Arranged and Organized Extraction Benchmark (AOE)
收藏arXiv2025-07-22 更新2025-07-24 收录
下载链接:
https://huggingface.co/datasets/tianyumyum/AOE
下载链接
链接失效反馈官方服务:
资源简介:
AOE数据集是一个双语的基准数据集,旨在评估大型语言模型(LLMs)理解碎片化文档并将孤立信息重构为有序表格的能力。该数据集包括来自学术、法律和金融三个不同领域的文档和数据,每个领域都提供了独特的挑战,反映了现实世界的应用场景。AOE包含了11个精心设计的任务,要求模型生成针对不同输入查询的特定上下文表格模式。数据集的创建过程严格遵循真实性、完整性和挑战性的原则,确保了模型能够从复杂的真实世界文本中提取出细粒度、可验证的 structured 数据。AOE数据集的应用领域包括学术研究、法律分析和金融分析等,旨在解决当前LLMs在处理多源知识整合和生成有序输出方面的不足。
The AOE dataset is a bilingual benchmark dataset designed to evaluate the capability of Large Language Models (LLMs) to comprehend fragmented documents and reconstruct isolated information into structured tables. This dataset includes documents and data from three distinct domains: academia, law, and finance, each presenting unique challenges that mirror real-world application scenarios. The AOE dataset features 11 meticulously crafted tasks that require models to generate context-specific table schemas in response to diverse input queries. The development of the AOE dataset strictly adheres to the principles of authenticity, completeness, and challenge, ensuring that models can extract fine-grained, verifiable structured data from complex real-world texts. The AOE dataset has applications in academic research, legal analysis, financial analysis, and other fields, aiming to address the current limitations of LLMs in multi-source knowledge integration and ordered output generation.
提供机构:
中国科学院软件研究所中文信息处理实验室
创建时间:
2025-07-22
原始信息汇总
AOE(Arranged and Organized Extraction)基准数据集概述
1. 数据集简介
- 目的:克服现有文本到表格基准的局限性,挑战现代LLM处理真实、复杂且可解决的数据提取任务。
- 核心原则:
- 来源真实性:所有文档来自真实世界,非合成生成。
- 内容完整性:保留原始文档的长度、结构和复杂性。
- 挑战性与可解性:任务需多种技能,包括模式构建、信息提取、比较和数值推理。
2. 数据来源与收集
- 学术领域:
- 来源:Semantic Scholar、Papers With Code。
- 内容:研究论文、引用元数据和排行榜结果。
- 金融领域:
- 来源:CNINFO。
- 内容:A股公司年度报告(2020-2023)。
- 法律领域:
- 来源:人民法院案例库、中国法律法规数据库。
- 内容:中国民事法律判决和官方法规。
3. 数据处理与标注
- 表格保留:使用工具如
markitdown、Marker和OCR从PDF中准确提取表格。 - 信息标注:人工参与提取关键信息,去除无关细节。
4. 基准任务
- 学术领域:
- 引用上下文提取($Aca_0$)。
- 方法性能提取($Aca_1$)。
- 法律领域:
- 法律条款检索($Legal_0$)。
- 被告判决提取($Legal_1$)。
- 金融领域:
- 单公司纵向分析($Fin_{0-3}$)。
- 跨公司分析($Fin_{4-6}$)。
5. 数据示例
- 金融领域示例:
- 文件名:Gree Electric Appliances, Inc. of Zhuhai 2023 Annual Report。
- 报告期:2023。
- 收入(人民币):203,979,266,387。
- 净利润(人民币):29,017,387,604。
- 经营活动净现金流(人民币):56,398,426,354。
- 法律领域示例:
- 案件名:卫某臣编造虚假恐怖信息案。
- 被告:卫某臣。
- 基本案情:编造虚假恐怖信息导致航班延误。
- 罪名:编造虚假恐怖信息罪。
- 刑期:有期徒刑一年六个月。
搜集汇总
数据集介绍
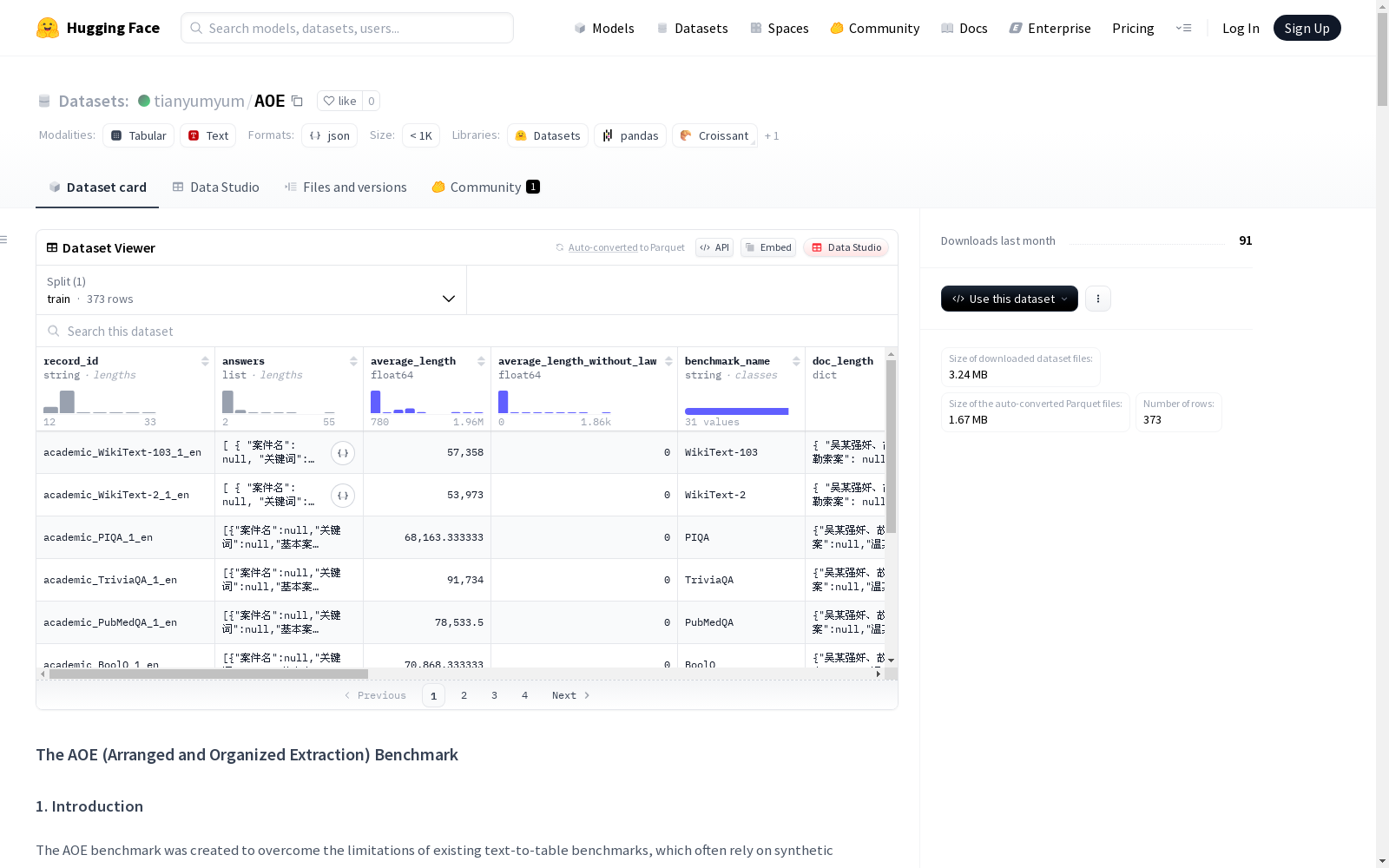
构建方式
Arranged and Organized Extraction Benchmark (AOE) 数据集的构建遵循三个核心原则:源数据真实性、内容完整性和任务可解性。首先,所有文档均来自真实网络资源,涵盖学术、法律和金融三大领域,确保了数据的现实代表性。其次,通过专业工具(如markitdown和Marker pipeline)完整保留原始文档结构,并采用人工参与的标注流程对法律文书进行精细化处理,确保语义关系的完整性。最后,通过设计11项跨领域任务,覆盖从单一文档分析到多文档信息整合的不同复杂度需求,构建了兼具挑战性和可操作性的评估体系。
特点
AOE 数据集具有三个显著特征:跨领域多语言性、长上下文复杂性和动态模式生成要求。作为双语(中英文)基准,其文档平均长度达171K tokens,远超现有文本到表格任务的数据规模。独特之处在于突破了固定模式的限制,要求模型根据查询动态构建表结构,并完成细粒度信息提取。数据分布上,金融领域文档最长(平均437K tokens),法律领域文档数量最多(713份),学术领域则侧重跨文献关联分析,形成了多维度的评估场景。
使用方法
使用AOE 数据集需遵循三步评估流程:首先通过CSV可解析性检测输出结构合规性;其次采用LLM评分从意图理解、模式构建等四个维度评估表格整体质量;最后通过细胞级F1值精确量化内容提取准确率。评估时需注意:1)需对比模型在链式思考(CoT)提示下的表现差异;2)金融领域任务涉及跨年度数值计算,需验证公式正确性;3)法律条文检索任务要求语义匹配而非简单关键词匹配。数据集支持端到端评估管道,可直接调用HuggingFace接口获取标准化测试用例。
背景与挑战
背景概述
Arranged and Organized Extraction Benchmark (AOE) 是由中国科学院软件研究所中文信息处理实验室的研究团队于2025年提出的双语基准测试数据集,旨在系统评估大语言模型(LLMs)从复杂现实文档中提取显式信息并重构为结构化表格的能力。该数据集包含学术、法律和金融三个领域的11项任务,要求模型根据多样化输入查询生成特定上下文的表格模式。AOE的提出填补了传统文本到表格任务依赖固定模式和狭窄任务领域的不足,推动了模型生成更具结构化和可验证性的输出。
当前挑战
AOE数据集面临的挑战主要体现在两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,AOE旨在解决从复杂、碎片化的多源文档中提取信息并组织成结构化表格的核心问题,这要求模型具备跨文档理解、细粒度信息提取和多步推理能力。在构建过程中,研究团队面临真实文档来源的多样性处理、长文档(平均17.1万token)的信息完整性保持,以及跨领域任务设计的复杂性等挑战。此外,数据集的标注过程需要高度专业化的领域知识,特别是在法律和金融领域,确保提取信息的准确性和一致性成为关键难点。
常用场景
经典使用场景
在信息爆炸的时代,专业研究人员、金融分析师和商业策略师经常面临来自多源文档的碎片化信息整合挑战。Arranged and Organized Extraction Benchmark (AOE) 数据集通过设计11个跨学术、法律和金融领域的任务,系统评估大型语言模型(LLMs)从复杂文档中提取信息并重构为结构化表格的能力。其经典使用场景包括学术论文的引用关系提取、法律条款检索以及公司财务数据的纵向与横向分析。
解决学术问题
AOE数据集解决了当前LLMs在结构化知识提取中的核心问题,包括模型生成的段落式回答混乱无序、难以追溯的缺陷。通过要求模型动态构建表格模式并填充精确提取的信息,AOE推动了模型向更具结构化和可用性输出的发展。该数据集填补了传统文本到表格任务依赖固定模式、短输入和狭窄领域的不足,为跨文档信息整合提供了系统化评估框架。
衍生相关工作
AOE催生了多项重要研究工作,包括Deepseek-R1等模型在跨文档推理上的优化,以及TKGT等将知识图谱增强LLMs应用于文本到表格任务的新方法。相关衍生工作如Text-Tuple-Table提出了全局元组提取框架,而StructRAG则探索了推理时混合信息结构化的增强策略,这些进展共同推动了复杂结构化知识提取领域的发展。
以上内容由遇见数据集搜集并总结生成


