wmt/wmt20_mlqe_task2
收藏Hugging Face2024-04-04 更新2024-04-20 收录
下载链接:
https://hf-mirror.com/datasets/wmt/wmt20_mlqe_task2
下载链接
链接失效反馈官方服务:
资源简介:
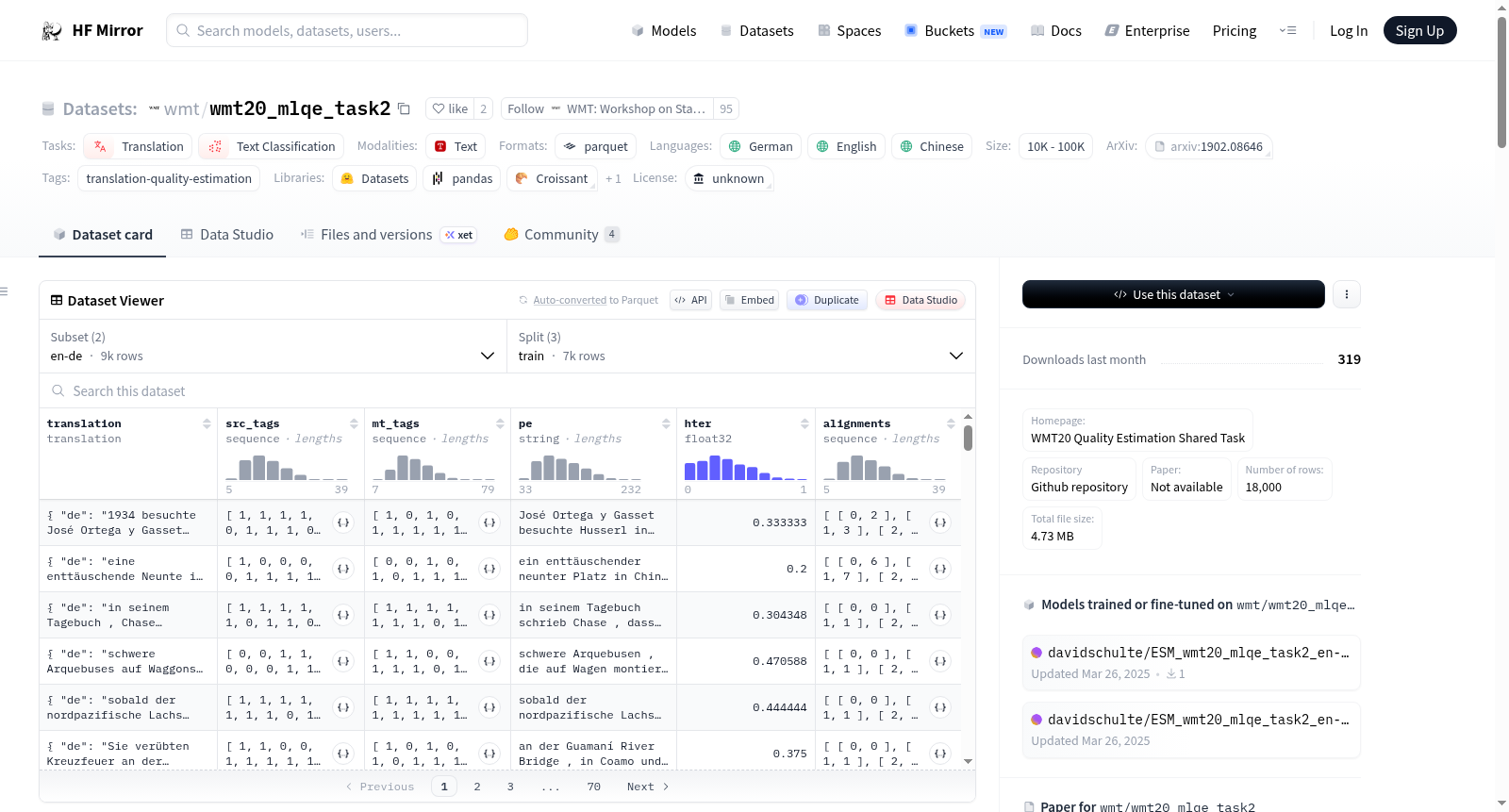
WMT20 - 多语言质量估计(MLQE)任务2数据集主要用于机器翻译质量估计任务。该数据集包含两种语言对:英语-德语(en-de)和英语-中文(en-zh)。数据集的结构包括翻译文本、源语言和目标语言的词级标签、后编辑版本、人类翻译错误率(HTER)以及词对齐信息。数据集分为训练集、验证集和测试集,分别包含7000、1000和1000个样本。数据集的创建基于Wikipedia文章,并通过TER工具进行词级标签的标注。
WMT20 - Multilingual Quality Estimation (MLQE) Task 2 dataset is primarily used for machine translation quality estimation tasks. It contains two language pairs: English-German (en-de) and English-Chinese (en-zh). The dataset structure includes translated texts, word-level labels for source and target languages, post-edited versions, Human Translation Error Rate (HTER), and word alignment information. The dataset is split into training, validation and test sets, which contain 7000, 1000 and 1000 samples respectively. The dataset is constructed based on Wikipedia articles, and the word-level labels are annotated using the TER tool.
提供机构:
wmt
原始信息汇总
数据集概述
- 名称: WMT20 - MultiLingual Quality Estimation (MLQE) Task2
- 语言: 德语 (
de), 英语 (en), 中文 (zh) - 许可证: 未知
- 多语言性: 翻译
- 大小: 1K<n<10K
- 来源数据集: 扩展自维基百科
- 任务类别: 翻译, 文本分类
- 配置名称: en-de, en-zh
- 标签: 翻译质量估计
数据集结构
配置 en-de
- 特征:
- translation: 语言对 (en, de)
- src_tags: 源标签 (
0: BAD,1: OK) - mt_tags: 目标标签 (
0: BAD,1: OK) - pe: 字符串
- hter: 浮点数32位
- alignments: 整数序列
- 分割:
- train: 7000个样本, 6463902字节
- test: 1000个样本, 425042字节
- validation: 1000个样本, 927588字节
- 下载大小: 2284213字节
- 数据集大小: 7816532字节
配置 en-zh
- 特征:
- translation: 语言对 (en, zh)
- src_tags: 源标签 (
0: BAD,1: OK) - mt_tags: 目标标签 (
0: BAD,1: OK) - pe: 字符串
- hter: 浮点数32位
- alignments: 整数序列
- 分割:
- train: 7000个样本, 6786870字节
- test: 1000个样本, 443200字节
- validation: 1000个样本, 954682字节
- 下载大小: 2436542字节
- 数据集大小: 8184752字节
数据集创建
- 注释创建者: 专家生成, 机器生成
- 语言创建者: 发现
- 来源: 维基百科
- 注释: 使用TER工具获取词级标签, HTER值从词级标签确定性获取
- 许可证: 未知
- 贡献者: @VictorSanh
搜集汇总
数据集介绍
构建方式
在机器翻译质量评估领域,WMT20多语言质量估计任务二数据集的构建体现了严谨的学术流程。该数据集源自维基百科的扩展语料,通过专家与机器协同生成标注。其核心标注过程依赖于TER工具,该工具在机器翻译输出与人工后编辑版本之间进行词级对齐,并据此自动生成源语言与目标语言的词级质量标签(BAD或OK)。句子级的HTER分数则根据这些词级标签计算得出,同时允许在计算过程中考虑词序调整,从而确保了质量评估的客观性与可复现性。整个数据集包含英语-德语和英语-中文两种语言对,为多语言质量估计研究提供了结构化基准。
使用方法
在自然语言处理的应用实践中,该数据集主要用于机器翻译质量估计模型的训练与评测。研究者可通过HuggingFace数据集库直接加载‘en-de’或‘en-zh’配置,获取已划分的训练、验证及测试数据。模型训练通常以源句、机器翻译句及词对齐作为输入,以预测词级标签或句子级HTER分数为目标。评估阶段,词级预测采用马修斯相关系数,句子级预测则使用皮尔逊相关系数,与WMT官方评测标准保持一致。该数据集为开发能够实时、无参考评估翻译质量的系统提供了标准化的实验平台。
背景与挑战
背景概述
在机器翻译领域,质量评估(Quality Estimation, QE)旨在无需参考译文的情况下自动预测翻译输出的质量,对于提升翻译系统的实用性与可靠性具有关键意义。WMT20多语言质量评估任务二数据集由国际机器翻译会议(WMT)于2020年发布,其核心研究问题聚焦于在句子级与词级层面精准评估神经机器翻译的输出质量。该数据集涵盖英语-德语与英语-中文两种语言对,数据主要源自维基百科,通过专家与机器协同生成标注,为研究者提供了丰富的多语言评估资源,显著推动了翻译质量评估模型的发展与应用。
当前挑战
该数据集致力于解决翻译质量评估中的核心挑战,即在缺乏参考译文的情况下,准确预测翻译错误的位置与程度。具体而言,词级标注需识别源语言与目标语言中的错误词汇,而句子级HTER评分则要求量化整体编辑距离,这对模型的细粒度理解与泛化能力提出了极高要求。在构建过程中,数据标注依赖TER工具进行对齐与错误标注,但词序错误仅以删除与插入形式表示,可能引入噪声;同时,多语言数据(尤其是中英文对)的语法与语义差异显著,增加了标注一致性与模型跨语言适应的难度。
常用场景
经典使用场景
在机器翻译质量评估领域,WMT20 MLQE Task2数据集为研究者提供了多语言质量估计的基准平台。该数据集通过标注源语言和目标语言的词级标签、句子级HTER分数以及词对齐信息,支持对神经机器翻译输出进行细粒度质量分析。经典使用场景包括训练和评估质量估计模型,这些模型能够在不依赖参考译文的情况下,实时预测翻译输出的可信度,从而为后续的译后编辑或系统优化提供依据。
解决学术问题
该数据集有效解决了机器翻译质量评估中的若干核心学术问题。它通过提供大规模、多语言、细粒度的标注数据,使得研究者能够探索无参考翻译的质量估计方法,突破了传统基于参考译文的评估局限。数据集中的词级标签和HTER分数为模型提供了丰富的监督信号,促进了质量估计模型在跨语言场景下的泛化能力研究,推动了翻译质量评估从句子级到词级的精细化发展。
实际应用
在实际应用层面,WMT20 MLQE Task2数据集支撑了翻译工作流中的关键环节。基于该数据集训练的模型可集成到计算机辅助翻译工具中,实时高亮翻译错误或低质量片段,辅助人工译员进行高效译后编辑。在内容本地化、多语言信息处理等场景,此类质量估计技术有助于筛选和优先处理低质量翻译,提升整体翻译管道的效率与产出质量,降低人工审核成本。
数据集最近研究
最新研究方向
在机器翻译质量评估领域,WMT20 MLQE Task2数据集正推动前沿研究向多语言、细粒度方向深化。该数据集提供的英德、英中双语对,结合词级标注与句子级HTER分数,为无参考翻译的质量估计模型开发奠定了坚实基础。当前研究热点聚焦于利用深度神经网络,特别是预训练语言模型,融合源语言与目标语言的上下文信息,以提升跨语言质量评估的准确性与泛化能力。相关探索亦关注如何整合对齐信息与系统内部特征,优化对翻译错误(如缺失、误译)的检测机制,这直接助力于实时翻译后编辑与自适应神经机器翻译系统的发展,对推动多语言自然语言处理技术的实际应用具有显著意义。
以上内容由遇见数据集搜集并总结生成


