digikala-comments
收藏Hugging Face2025-12-22 更新2025-12-23 收录
下载链接:
https://huggingface.co/datasets/EhsanShahbazi/digikala-comments
下载链接
链接失效反馈官方服务:
资源简介:
Digikala所有评论数据集包含来自Digikala购物平台的用户评论数据,涵盖了评论ID、产品ID、评分、评论用户类型、是否匿名、用户ID、评论内容、点赞数、点踩数、用户名、创建时间、关注数、粉丝数等多个特征。该数据集支持多种自然语言处理任务,如文本分类、特征提取、文本生成等。数据语言主要为波斯语和英语,数据集规模在10M到100M之间。
The Digikala All Reviews Dataset consists of user review data sourced from the Digikala e-commerce platform, covering multiple features including review ID, product ID, rating, commenter user type, anonymity status, user ID, review content, like count, dislike count, username, creation time, following count, and follower count. This dataset supports various natural language processing tasks such as text classification, feature extraction, and text generation. The primary languages of the data are Persian and English, and the dataset scale ranges from 10 million to 100 million.
创建时间:
2025-12-21
原始信息汇总
Digikala Comments 数据集概述
数据集基本信息
- 数据集名称: digikala all comments
- 发布者: EhsanShahbazi
- 托管地址: https://huggingface.co/datasets/EhsanShahbazi/digikala-comments
- 许可证: mit
- 数据规模: 10M<n<100M(大规模)
数据内容与结构
- 数据来源: Digikala(一个购物平台)
- 核心内容: 商品评论
- 数据格式: Parquet文件(digikala-comments.parquet)
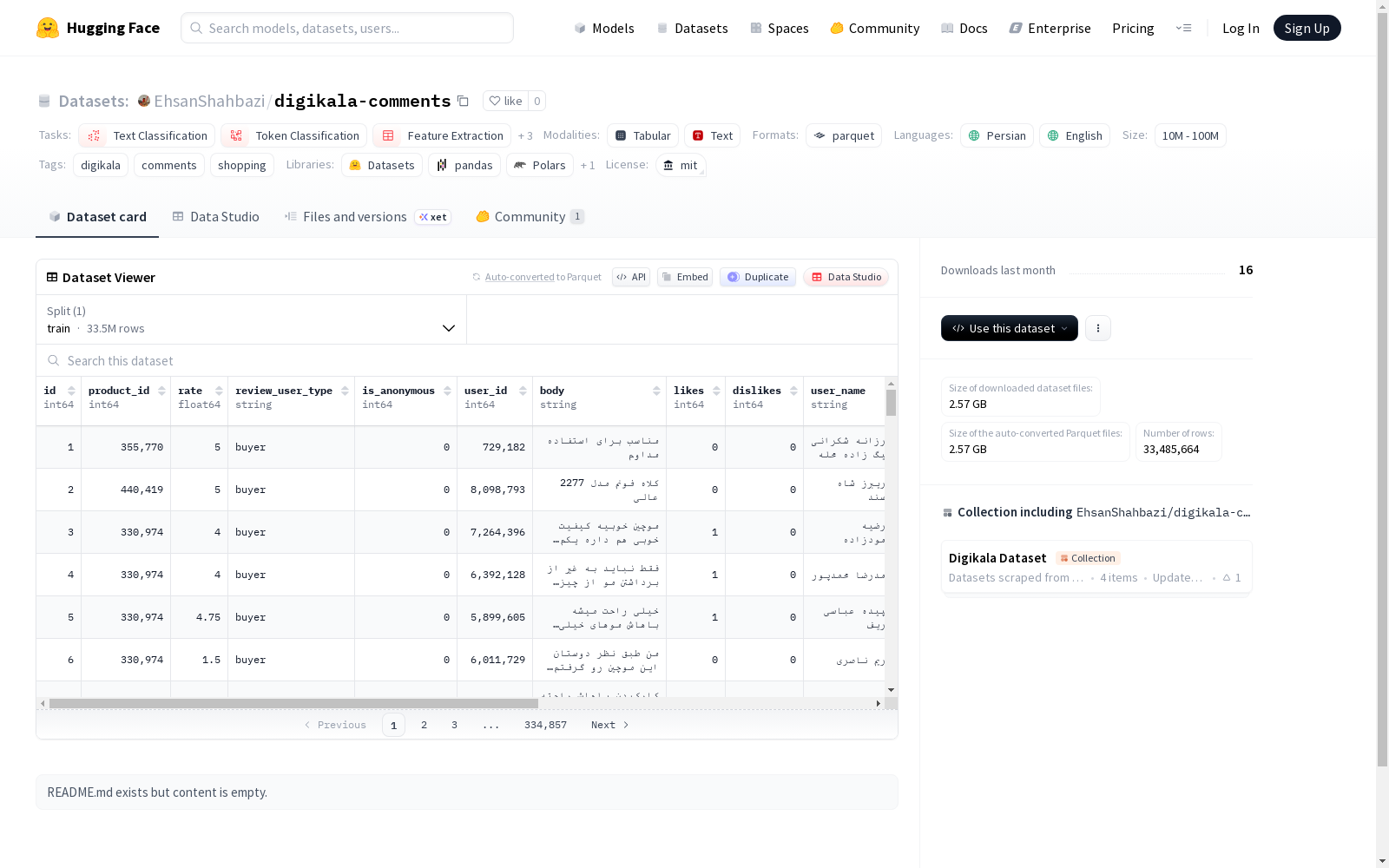
- 数据总量: 33,485,664 条样本
- 数据划分: 仅包含一个“train”划分
数据字段说明
数据集包含以下16个字段:
id: 评论ID(int64)product_id: 商品ID(int64)rate: 评分(float64)review_user_type: 评论用户类型(string)is_anonymous: 是否为匿名评论(int64)user_id: 用户ID(int64)body: 评论正文(string)likes: 点赞数(int64)dislikes: 点踩数(int64)user_name: 用户名(string)created_at: 评论创建时间(string)followings_count: 用户关注数(float64)followers_count: 用户粉丝数(float64)source_file: 源文件(string)__index_level_0__: 索引级别(int64)
语言与任务
- 主要语言: 波斯语(fa)、英语(en)
- 适用任务:
- 文本分类
- 令牌分类
- 特征提取
- 文本生成
- 句子相似度
- 摘要生成
标签
- digikala
- comments
- shopping
搜集汇总
数据集介绍
构建方式
在电子商务研究领域,大规模用户评论数据对于理解消费者行为至关重要。Digikala-comments数据集通过系统性地采集伊朗领先电商平台Digikala上的用户评论构建而成,其数据来源于平台公开的用户生成内容,涵盖了从产品评价到用户互动的多维信息。构建过程中,原始评论数据经过结构化处理,转化为包含产品标识、评分、文本内容及用户社交指标等丰富特征的标准化格式,并以Parquet文件高效存储,确保了数据的完整性与可访问性。
特点
该数据集以其规模宏大和语言多样性著称,包含超过3300万条评论实例,主要使用波斯语和英语,为中东地区的自然语言处理研究提供了珍贵资源。其特点在于不仅提供了评论文本和数值评分,还整合了用户类型、匿名状态、点赞与点踩数量以及用户社交网络指标等细粒度元数据,支持从情感分析、用户画像构建到社交影响力评估等多维度分析任务。这种综合性的特征设计使得数据集能够适应文本分类、特征提取和文本生成等多种自然语言处理应用场景。
使用方法
研究人员和开发者可通过Hugging Face平台直接加载该数据集,利用其预定义的训练分割进行模型训练与评估。在实际应用中,该数据集适用于训练情感分析模型以洞察消费者意见,或用于用户行为预测及推荐系统优化。其丰富的元数据字段允许进行复杂的特征工程,例如结合用户社交指标与评论内容进行联合建模。由于数据规模庞大,建议采用分布式处理或抽样技术以提高计算效率,同时应注意遵守平台许可协议,确保数据使用的合规性与伦理性。
背景与挑战
背景概述
Digikala-comments数据集由伊朗领先的电子商务平台Digikala于2023年发布,旨在为波斯语自然语言处理研究提供大规模、高质量的在线评论资源。该数据集汇集了超过3300万条用户评论,涵盖了丰富的产品类别与用户交互信息,如评分、点赞数及用户社交属性。其核心研究问题聚焦于多语言环境下的情感分析、用户行为建模及文本生成任务,为中东地区数字商务与计算语言学领域填补了数据空白,显著推动了跨文化语境下的机器学习应用发展。
当前挑战
该数据集致力于解决波斯语电子商务评论中的细粒度情感分析与用户可信度评估等复杂问题,其挑战在于处理波斯语特有的语法结构、混合代码(如波斯语-英语混杂文本)以及非正式表达带来的语义歧义。在构建过程中,数据采集面临用户隐私保护与匿名化处理的平衡难题,同时需克服大规模评论数据中的噪声过滤、重复内容识别以及时间序列动态演化的整合困难,这些因素共同影响了数据集的标注一致性与模型泛化能力。
常用场景
经典使用场景
在电子商务与自然语言处理交叉领域,Digikala-comments数据集作为波斯语用户评论的丰富资源,常被用于情感分析与意见挖掘研究。该数据集包含大量商品评分与文本评论,使得研究者能够构建模型以自动识别用户对产品的积极或消极态度,进而评估商品口碑与市场反馈。其多语言特性,尤其是波斯语内容,为低资源语言处理提供了宝贵语料,推动了跨语言情感分析技术的发展。
衍生相关工作
基于Digikala-comments数据集,学术界衍生了一系列经典研究工作,包括波斯语预训练语言模型的开发、多模态情感分析框架的构建以及跨领域迁移学习方法的探索。这些工作不仅拓展了数据集的利用维度,还促进了中东地区数字人文研究的发展,为全球自然语言处理社区贡献了独特的文化视角与技术解决方案。
数据集最近研究
最新研究方向
在电子商务与自然语言处理交叉领域,digikala-comments数据集凭借其大规模波斯语评论内容,正推动多语言情感分析与用户行为建模的前沿探索。研究者聚焦于跨语言迁移学习,利用该数据集训练模型以处理低资源语言环境下的细粒度情感分类,同时结合用户社交互动特征如点赞与关注数,深入挖掘评论影响力与购买决策的关联机制。近期热点事件如中东电商市场的快速增长,进一步凸显了此类本土化数据集在优化推荐系统、检测虚假评论以及增强跨文化用户体验方面的关键意义,为全球NLP社区提供了宝贵的非英语语料资源。
以上内容由遇见数据集搜集并总结生成


