BirdSet
收藏Hugging Face2026-01-18 更新2026-01-19 收录
下载链接:
https://huggingface.co/datasets/mteb/BirdSet
下载链接
链接失效反馈官方服务:
资源简介:
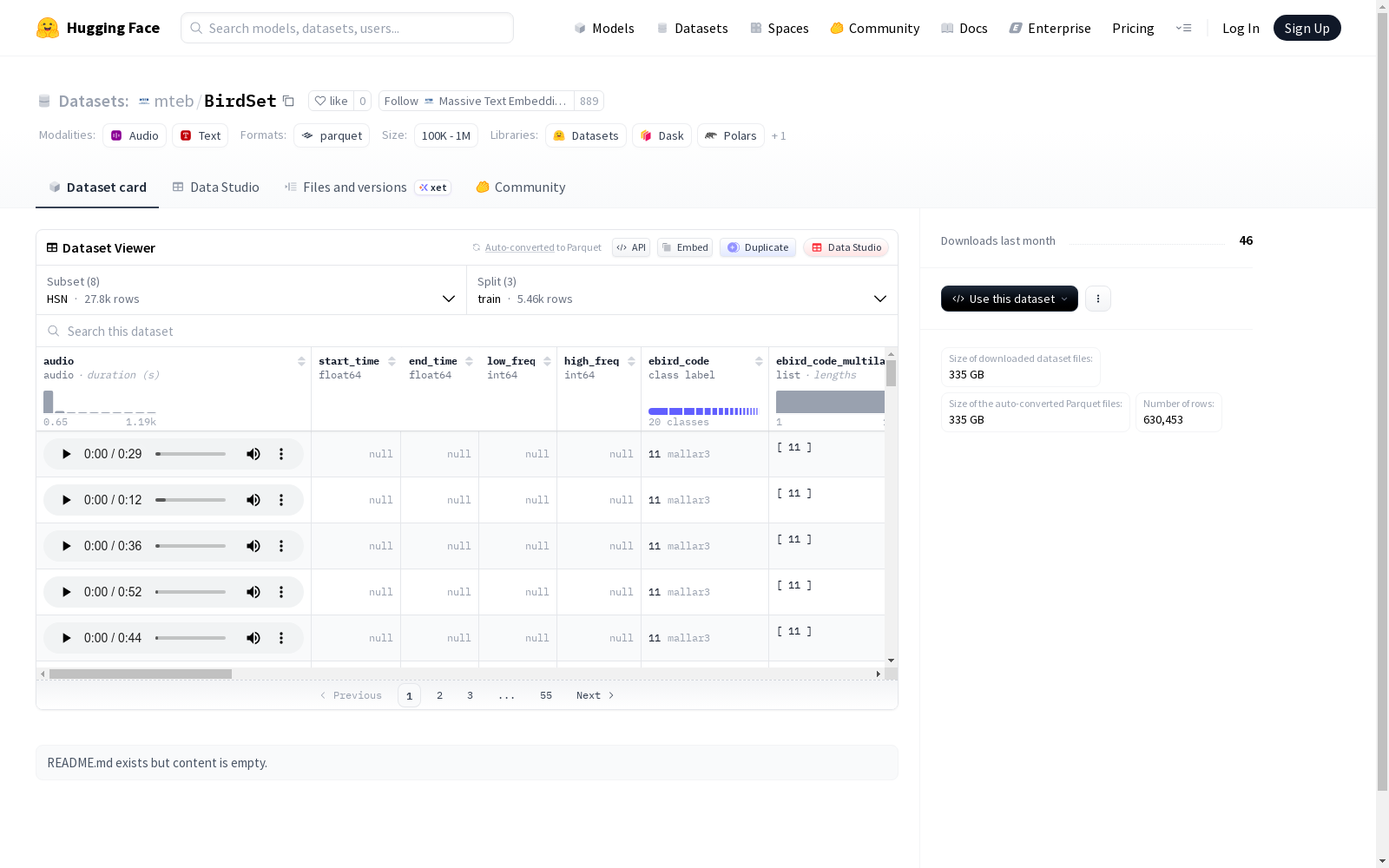
该数据集包含三种配置(HSN、NBP、NES)的鸟类声音记录,每种配置都包含音频文件及其相关元数据。音频采样率为32000 Hz,元数据包括时间戳、频率范围、鸟类物种代码(ebird_code)、多标签分类、叫声类型、性别、地理坐标、录音设备信息以及分类学信息(属、物种组、目)。每种配置都分为训练集、测试集和test_5s子集,并提供了各自的大小和样本数量。该数据集专注于鸟类发声,为生态学和生物声学研究提供了全面的标注信息。
This dataset contains bird sound recordings under three configurations (HSN, NBP, and NES), each of which includes audio files and their associated metadata. The audio sampling rate is 32000 Hz, and the metadata includes timestamp, frequency range, bird species code (ebird_code), multi-label classification, call type, gender, geographic coordinates, recording device information, and taxonomic information (genus, species group, order). Each configuration is divided into training set, test set, and test_5s subset, with their respective sizes and sample counts provided. This dataset focuses on bird vocalizations and provides comprehensive annotated information for ecological and bioacoustic research.
创建时间:
2026-01-17
原始信息汇总
BirdSet 数据集概述
数据集基本信息
- 数据集地址: https://huggingface.co/datasets/mteb/BirdSet
- 配置数量: 3个独立配置(HSN、NBP、NES)
- 音频采样率: 所有配置均为32000 Hz
配置详情
HSN 配置
- 数据划分:
- 训练集: 5460个样本,占用空间约2.59 GB
- 测试集: 10296个样本,占用空间约45.73 GB
- 5秒测试集: 12000个样本,占用空间约486.91 MB
- 下载大小: 约7.90 GB
- 总数据集大小: 约48.81 GB
- 鸟类物种数量: 21种(ebird_code类别)
- 分类层级:
- 属(genus): 20个类别
- 物种组(species_group): 14个类别
- 目(order): 4个类别
NBP 配置
- 数据划分:
- 训练集: 24327个样本,占用空间约20.12 GB
- 测试集: 539个样本,占用空间约21.90 MB
- 5秒测试集: 539个样本,占用空间约21.95 MB
- 下载大小: 约33.10 GB
- 总数据集大小: 约20.16 GB
- 鸟类物种数量: 51种(ebird_code类别)
- 分类层级:
- 属(genus): 46个类别
- 物种组(species_group): 25个类别
- 目(order): 4个类别
NES 配置
- 数据划分: 仅提供特征结构定义,未包含划分大小和样本数量信息
- 鸟类物种数量: 89种(ebird_code类别)
- 分类层级:
- 属(genus): 62个类别
特征结构
所有配置共享以下特征字段:
音频与时间信息
audio: 音频数据(采样率32000 Hz)start_time: 开始时间(浮点数)end_time: 结束时间(浮点数)low_freq: 低频边界(整数)high_freq: 高频边界(整数)length: 长度(整数)
鸟类分类信息
ebird_code: 鸟类物种代码(主标签)ebird_code_multilabel: 鸟类物种代码(多标签序列)ebird_code_secondary: 次要鸟类物种代码(字符串序列)genus: 属分类(类别标签)genus_multilabel: 属分类(多标签序列)species_group: 物种组分类(类别标签)species_group_multilabel: 物种组分类(多标签序列)order: 目分类(类别标签)order_multilabel: 目分类(多标签序列)
元数据信息
call_type: 叫声类型(字符串)sex: 性别(字符串)lat: 纬度(浮点数)long: 经度(浮点数)microphone: 麦克风信息(字符串)license: 许可协议(字符串)source: 数据来源(字符串)local_time: 本地时间(字符串)quality: 质量评级(字符串)recordist: 记录者(字符串)
事件检测信息
detected_events: 检测到的事件(浮点数序列的序列)event_cluster: 事件聚类(整数序列)peaks: 峰值(浮点数序列)
搜集汇总
数据集介绍
构建方式
在生物声学研究领域,BirdSet数据集通过系统化采集与标注流程构建而成。该数据集整合了多个区域性鸟类鸣声记录,包括北美、欧洲和尼加拉瓜等地的物种。音频数据以32kHz采样率统一处理,每条记录均标注了精确的时间戳、频率范围及物种分类信息。数据来源涵盖专业录音师采集的野外录音,并遵循标准化的元数据标注体系,确保数据的科学性与可追溯性。
特点
BirdSet数据集展现出多层次标注的显著特征,涵盖从物种到属、科、目的完整分类体系。每个音频样本不仅包含核心物种标签,还提供性别、鸣叫类型、地理位置等生态学属性。数据集采用单标签与多标签并行的标注策略,支持复杂声学场景下的物种共现分析。音频片段均经过事件检测与质量评估,为机器学习模型提供了丰富的结构化特征。
使用方法
该数据集适用于鸟类声学识别与生态监测研究,用户可通过HuggingFace平台直接加载HSN、NBP、NES等区域子集。研究人员可利用预划分的训练集与测试集开发自动识别模型,或通过多标签字段研究物种间的声学交互关系。数据集提供的时空信息支持生物地理学分析,而标准化的音频格式便于与主流声学处理框架集成。
背景与挑战
背景概述
鸟类声学监测作为生物多样性研究的关键领域,近年来因深度学习技术的兴起而备受关注。BirdSet数据集应运而生,由生态学与计算机科学交叉领域的研究团队构建,旨在通过大规模、高质量的鸟类音频样本,推动自动鸟类识别算法的发展。该数据集整合了多个区域子集,如HSN、NBP和NES,涵盖了从物种到属、科乃至目级的系统分类标签,并辅以地理坐标、录音设备等元数据,为模型训练提供了丰富的上下文信息。其核心研究问题聚焦于利用机器学习技术,从复杂自然环境录音中精准识别鸟类物种,进而支持生物多样性评估与保护决策。BirdSet的发布显著降低了鸟类声学自动识别的技术门槛,为生态学研究提供了标准化数据基础。
当前挑战
在鸟类声学识别领域,主要挑战在于环境噪声干扰、鸟类鸣声的种内变异以及多物种重叠鸣叫的分离问题。BirdSet数据集旨在解决这些难题,但构建过程本身亦面临诸多困难。数据收集需在多样化的自然栖息地进行,录音质量受天气、背景生物声学及设备差异的影响,导致音频样本的信噪比不均。此外,鸟类鸣声标注依赖专家听辨,耗时耗力且易受主观判断影响,确保标注一致性与准确性成为关键瓶颈。数据集的规模与多样性平衡亦需考量,既要覆盖广泛物种,又需保证每类样本的充分代表性,以应对模型泛化需求。
常用场景
经典使用场景
在生物声学与计算生态学领域,BirdSet数据集为鸟类声音识别研究提供了标准化的基准平台。该数据集通过包含多个地理区域的鸟类音频记录,如北美、欧洲和尼加拉瓜,并标注了丰富的物种分类信息,使得研究人员能够构建和评估深度学习模型,实现高精度的鸟类物种自动识别。其经典使用场景涉及训练卷积神经网络或Transformer架构,以处理音频频谱图,从而在复杂声学环境中准确区分不同鸟类的鸣叫特征。
实际应用
在实际生态监测与保护工作中,BirdSet数据集被广泛应用于自动化鸟类监测系统。例如,在自然保护区或城市公园中部署声学传感器,结合基于该数据集训练的模型,可实时识别和记录鸟类活动,辅助生态学家评估物种分布变化和栖息地健康状况。这种应用不仅提升了监测效率,还降低了人工调查成本,为全球生物多样性保护策略提供了数据支持。
衍生相关工作
基于BirdSet数据集,学术界衍生了一系列经典研究工作,包括开发高效的音频特征提取算法,如Mel频谱图优化方法,以及设计多任务学习框架以同时处理物种识别和鸣叫类型分类。此外,该数据集还促进了跨区域鸟类声学比较研究,例如通过迁移学习技术将模型应用于新地理区域,推动了全球鸟类声学数据库的整合与标准化进程。
以上内容由遇见数据集搜集并总结生成


