cibelex-qa-rag-evals
收藏Hugging Face2026-05-19 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/MAIA-Madrid-IA/cibelex-qa-rag-evals
下载链接
链接失效反馈官方服务:
资源简介:
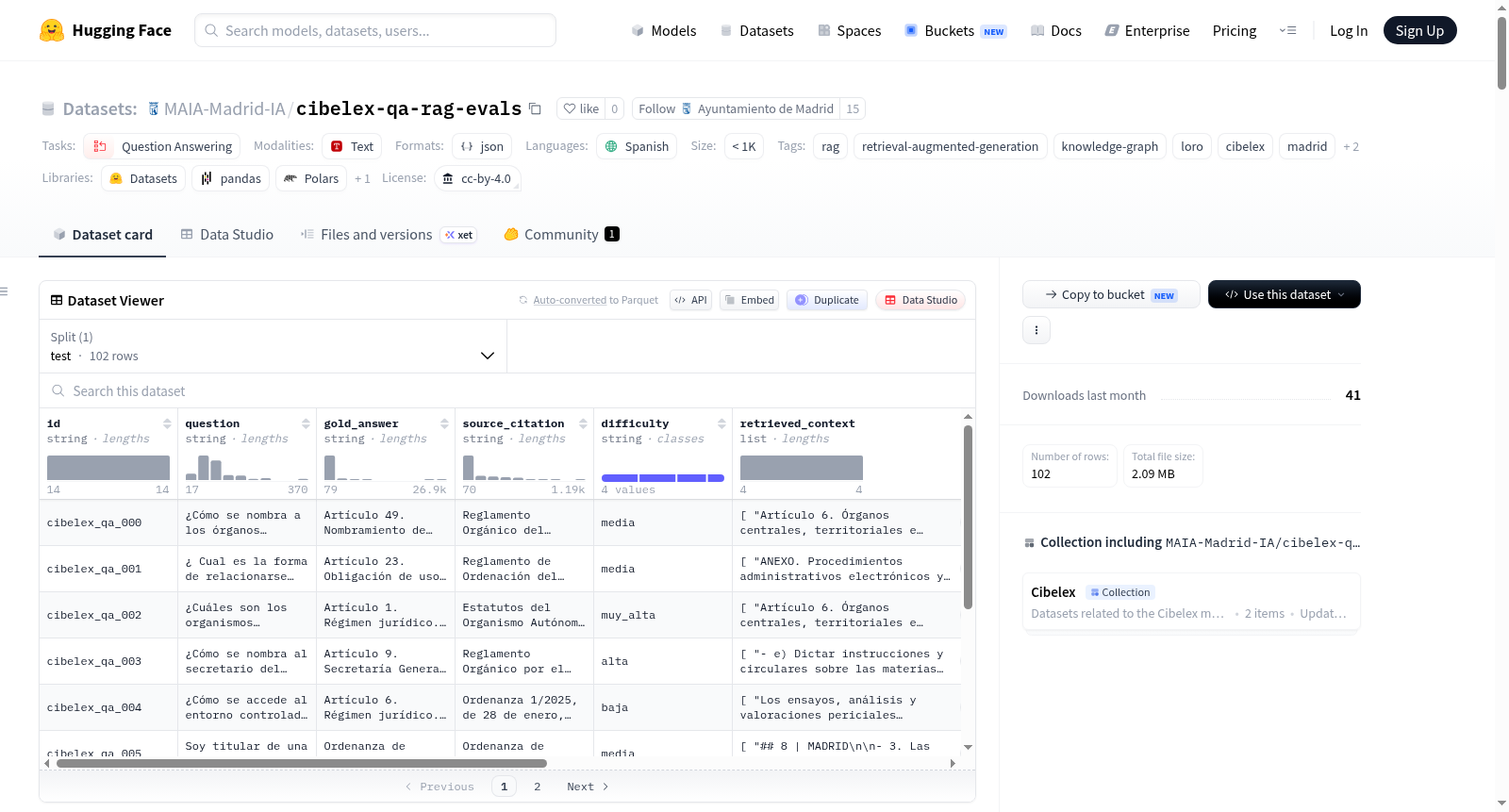
Cibelex QA RAG Evals是一个专门用于问答评估的数据集,其内容基于西班牙马德里市政府的法规语料库(LoRO本体/Cibelex知识图谱)。该数据集旨在为检索增强生成(RAG)、知识图谱感知检索以及西班牙行政法领域的特定问答任务提供基准评估。数据集包含约102个样本,每个样本均包含一个关于马德里市法规的西班牙语自然语言问题、从相关法规条款中直接引用的标准答案、由基线检索器返回的前4个相关文本段落,以及基线大语言模型基于这些段落生成的预测答案。此外,每个样本还标注了问题难度、所需的知识图谱检索策略(如实体搜索、跨图连接、图谱遍历、完整上下文)以及预期的具体知识图谱工具。数据由法律专家创建和标注,确保了领域专业性。数据集的构建过程可复现,并记录了后处理修正步骤。该数据集适用于评估和比较新的检索器、答案生成模型在法规问答任务上的性能,特别是研究知识图谱如何增强RAG系统在复杂法律文本中的表现。
Cibelex QA RAG Evals is a dataset specifically designed for question answering (QA) evaluation. Its content is based on the regulatory corpus of the Madrid City Government (LoRO ontology/Cibelex knowledge graph). This dataset serves as a benchmark for retrieval-augmented generation (RAG), knowledge-graph-aware retrieval, and targeted QA tasks in the field of Spanish administrative law. It contains approximately 102 samples, each including a Spanish natural language question about Madrid’s municipal regulations, a standard answer directly quoted from relevant regulatory clauses, the top 4 relevant text passages returned by a baseline retriever, and a predicted answer generated by a baseline large language model (LLM) based on these passages. Additionally, each sample is annotated with question difficulty, required knowledge-graph retrieval strategies (such as entity search, cross-graph connection, graph traversal, and full context), and the expected specific knowledge-graph tools. The dataset was created and annotated by legal experts, ensuring domain professionalism. The construction process of the dataset is reproducible, with post-processing correction steps documented. This dataset is suitable for evaluating and comparing the performance of new retrievers and answer generation models on regulatory QA tasks, especially for researching how knowledge graphs enhance RAG systems in complex legal text scenarios.
创建时间:
2026-05-08
搜集汇总
数据集介绍
构建方式
该数据集源自马德里市政府LoRO本体与Cibelex知识图谱的联合评估项目。由法律专家基于市政法规语料库手工构建原始问题,并定位相关法条作为标准答案。构建过程严格遵循可复现原则,所有原始数据存储于不可变目录中,仅通过后处理脚本进行两处修正:删除一条注释不完整的记录,并纠正常识性引用错误。每条记录均包含基线检索器返回的四个最相关文本段落,以及在此基础上由大型语言模型生成的基线预测答案,从而形成冻结的RAG评测基线。
特点
数据集针对西班牙行政法律领域的问答评测而设计,融合了检索增强生成与知识图谱感知的双重特性。102条测试样本均标注了难度等级及所需的知识图谱检索策略,涵盖实体搜索、跨图连接、图遍历与全语境四种类型,并明确预设了回答所需的具体知识图谱工具。数据集中基线检索结果与生成答案均已固定,便于后续对比不同检索器与生成模型的性能。难度分布相对均衡,但图谱策略类别存在显著不平衡,尤其是图遍历与全语境策略代表性不足。
使用方法
用户可通过加载JSON Lines格式的测试文件直接使用该数据集。每条记录中的问题与标准答案可用于评估RAG管线的端到端准确性,而检索到的上下文与基线预测则可作为对比基准。借助知识图谱策略与工具标签,研究人员能够开展工具选择消融实验,分析不同检索路径对问答质量的影响。尤其适合用于评测西班牙语法律领域的开放域问答系统,以及验证基于Cibelex知识图谱的语义检索能力。
背景与挑战
背景概述
Cibelex QA RAG Evals数据集由马德里市政厅下属的MAIA研究组与法律监管质量总局联合创建,旨在评估基于检索增强生成(RAG)范式在西班牙语行政法领域的表现。该数据集依托于LoRO知识图谱与Cibelex本体,聚焦马德里市政法规的问答任务,每个样本包含自然语言问题、黄金标准答案、基线检索器返回的四个相关段落以及基线大语言模型生成的答案。数据集发布于2025年,包含102条精心标注的样本,覆盖了从简单到极高难度的四类问题。通过引入知识图谱感知的检索策略标签(如实体搜索、跨图连接),该数据集为RAG系统在特定领域(尤其是法律文本)中的评估提供了基准,推动了知识图谱与检索增强生成的交叉研究。
当前挑战
该数据集所解决的领域问题核心在于:法律文本的问答不仅依赖语义匹配,更需精确引用的法规条款支持,而传统RAG方法在行政法领域常因上下文缺失或实体歧义导致生成错误。构建过程中面临的主要挑战包括:第一,法律专家需从繁复的市政法规中定位多个相关条款并标注难度,劳动强度高且主观性难以完全消除;第二,基线系统仅采用BGE-M3检索器与Gemini 2.5 Flash生成器,其输出质量可能受限于模型版本与提示模板,尚需更多消融实验验证;第三,知识图谱策略标签分布极度不均衡(实体搜索占66%,而图遍历与全上下文仅各占2%),导致后两类策略的评估结果缺乏统计显著性。这些挑战凸显了构建高质量、领域专用且平衡的评估集的内在困难。
常用场景
经典使用场景
在检索增强生成(RAG)与知识图谱(KG)深度融合的研究领域,Cibelex QA RAG Evals 数据集扮演了不可或缺的基准角色。它将马德里市政法规语料库中的自然语言问题、标准答案、基线检索器返回的四个相关段落以及由此生成的模型回答封装于同一记录之中。该数据集尤以支撑RAG系统的对比实验见长,研究者可借助冻结的基线输出,公正地评估不同检索器或生成器的表现。同时,其内置的知识图谱检索策略标签和工具标识,为探索图谱感知的问答机制提供了标准化的评测平台。
实际应用
Cibelex QA RAG Evals 数据集的实际应用场景紧密关联于智慧政务与法律科技的前沿实践。对于开发面向公众的西班牙行政法律咨询系统而言,它可作为检验模型能否从繁杂的市政法规中提取精确条款并生成可信答复的试金石。该数据集的价值同样体现在自动化法规合规审查、政策文件问答助手以及司法辅助工具构建等环节,能够大幅提高法律文本检索与解读的效率。当政府部门或法律服务机构期望部署具备图谱检索增强能力的智能系统时,该数据集为其提供了真实场景下的鲁棒性评估方案。
衍生相关工作
该数据集的发布催生了一系列聚焦于法律领域RAG与知识图谱融合的创新性研究工作。衍生工作多集中于两类路径:其一是基于其标注的图谱检索策略,开发能够自适应选择最佳查询路径的动态检索方法;其二是针对其实例中凸显的出图遍历和全上下文策略样本稀疏问题,研究者正在构建合成数据集以平衡类别分布,从而推动对小样本策略的鲁棒学习。此外,基于该数据集的特定工具分配逻辑,衍生工作还涵盖了工具间协同调度的强化学习建模,为复杂法律问答中的多步推理奠定了实验基础。
以上内容由遇见数据集搜集并总结生成


