olivierdehaene/xkcd
收藏Hugging Face2022-10-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/olivierdehaene/xkcd
下载链接
链接失效反馈官方服务:
资源简介:
XKCD数据集是从explainxkcd.com和xkcd.com抓取的所有XKCD漫画及其文字转录和解释的集合。数据集包含每个漫画的ID、标题、URL、图像URL、解释URL、文字转录和解释。数据集的创建过程涉及从这两个网站抓取数据,并且数据集的部分内容受Creative Commons Attribution-ShareAlike 3.0许可证保护,而图像则受Creative Commons Attribution-NonCommercial 2.5许可证保护。
The XKCD Dataset is a curated collection of all XKCD comics, their full text transcriptions and official explanations, scraped from explainxkcd.com and xkcd.com. For each comic, the dataset contains its unique ID, title, page URL, image URL, explanation URL, text transcription, and written explanation. The dataset was assembled by scraping relevant data from these two websites. Portions of the dataset are protected under the Creative Commons Attribution-ShareAlike 3.0 License, while the comic images themselves are covered by the Creative Commons Attribution-NonCommercial 2.5 License.
提供机构:
olivierdehaene
原始信息汇总
数据集概述:XKCD
数据集描述
数据集摘要
XKCD 数据集包含从 https://explainxkcd.com 抓取的所有 XKCD 漫画及其文本记录和解释。
数据集结构
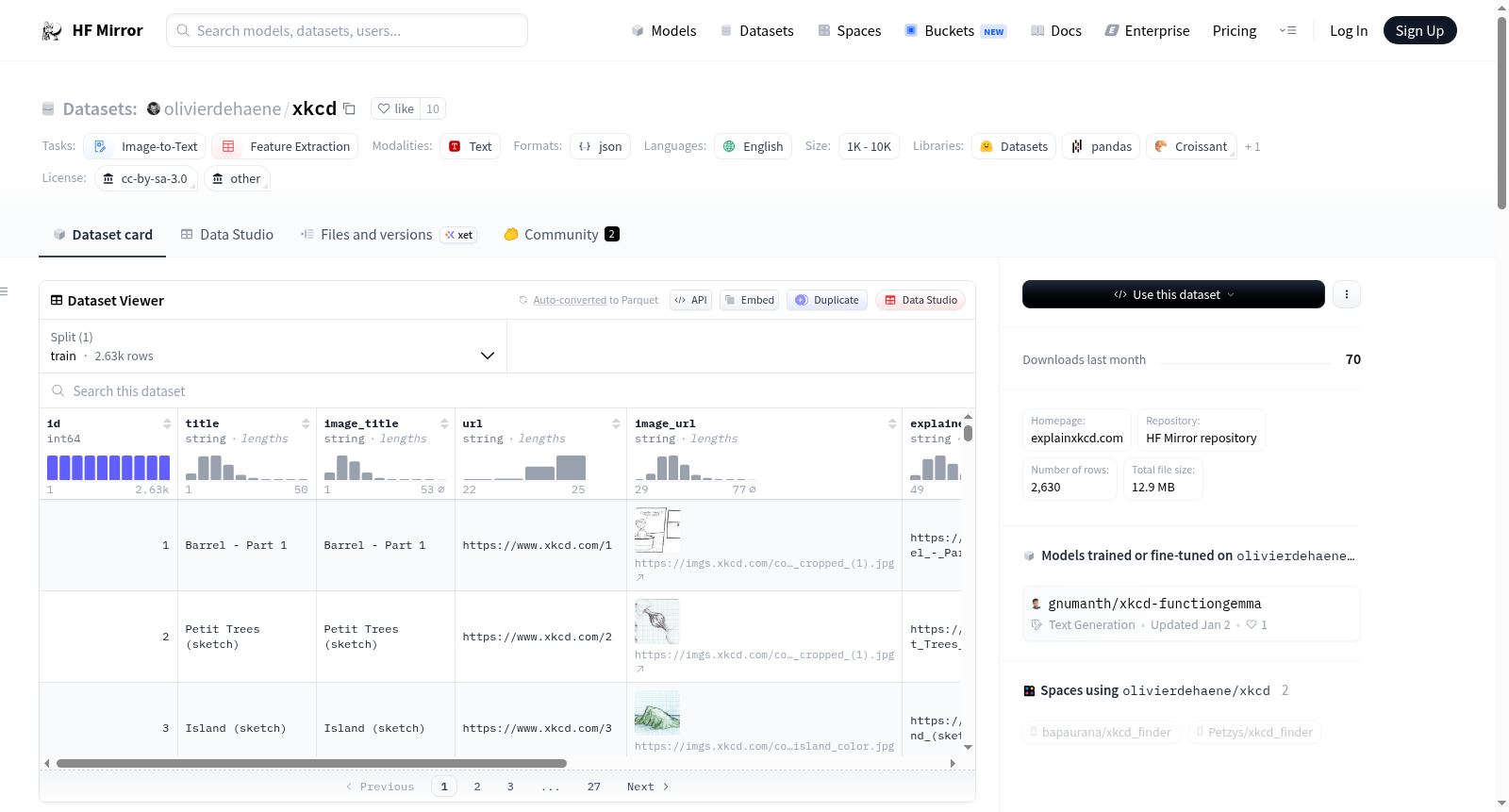
数据实例
idtitleimage_titleurl: xkcd.com URLimage_urlexplained_url: explainxkcd.com URLtranscript: 英文文本记录explanation: 英文解释
数据字段
idtitleurl: xkcd.com URLimage_urlexplained_url: explainxkcd.com URLtranscript: 英文文本记录explanation: 英文解释
数据集创建
数据集从 explainxkcd.com 和 xkcd.com 抓取。文本记录和解释字段根据 Creative Commons Attribution-ShareAlike 3.0 许可授权,而图像则根据 Creative Commons Attribution-NonCommercial 2.5 许可授权。
使用数据的考虑
由于数据是抓取的,某些字段可能缺少原始数据的某些部分。
附加信息
许可信息
数据集的文本记录和解释字段根据 Creative Commons Attribution-ShareAlike 3.0 许可授权,图像则根据 Creative Commons Attribution-NonCommercial 2.5 许可授权。
贡献者
感谢 @OlivierDehaene 添加此数据集。
搜集汇总
数据集介绍
构建方式
在数字漫画与文本分析领域,XKCD数据集通过系统化网络爬取技术构建而成。该过程整合了来自xkcd.com的原始漫画图像及其元数据,同时从explainxkcd.com获取了每幅漫画的文本转录与详细解释。数据采集遵循了网站的结构化特征,确保了漫画、转录文本及解释性内容之间的精确对应,从而形成了一个多模态且注释丰富的语料库。
特点
XKCD数据集以其独特的跨模态结构脱颖而出,涵盖了从首幅漫画至今的完整系列。每一条数据实例均包含漫画图像、标题、URL链接、图像URL、解释页面链接、英文转录文本以及详尽的英文解释。这种设计不仅提供了视觉与文本的双重表征,还通过社区贡献的解释文本深化了语义层次,为图像描述生成、幽默理解及叙事分析等研究任务提供了珍贵资源。
使用方法
该数据集适用于图像到文本转换、特征提取及自然语言理解等多种计算任务。研究者可通过Hugging Face平台直接加载数据集,利用其结构化的字段进行模型训练与评估。鉴于数据包含图像与文本对,可广泛应用于多模态学习框架,如视觉问答、漫画内容生成及语义对齐研究。使用前需注意不同字段遵循的CC BY-SA 3.0与CC BY-NC 2.5许可协议,确保合规使用。
背景与挑战
背景概述
XKCD数据集由Olivier Dehaene于2023年构建,源自著名网络漫画XKCD及其社区解释网站Explain XKCD。该数据集整合了漫画的图像、文本转录与深度解释,旨在为多模态学习与自然语言处理研究提供独特资源。其核心研究问题聚焦于如何通过结构化数据解析视觉叙事与幽默语义,推动图像描述生成、语义理解及文化语境分析等领域的发展。作为首个系统化收录XKCD漫画及其社区注解的开放数据集,它不仅丰富了多模态语料库的多样性,还为研究视觉语言交互与网络文化传播提供了重要基础。
当前挑战
XKCD数据集所针对的领域挑战在于如何精准解析漫画中视觉元素与文本隐喻的复杂关联,尤其是幽默、讽刺等抽象语义的跨模态表征。构建过程中面临多重挑战:其一,数据采集需协调不同版权协议,漫画图像遵循非商业许可,而文本内容采用共享许可,导致使用限制复杂化;其二,网络爬取过程可能遗漏部分字段,影响数据完整性;其三,社区解释文本包含主观解读,需在保持原意的基础上确保标注一致性。这些挑战对数据集的可靠性、法律合规性与学术适用性提出了严格要求。
常用场景
经典使用场景
在自然语言处理与计算机视觉的交叉领域,XKCD数据集以其独特的图文对结构,为多模态学习提供了经典范例。该数据集整合了漫画图像、文本转录及详细解释,常用于训练图像描述生成模型,使机器能够理解视觉内容并生成连贯的文本描述。研究者利用其丰富的语义关联,探索视觉与语言之间的深层对应关系,推动跨模态表示学习的发展。
实际应用
在实际应用层面,XKCD数据集被广泛用于开发智能辅助工具,如视觉障碍者的图像描述系统,将漫画内容转化为可访问的文本叙述。此外,它在教育技术中发挥作用,支持创建交互式学习材料,通过图文结合的方式解释抽象概念。在内容创作领域,该数据集为自动生成插图说明或故事板提供了训练基础,提升了多媒体内容的生成效率与质量。
衍生相关工作
围绕XKCD数据集,衍生出多项经典研究工作,主要集中在多模态预训练模型的开发上。例如,基于该数据集的视觉语言模型被用于改进图像字幕生成技术,增强了模型对幽默、讽刺等复杂语义的捕捉能力。同时,研究者利用其解释文本构建了新的评估基准,测试模型在深层推理任务上的表现,推动了可解释性视觉问答系统的发展,为人工智能理解人类文化表达提供了新途径。
以上内容由遇见数据集搜集并总结生成


