cambridgeltl/xcopa
收藏Hugging Face2024-01-04 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/cambridgeltl/xcopa
下载链接
链接失效反馈官方服务:
资源简介:
XCOPA:一个用于因果常识推理的多语言数据集。跨语言合理选择替代方案数据集(XCOPA)是一个用于评估机器学习模型在跨语言环境中进行常识推理能力的基准数据集。该数据集是对英文COPA数据集(Roemmele et al. 2011)的翻译和重新标注,涵盖了来自11个语系的11种语言。该数据集具有挑战性,因为它既需要掌握世界知识,又需要具备跨语言泛化的能力。关于XCOPA的创建和基线实现的详细信息可在相关论文中找到。
XCOPA:一个用于因果常识推理的多语言数据集。跨语言合理选择替代方案数据集(XCOPA)是一个用于评估机器学习模型在跨语言环境中进行常识推理能力的基准数据集。该数据集是对英文COPA数据集(Roemmele et al. 2011)的翻译和重新标注,涵盖了来自11个语系的11种语言。该数据集具有挑战性,因为它既需要掌握世界知识,又需要具备跨语言泛化的能力。关于XCOPA的创建和基线实现的详细信息可在相关论文中找到。
提供机构:
cambridgeltl
原始信息汇总
数据集概述
数据集名称: XCOPA
数据集别名: xcopa
数据集ID: paperswithcode_id: xcopa
数据集描述: XCOPA是一个多语言数据集,用于评估机器学习模型在不同语言间转移常识推理的能力。该数据集是对英语COPA数据集的翻译和重新注释,涵盖了来自11个语系的11种语言。
数据集特征
- 多语言性: 数据集支持多种语言,包括et, ht, id, it, qu, sw, ta, th, tr, vi, zh。
- 许可证: 数据集使用CC-BY-4.0许可证。
- 任务类别: 数据集主要用于问答任务,特别是多选题问答(multiple-choice-qa)。
数据集结构
- 数据实例: 每个语言配置下,数据集分为验证集和测试集。
- 数据字段: 每个实例包含premise, choice1, choice2, question, label, idx, changed等字段,均为文本或整数类型。
- 数据分割: 每个语言配置下,验证集包含100个实例,测试集包含500个实例。
数据集大小
- 下载大小: 不同语言配置的下载大小在50346至91348字节之间。
- 数据集大小: 不同语言配置的数据集大小在66105至213107字节之间。
数据集配置
- 配置名称: 每个语言或其翻译版本都有一个配置名称,如et, ht, id等。
- 数据文件: 每个配置下的数据文件按验证集和测试集分割,路径格式为语言代码/分割类型-*。
数据集示例
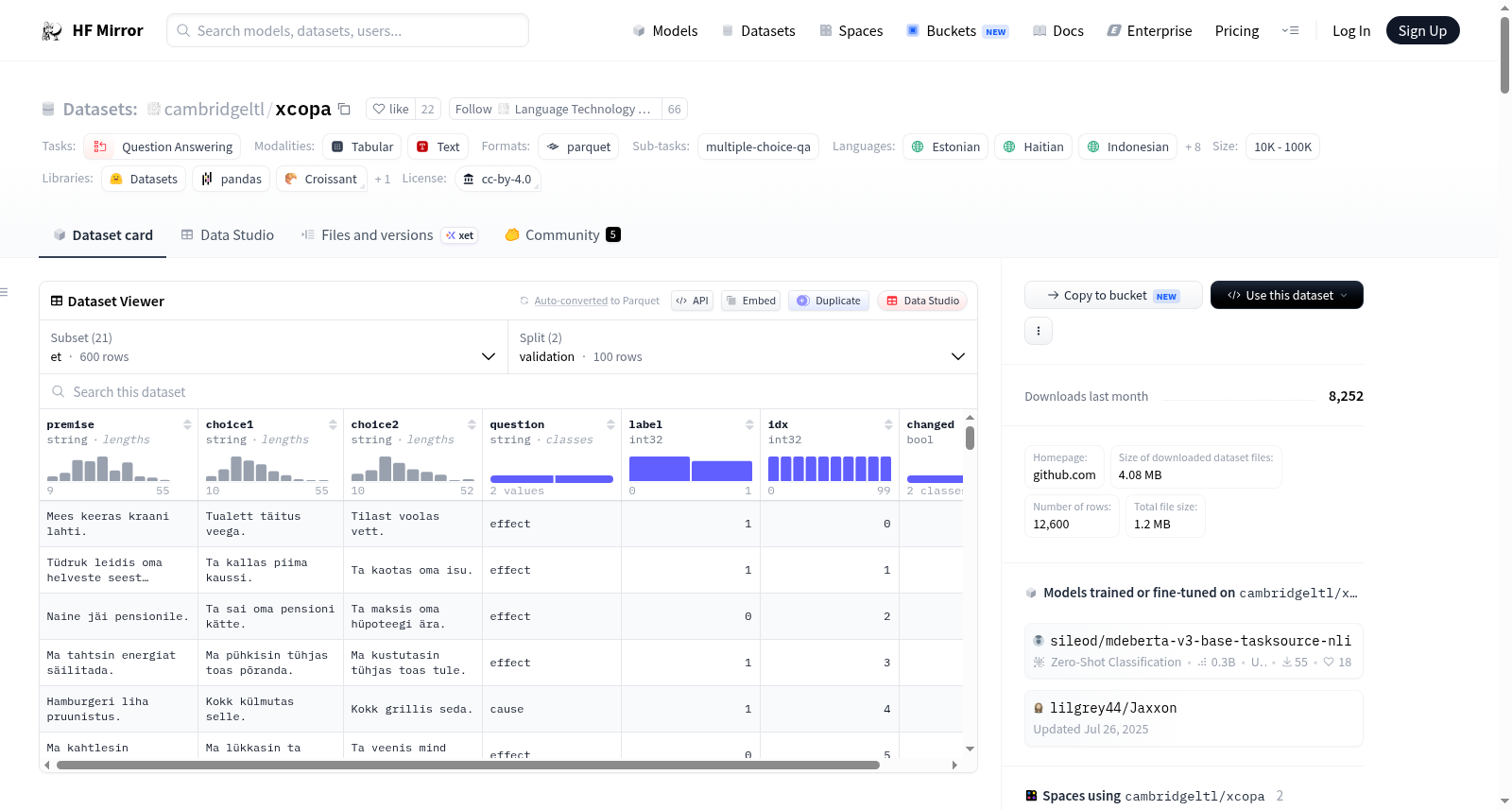
以et语言配置为例,验证集的一个数据实例如下:
{ "changed": false, "choice1": "Ta kallas piima kaussi.", "choice2": "Ta kaotas oma isu.", "idx": 1, "label": 1, "premise": "Tüdruk leidis oma helveste seest putuka.", "question": "effect" }
此概述提供了XCOPA数据集的关键信息,包括其多语言特性、结构、大小和配置细节。
搜集汇总
数据集介绍
背景与挑战
背景概述
XCOPA是一个多语言因果常识推理数据集,基于英文COPA数据集翻译和重新标注,涵盖11种语言,用于评估机器学习模型在跨语言环境中的常识推理迁移能力。数据集包含前提、两个备选答案和问题类型(原因或结果),总共有12,600行数据,支持多项选择题回答任务。
以上内容由遇见数据集搜集并总结生成


