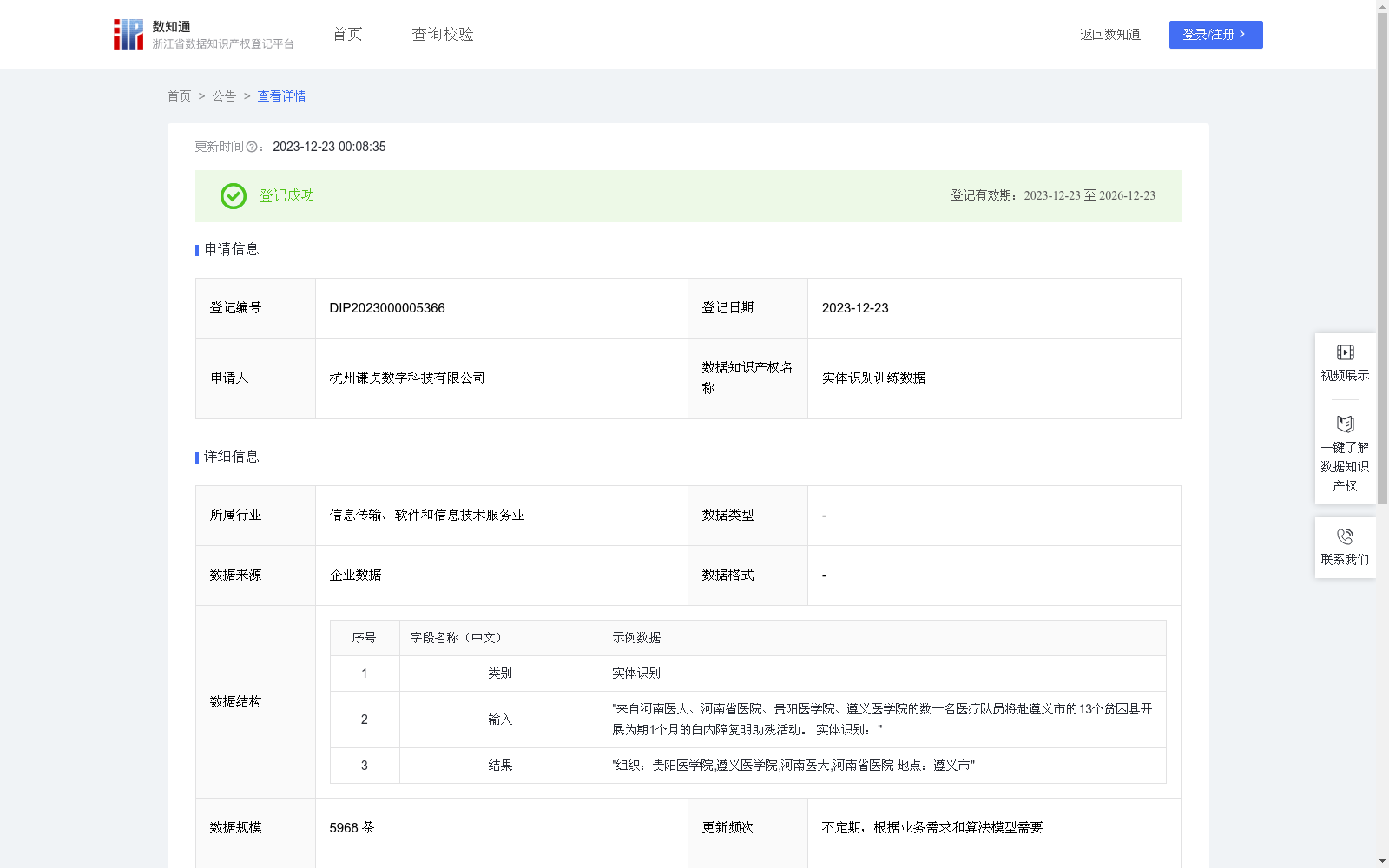
实体识别训练数据
收藏浙江省数据知识产权登记平台2023-12-23 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/22235
下载链接
链接失效反馈官方服务:
资源简介:
适用条件与范围
医疗健康:从病历记录中识别疾病、药物和治疗过程等实体,辅助诊断和治疗决策。
法律和合规:在法律文件中识别相关的法律条款、案件名称、参与人物等,用于合规性分析。
金融服务:从财经新闻或报告中提取公司名称、股票代码、经济指标等,辅助市场分析和投资决策。
新闻和媒体:自动识别新闻文章中的关键人物、地点、事件等,用于内容分类和摘要生成。
社交媒体分析:从用户生成的内容中识别品牌、产品、人名等,用于市场趋势分析和舆情监控。
旅游和地理信息系统:识别地理位置、地标、文化遗产等,用于旅游推荐和地理信息服务。
对象
医疗专业人员:用于提高病历处理的效率和准确性。
法律从业者:帮助快速处理大量法律文件和案件记录。
金融分析师:协助进行市场趋势分析和投资决策。
新闻编辑和记者:提高新闻报道的准确性和速度。
市场营销人员:分析品牌和产品的市场表现。
旅游规划师:提供更丰富的旅游信息和建议。
禁用场景
不用于非法目的:禁止用于任何形式的非法活动,如侵犯隐私、诈骗等。
避免敏感信息泄露:在处理个人敏感信息时必须遵守隐私保护和数据安全的法律法规。
避免偏见和歧视:确保实体识别不加强任何形式的偏见和实体识别(Entity Recognition)是自然语言处理(NLP)中的一个关键任务,旨在从文本中自动识别和分类特定的实体,如人名、地点、组织名称等。以下是实体识别任务的算法规则简要说明:
1. 数据预处理
文本清洗:去除无关字符,如标点、特殊符号等,统一文本格式。
分词:特别是对于中文等不使用空格分隔单词的语言,需要进行有效的分词处理。
2. 特征提取
语法特征:提取词性标记、句法依赖等信息。
上下文特征:分析实体周围的词汇和语境,帮助确定实体的类别。
3. 模型训练
传统机器学习方法:如决策树、支持向量机(SVM)等,利用人工提取的特征。
深度学习方法:如循环神经网络(RNN)、长短时记忆网络(LSTM)和BERT等,能够自动学习复杂的特征。
4. 实体识别
序列标注:标注每个词汇是否属于某个实体类别,以及实体的边界。
实体分类:确定每个识别出的实体属于哪个类别,如人名、地点等。
5. 后处理
实体合并:合并多个标记来形成一个完整的实体,如一个完整的人名。
消歧:解决实体名称可能引起的歧义,如同名的不同人物或地点。
6. 优化与评估
模型调优:根据实体识别的性能调整模型参数。
Applicable Conditions and Scope
Medical and Healthcare: Identify entities such as diseases, medications, and treatment processes from medical records to assist with diagnosis and treatment decision-making.
Law and Compliance: Identify relevant legal clauses, case names, involved parties, etc., from legal documents for compliance analysis.
Financial Services: Extract company names, stock tickers, economic indicators, etc., from financial news or reports to support market analysis and investment decision-making.
News and Media: Automatically identify key figures, locations, events, etc., in news articles for content classification and summary generation.
Social Media Analytics: Identify brands, products, personal names, etc., from user-generated content for market trend analysis and public opinion monitoring.
Tourism and Geographic Information Systems: Identify geographic locations, landmarks, cultural heritage sites, etc., for travel recommendation and geographic information services.
Target Users
Medical Professionals: To improve the efficiency and accuracy of medical record processing.
Legal Practitioners: To assist in quickly processing large volumes of legal documents and case records.
Financial Analysts: To support market trend analysis and investment decision-making.
News Editors and Journalists: To improve the accuracy and speed of news reporting.
Marketing Professionals: To analyze the market performance of brands and products.
Tourism Planners: To provide richer travel information and recommendations.
Prohibited Scenarios
Not for Illegal Purposes: Prohibited for any form of illegal activity, such as privacy infringement, fraud, etc.
Avoid Sensitive Information Leakage: When processing personal sensitive information, comply with laws and regulations on privacy protection and data security.
Avoid Bias and Discrimination: Ensure that entity recognition does not reinforce any form of bias.
Entity Recognition is a core task in Natural Language Processing (NLP), which aims to automatically identify and classify specific entities (e.g., personal names, locations, organization names) from text. The following is a brief explanation of the algorithmic rules for the entity recognition task:
1. Data Preprocessing
Text Cleaning: Remove irrelevant characters such as punctuation and special symbols, and unify text formats.
Word Segmentation: For languages that do not use spaces to separate words (e.g., Chinese), effective word segmentation processing is required.
2. Feature Extraction
Syntactic Features: Extract information such as part-of-speech tags and syntactic dependencies.
Contextual Features: Analyze the vocabulary and context surrounding entities to help determine the category of the entity.
3. Model Training
Traditional Machine Learning Methods: Such as Decision Trees, Support Vector Machines (SVM), etc., which use manually extracted features.
Deep Learning Methods: Such as Recurrent Neural Networks (RNN), Long Short-Term Memory networks (LSTM), and BERT, which can automatically learn complex features.
4. Entity Recognition
Sequence Labeling: Label whether each word belongs to a certain entity category and the boundary of the entity.
Entity Classification: Determine which category each identified entity belongs to, such as personal names, locations, etc.
5. Post-processing
Entity Merging: Merge multiple tokens to form a complete entity (e.g., a complete personal name).
Disambiguation: Resolve ambiguities caused by entity names, such as different people or locations with the same name.
6. Optimization and Evaluation
Model Tuning: Adjust model parameters based on the performance of entity recognition.
提供机构:
杭州谦贞数字科技有限公司
创建时间:
2023-11-23
搜集汇总
数据集介绍
特点
该数据集是一个用于实体识别任务的训练数据集,包含5968条数据,适用于多个行业的实体识别需求,如医疗、法律、金融等,并已在区块链平台存证。
以上内容由遇见数据集搜集并总结生成


