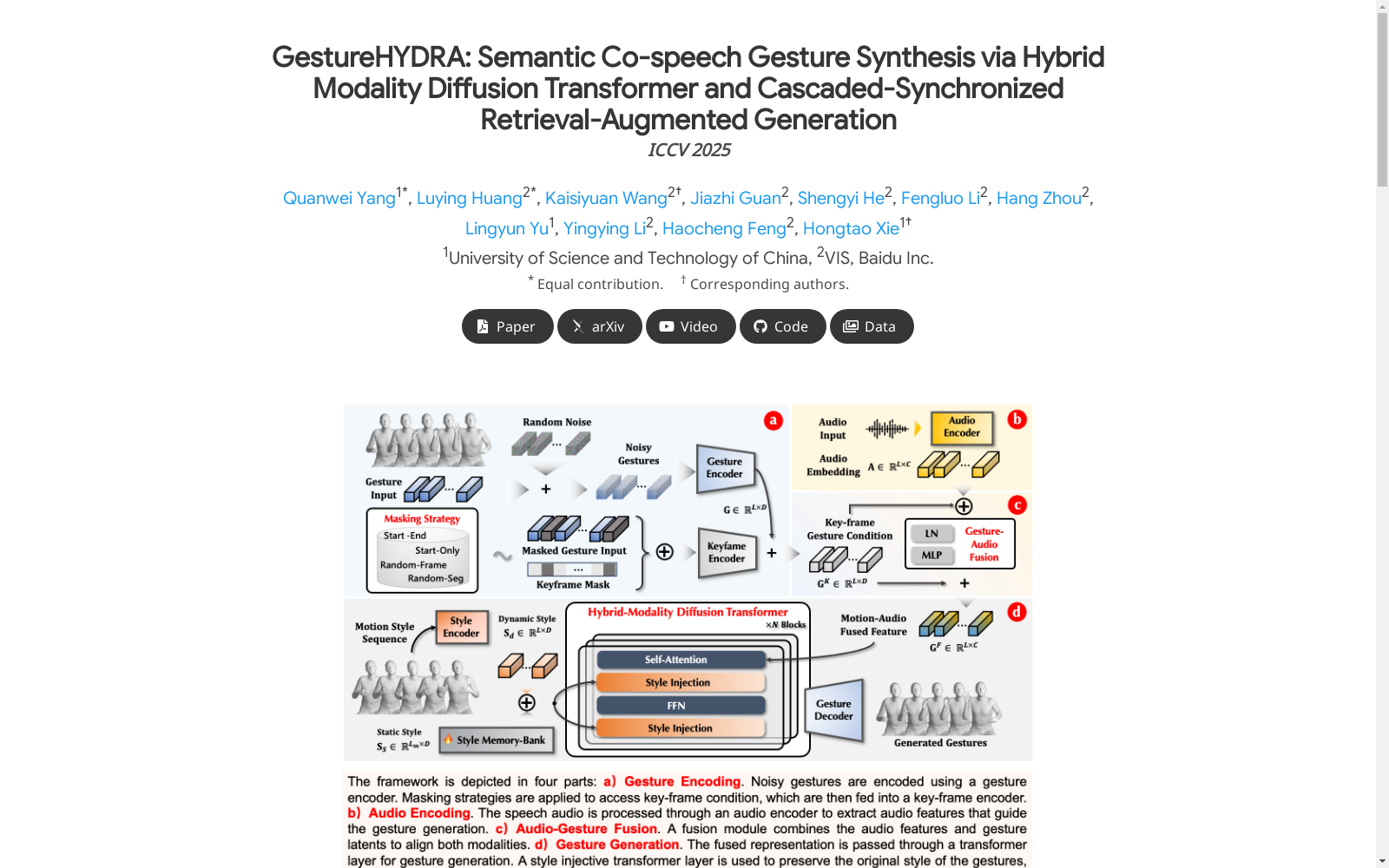
- 系统架构:
- 基于混合模态扩散变换器架构
- 包含新颖设计的运动风格注入变换器层
- 关键技术:
- 级联检索增强生成策略
- 自适应音频-手势同步机制
- 语义手势库
实验结果
- 比较数据集:
- TalkSHOW数据集
- Streamer数据集
- 生成结果展示:
- 自适应关键帧注入结果
- 手势编辑结果
- 基于合成手势的视频生成
引用格式
bibtex @inproceedings{yang2025GestureHYDRA, author = {Quanwei Yang, Luying Huang, Kaisiyuan Wang, Jiazhi Guan, Shengyi He, Fengguo Li, Lingyun Yu, Yingying Li, Haocheng Feng, Hang Zhou, Hongtao Xie.}, title = {GestureHYDRA: Semantic Co-speech Gesture Synthesis via Hybrid Modality Diffusion Transformer and Cascaded-Synchronized Retrieval-Augmented Generation}, booktitle = {ICCV}, year = {2025}, }
许可信息
- 许可证类型: Creative Commons Attribution-ShareAlike 4.0 International License
搜集汇总
数据集介绍
构建方式
Streamer数据集的构建基于直播场景下语义明确的手势捕捉,通过高清摄像机在光线充足的演播室环境中录制单人主播的视频。数据集包含281名演员的20,969个十秒短视频片段,帧率为25fps,音频采样率为22kHz。研究团队采用ASR技术将音频转换为文本,并定位特定触发词(如数字、方向等)对应的片段,通过DWPose检测手势与预定义模板的相似性,最终利用hamer算法重建SMPL-X参数形成3D人体运动数据。
特点
该数据集的核心特点在于其专注语义明确的手势标注,包含18类预定义手势(如数字1-10、方位指示、问候/拒绝等),覆盖58小时视频时长。相比传统对话型手势数据集,Streamer特别强化了教学性手势的密度与多样性,每个语义类别至少包含持续1秒的典型动作片段。数据集采用混合模态存储,同步包含3D人体参数、语音音频及文本转录,且通过运动风格编码实现了跨身份泛化能力,为语义手势生成研究提供了丰富的监督信号。
使用方法
使用Streamer数据集时,可通过两种模式驱动手势生成:基于纯语音输入的"Start-Only"模式,或结合关键帧掩码的检索增强生成模式。研究团队配套开发的GestureHYDRA系统支持语义手势库检索、自适应时间戳调整等功能,用户可输入语音音频后,通过ASR识别语义片段,从预构建的个性化手势库中检索匹配模板,再经运动扩散变换器生成节奏同步的3D动作。该系统还支持运动风格迁移、片段修复等扩展功能,满足数字人创作、虚拟主播等场景需求。
背景与挑战
背景概述
Streamer数据集由百度公司与中国科学技术大学的研究团队于2025年联合创建,专注于语义明确的伴随语音手势合成研究。该数据集创新性地捕捉了网络直播场景中常用的18类指令性手势(如数字指示、方向指引等),填补了现有数据集中语义手势样本稀缺的空白。通过281名主播的58小时高精度动作捕捉,构建了包含20,969段视频片段的资源库,其SMPL-X参数化建模为语音-手势跨模态研究提供了标准化基准。该数据集推动了数字人交互、虚拟主播等领域的语义手势生成技术发展,相关成果发表于计算机视觉顶会CVPR。
当前挑战
构建Streamer数据集面临双重挑战:在领域问题层面,需解决语义手势与语音的复杂多模态映射关系,传统方法难以捕捉"一对多"的语音-手势对应规律;在数据构建层面,存在高精度3D手势标注成本高昂、直播场景动作快速变化导致的运动模糊等问题。研究团队通过混合模态扩散变换器架构和级联检索增强生成策略,有效提升了语义手势的激活准确率与时序同步性,但动态面部表情缺失和语音识别误差传导仍是待突破的技术难点。
常用场景
经典使用场景
Streamer数据集在语音驱动手势生成领域具有广泛的应用,特别是在直播场景中。该数据集捕捉了大量具有明确语义的手势,如数字、方向等,这些手势在直播中频繁出现,用于增强信息传递的效率和准确性。通过结合语音音频和手势数据,研究者可以训练模型生成与语音内容高度同步且语义明确的手势,从而提升虚拟主播或数字人的表现力和自然度。
实际应用
Streamer数据集在实际应用中具有广泛的价值,特别是在虚拟主播、数字人和人机交互领域。通过利用该数据集训练的模型,开发者可以创建能够自然生成语义手势的虚拟角色,从而提升用户体验。例如,在直播或在线教育场景中,虚拟主播可以通过手势更清晰地传达信息,如指示价格或方向。此外,该数据集还可用于机器人交互,使机器人能够通过手势更有效地与人类沟通。
衍生相关工作
Streamer数据集衍生了多项相关经典工作,特别是在语音驱动手势生成和检索增强生成领域。例如,基于该数据集提出的GestureHYDRA系统通过混合模态扩散变换器和级联同步检索增强生成策略,显著提升了手势生成的语义准确性和同步性。此外,该数据集还启发了后续研究,如结合大型语言模型(LLM)进行语义检索的手势生成方法,进一步推动了语音驱动手势生成技术的发展。
以上内容由遇见数据集搜集并总结生成


