Sentence-Tone
收藏Hugging Face2026-05-05 更新2026-05-06 收录
下载链接:
https://huggingface.co/datasets/hamzah0asadullah/Sentence-Tone
下载链接
链接失效反馈官方服务:
资源简介:
Sentence Tone是一个通过LLaMA3.1 8B等模型合成生成的英文文本数据集,专注于文本分类和文本生成任务。该数据集预计将包含1,000,000个样本,所有数据均为英文。新生成的样本会定期更新,至少每周上传一次最新数据。数据集采用Apache 2.0许可协议发布。
Sentence Tone is an English text dataset synthetically generated by models such as LLaMA3.1 8B, focusing on text classification and text generation tasks. The dataset is expected to contain 1,000,000 samples, all in English. Newly generated samples are regularly updated, with the latest data uploaded at least weekly. The dataset is released under the Apache 2.0 license.
创建时间:
2026-05-05
原始信息汇总
数据集概述:Sentence Tone
基本信息
- 许可证:Apache-2.0
- 语言:英语(en)
- 任务类型:
- 文本分类
- 文本生成
数据集描述
该数据集为合成生成的数据集,使用诸如 LLaMA3.1 8B 等模型生成。
规模与更新
- 数据集预计扩展至 1,000,000 个样本(英语)
- 新生成的样本至少每 七天 更新一次至在线镜像
当前状态
- 数据集卡片(Dataset Card)尚未完成,作者计划在期末考试后编写。
搜集汇总
数据集介绍
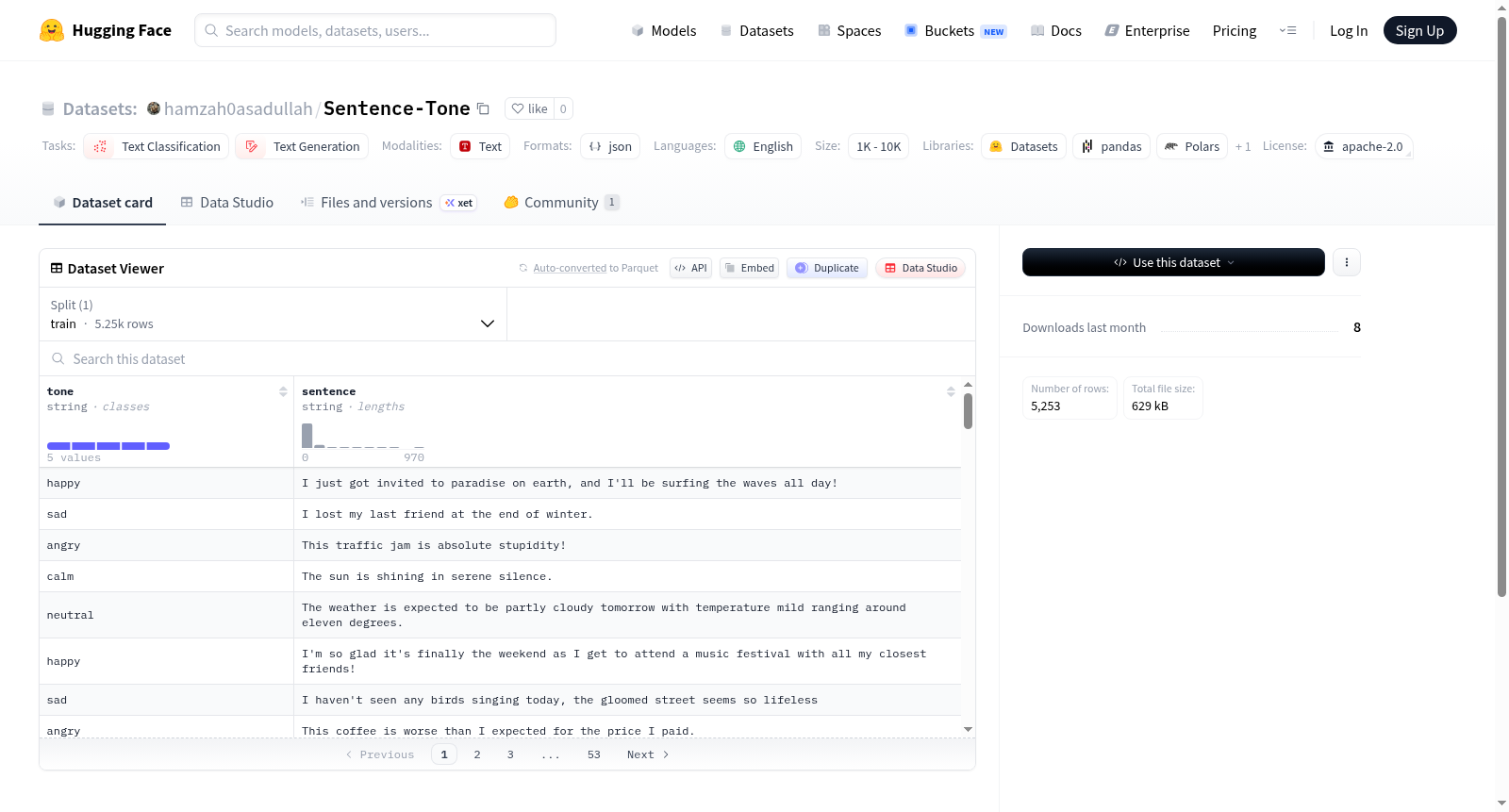
构建方式
Sentence-Tone数据集采用合成生成方式构建,利用如LLaMA3.1 8B等先进语言模型生成高质量文本样本。其核心设计理念在于通过可控的生成流程,产出带有明确情感或语气标签的句子,旨在为文本分类与生成任务提供大规模训练资源。数据集计划扩展至100万条英文样本,且每七天至少更新一次,确保数据规模与多样性的持续增长。
特点
该数据集以合成数据为主要特色,规避了真实数据收集中的隐私与标注偏差问题。通过模型生成的样本覆盖广泛的情感与语气类别,适用于多粒度情感分析场景。其持续更新机制保证了数据的新颖性与时效性,同时Apache-2.0许可授权降低了学术与商业应用的门槛。数据集的动态扩展性使其成为情感计算领域一个极具潜力的基础资源。
使用方法
Sentence-Tone可直接用于文本分类任务的微调与评估,尤其适用于情感分析、语气识别等方向。用户可将其作为预训练语言模型的训练语料,通过监督学习或提示学习范式进行任务适配。对于文本生成任务,该数据集可作为条件控制信号,指导模型生成特定语气文本。建议研究者关注其定期更新接口,以获取最新样本并保持模型性能的实时性与鲁棒性。
背景与挑战
背景概述
情绪识别作为自然语言处理中的核心任务,旨在从文本中捕捉并分类作者或说话者的情感倾向,广泛应用于社交媒体分析、客户反馈评估与人机交互等领域。Sentence-Tone数据集于2024年由独立研究者创建,采用诸如LLaMA3.1 8B等大型语言模型进行合成数据生成,计划扩展至100万英文样本。该数据集的构建旨在弥补大规模高质量情感标注语料的匮乏,通过模型驱动的方式降低成本并提升多样性,为文本分类和生成任务提供基础资源,对推动情感计算和少样本学习研究具有潜在影响力。
当前挑战
数据集面临的首要挑战是解决情感分类领域中的细微情绪区分难题,例如讽刺、幽默等复杂语境下的情绪识别,传统标注数据常因人工主观性而缺乏一致性。构建过程中,依赖合成数据生成模型易引入噪声和偏差,需确保生成样本的情感标签准确且覆盖多样场景。此外,计划每七天更新数据,维持百万级样本的质量与平衡性成为技术瓶颈,需设计有效的过滤与验证机制以避免低质量内容累积,从而保障数据集的可靠性与实用性。
常用场景
经典使用场景
Sentence-Tone数据集专注于英文句子的语气分类,涵盖诸如正式、随意、讽刺、幽默等多种语气类别。在自然语言处理领域,它常被用于文本分类任务的训练与评估,尤其是针对情感分析之外更细腻的语用特征识别。研究者利用该数据集构建和优化分类模型,以捕捉句子中隐含的交流态度与表达风格,从而提升机器对人类语言微妙差异的理解能力。
实际应用
在实际应用中,Sentence-Tone可赋能智能客服与虚拟助手,使其能根据用户语气调整回应策略,提供更具同理心的交互体验。在社交媒体监控中,该数据集有助于自动过滤有害言论或识别戏谑语气,增强内容审核的精准度。此外,教育科技平台可利用语气识别功能为语言学习者提供反馈,帮助其掌握地道表达中的细微语气差异。
衍生相关工作
基于Sentence-Tone数据集的衍生工作涵盖了语气感知的预训练模型微调方法,以及跨语言语气迁移学习的研究。一些研究者将其与情感词典结合,开发出多维度文本分析框架。同时,该数据集激发了关于合成数据质量评估与偏差检测的探讨,催生了针对生成式模型在语用任务中可靠性的检验工作,为后续合成数据集构建提供了方法论参考。
以上内容由遇见数据集搜集并总结生成


