source-based-instructions
收藏Hugging Face2025-08-13 更新2025-08-14 收录
下载链接:
https://huggingface.co/datasets/ContextualAI/source-based-instructions
下载链接
链接失效反馈官方服务:
资源简介:
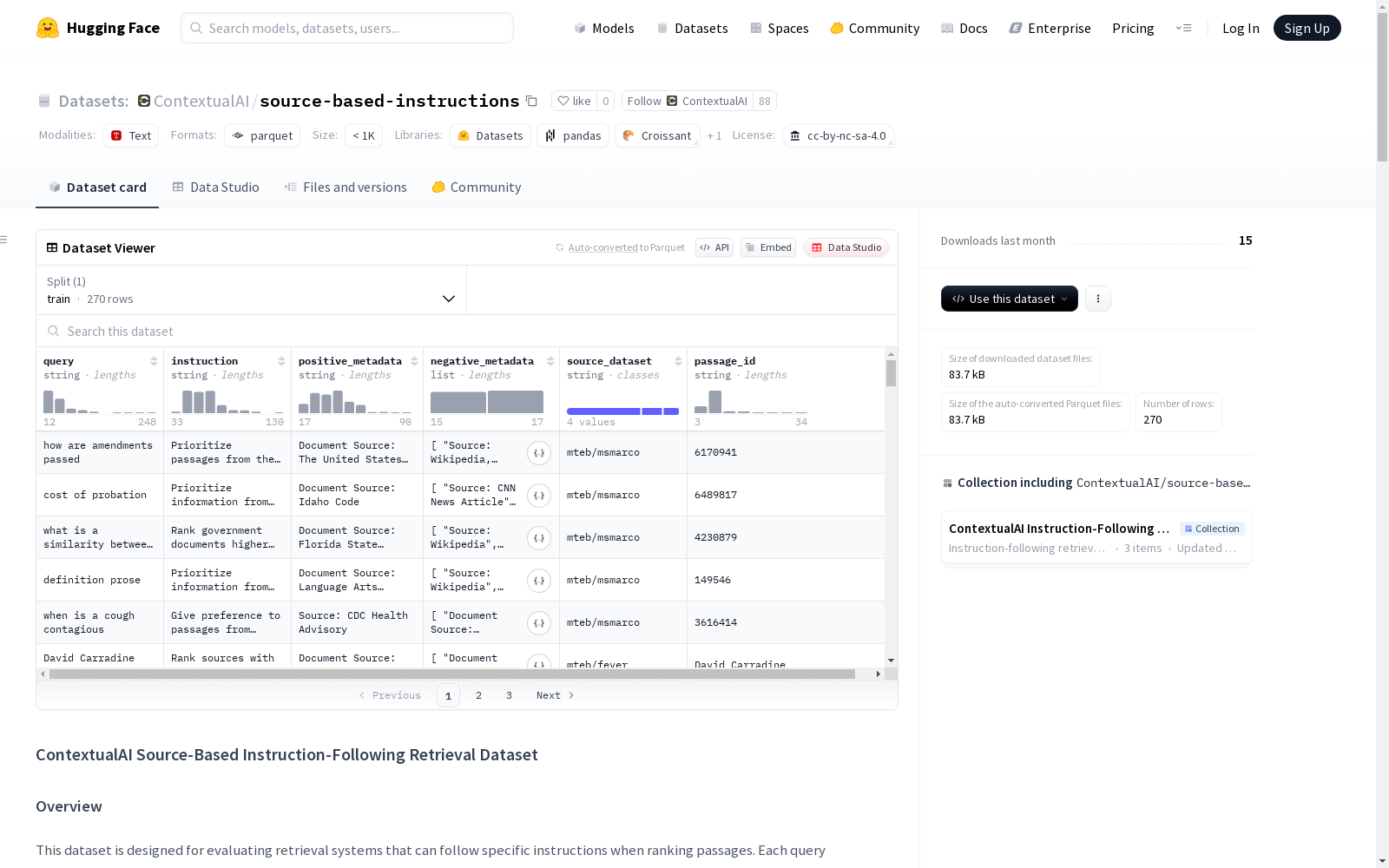
这是一个用于评估检索系统能否在排名段落时遵循特定指令的数据集。每个查询都附带一个指令,指定在检索过程中应优先考虑的信息方面或类型。数据集包含查询、指令、正样本元数据、负样本元数据、源数据集名称和段落ID等特征。由于法律原因,原始段落无法重新托管,因此提供了一个数据处理脚本来下载和合并这些段落。
This is a dataset designed to evaluate whether retrieval systems can follow specific instructions when ranking paragraphs. Each query is accompanied by an instruction that specifies the information aspects or types that should be prioritized during the retrieval process. The dataset includes features such as queries, instructions, positive sample metadata, negative sample metadata, source dataset names, and passage IDs. Due to legal restrictions, the original paragraphs cannot be reposted, so a data processing script is provided to download and merge these paragraphs.
提供机构:
ContextualAI创建时间:
2025-08-11
原始信息汇总
ContextualAI Source-Based Instruction-Following Retrieval Dataset 概述
数据集基本信息
- 许可证: Creative Commons Attribution Non Commercial Share Alike 4.0
- 下载大小: 83,709 字节
- 数据集大小: 204,398 字节
- 训练集样本数: 270 个
数据集结构
特征
query: 搜索查询instruction: 检索时应优先考虑的信息方面的具体指令positive_metadata: 相关段落的元数据/上下文negative_metadata: 非相关段落的元数据/上下文列表source_dataset: 包含完整段落的源数据集名称passage_id: 从源数据集中检索完整段落的唯一标识符
数据处理
- 注意事项: 由于法律原因,无法重新托管原始段落,需通过提供的脚本下载并合并。
- 处理脚本: 使用Python脚本从源数据集下载原始段落并与元数据合并。
评估
- 评估指标: 平均倒数排名 (MRR)
- 评估过程:
- 对每个查询-指令对,检索/排名所有段落(1个正面 + N个负面)
- 找到正面段落的排名
- 计算倒数排名 (1/rank)
- 对所有查询取平均值
引用
bibtex @dataset{ContextualAI-source-based-instructions, title={Contextual Source-Based Instruction-Following Retrieval Dataset}, author={George Halal, Sheshansh Agrawal}, year={2025}, publisher={HuggingFace} }
联系方式
- 如有问题或疑问,请在数据集存储库中提交问题或联系 george@contextual.ai。
搜集汇总
数据集介绍
构建方式
该数据集通过整合多个源数据集中的查询指令与相关段落构建而成,采用独特的元数据结构来标注正负样本。构建过程中,研究人员精心设计了查询-指令配对,并基于原始语料库提取对应的相关段落与非相关段落。由于版权限制,数据集仅提供元数据和处理脚本,用户需自行下载原始段落进行合并,这种方法既遵守了数据使用规范,又确保了研究可复现性。
特点
数据集的核心价值在于其创新的指令驱动检索范式,每个查询都配有明确的检索指令,要求系统根据特定标准筛选段落。数据样本包含丰富的元信息,包括查询内容、指令描述、正负段落元数据等,这些结构化特征为研究指令感知的检索系统提供了理想测试平台。值得注意的是,数据集采用分源组织策略,相同源数据的样本被智能分组,极大提升了后续处理的效率。
使用方法
使用该数据集需执行两阶段流程:首先通过提供的Python脚本自动下载对应源数据集的完整语料,随后将元数据与原始段落进行智能匹配。评估时采用平均倒数排名(MRR)指标,要求检索系统根据查询指令对正负段落进行排序。数据集附带的评估脚本封装了完整的评测逻辑,研究者只需实现自定义的检索函数即可进行系统性能测试,这种设计显著降低了研究门槛。
背景与挑战
背景概述
由ContextualAI团队于2025年发布的source-based-instructions数据集,代表了信息检索领域向指令感知式检索系统评估的重要迈进。该数据集由George Halal和Sheshansh Agrawal等研究者构建,核心在于解决传统检索系统对用户意图理解不足的问题,通过引入结构化指令来引导检索过程。其创新性体现在将自然语言指令与查询语句耦合,要求系统同时理解信息需求与检索约束条件,这种设计显著影响了检索系统可解释性和精准度研究方向的发展轨迹。数据集整合了多源异构文本资源,为评估模型在复杂语义场景下的指令遵循能力提供了标准化基准。
当前挑战
该数据集主要应对两大核心挑战:在领域问题层面,传统检索系统难以解析开放式指令的隐含约束,导致检索结果与用户真实需求存在语义偏差;构建过程中需解决多源数据异构性问题,包括不同数据集间元数据格式差异、篇章标识符不兼容等。技术实现上,由于版权限制无法直接托管原始文本,研究者设计了复杂的后处理流程,要求用户动态下载并融合原始语料,这增加了数据使用复杂度。评估环节采用均值倒数排名指标时,需处理指令敏感性与检索相关性的平衡问题,这对现有检索模型的细粒度语义理解能力提出了更高要求。
常用场景
经典使用场景
在信息检索领域,source-based-instructions数据集被广泛用于评估检索系统在遵循特定指令时的性能表现。该数据集通过提供查询和相应的指令,要求系统在检索过程中优先考虑特定类型或方面的信息,从而模拟真实场景中用户对检索结果的精细化需求。这种设计使得该数据集成为评估指令感知检索系统的黄金标准。
解决学术问题
该数据集有效解决了信息检索领域中的关键学术问题,即如何使检索系统能够理解和遵循用户的复杂指令。传统检索系统往往仅基于查询内容进行匹配,而忽略了用户的具体需求。通过引入指令驱动的检索任务,该数据集推动了检索系统从简单匹配向语义理解和任务导向的转变,为相关研究提供了宝贵的基准资源。
衍生相关工作
基于source-based-instructions数据集,研究者们开展了一系列经典工作。其中包括指令感知检索模型的架构创新、多任务学习框架的设计,以及检索-重排序联合优化方法等。这些工作显著提升了检索系统对复杂指令的理解能力,并推动了对话式检索、个性化检索等新兴研究方向的发展。
以上内容由遇见数据集搜集并总结生成


