ASR_Dataset
收藏Hugging Face2025-12-06 更新2025-12-07 收录
下载链接:
https://huggingface.co/datasets/admin-euphoria/ASR_Dataset
下载链接
链接失效反馈官方服务:
资源简介:
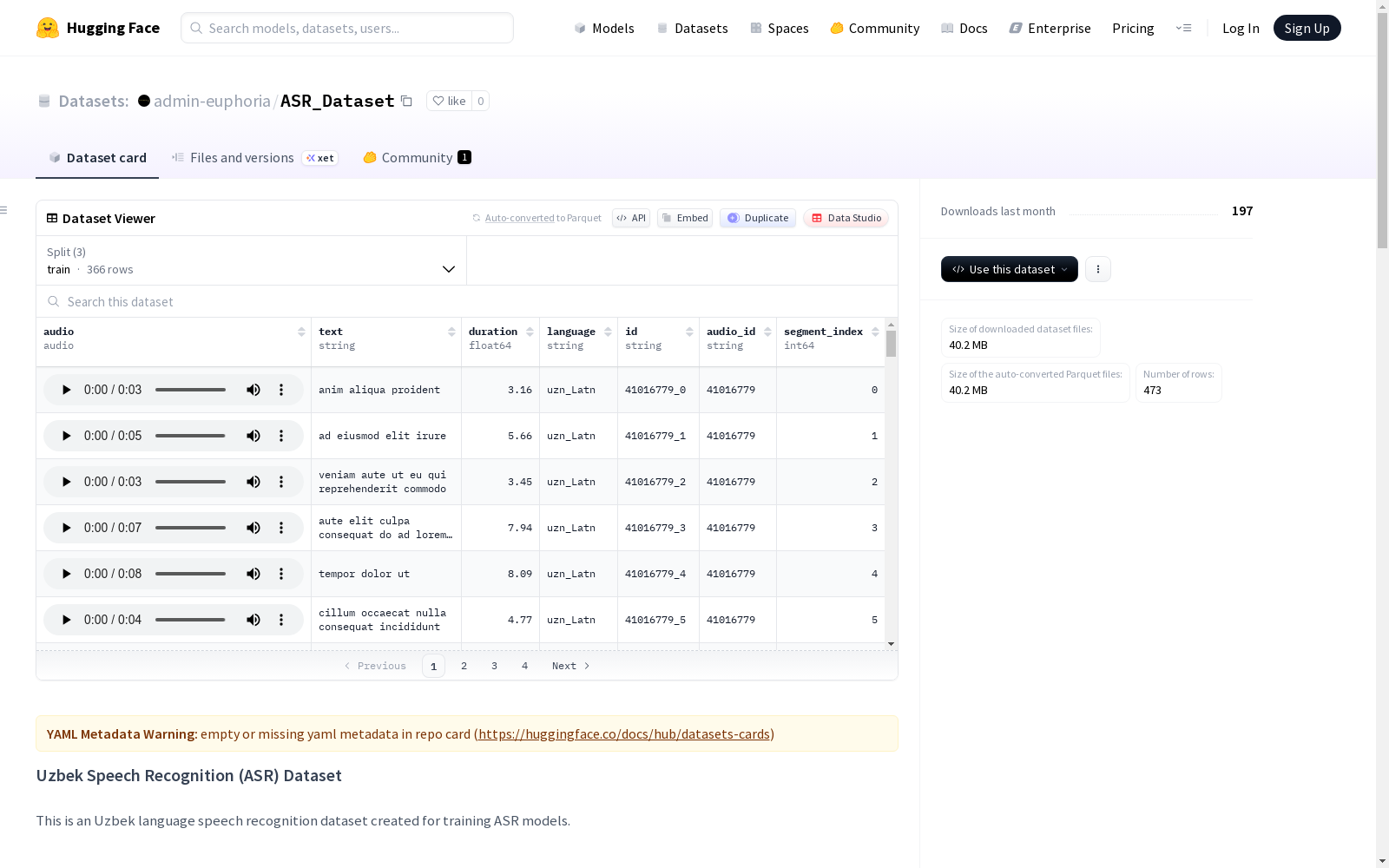
这是一个乌兹别克语语音识别数据集,专为训练ASR模型而创建。数据集包含训练、验证和测试集,音频格式为16 kHz、单声道、16位PCM的WAV文件。每个音频文件配有标准化的乌兹别克语拉丁字母文本转录,以及持续时间、语言代码、唯一标识符等信息。数据集每天更新,采用增量上传策略,确保无重复数据。
创建时间:
2025-12-05
原始信息汇总
乌兹别克语语音识别(ASR)数据集概述
数据集基本信息
- 数据集名称:Uzbek Speech Recognition (ASR) Dataset
- 主要用途:用于训练乌兹别克语语音识别(ASR)模型
- 语言:乌兹别克语(拉丁字母)
- 许可证:MIT (https://opensource.org/licenses/MIT)
- 最后更新日期:2025-12-06T16:15:27.710995
数据集结构
- 训练集(train):包含80%的对话数据
- 验证集(validation):包含10%的对话数据
- 测试集(test):包含10%的对话数据
音频格式规范
- 采样率:16 kHz
- 声道:单声道(Mono)
- 位深度:16-bit PCM
- 文件格式:WAV
数据字段说明
audio:音频文件(可直接播放的音频特征)text:乌兹别克语(拉丁字母)的标准化文本转录duration:音频时长(秒)language:语言代码(uzn_Latn表示乌兹别克语拉丁字母)id:片段的唯一标识符audio_id:对话/录音的标识符segment_index:对话中片段的索引
数据集统计信息
- 对话总数:8
- 片段总数:48
- 总时长:0.08小时
- 训练集:38个片段(0.06小时)
- 验证集:0个片段(0.0小时)
- 测试集:10个片段(0.02小时)
重要注意事项
- 对话数据不会在训练集、验证集和测试集之间拆分
- 每个对话(
audio_id)完全属于一个数据划分 - 此设计确保了模型评估时没有数据泄露
- 数据集每日更新,仅追加新录音
- 上传后的片段会在数据库中标记,以防止重复
更新策略
- 每日构建:首个脚本每日从数据库收集数据
- 增量上传:第二个脚本仅将新片段上传至Hugging Face
- 数据库追踪:ProcessedDataset表追踪已上传的
segment_id - 无重复:
segment_id的唯一性防止重复上传 - 仅追加:数据仅添加,从不删除或修改
使用方法
可通过datasets库加载数据集:
python
from datasets import load_dataset
dataset = load_dataset(admin-euphoria/ASR_Dataset)
联系方式
- 邮箱:kkadyr039@gmail.com
搜集汇总
数据集介绍
构建方式
在语音识别研究领域,构建高质量数据集是推动模型性能提升的关键。该乌兹别克语语音识别数据集通过系统化流程构建,首先从数据库中每日采集新的语音对话数据,随后采用增量上传策略,仅将未处理过的语音片段添加至数据集,确保内容持续更新且避免重复。数据划分遵循对话完整性原则,每个完整对话仅归属于训练、验证或测试集之一,有效防止数据泄露,为模型评估提供可靠基础。
特点
该数据集专为乌兹别克语语音识别任务设计,采用拉丁字母转写文本,语言标注统一为uzn_Latn代码。音频数据以16kHz采样率、单声道、16位PCM格式的WAV文件存储,保证语音信号的清晰与一致性。数据集规模虽小,包含8段对话共48个片段,总时长约0.08小时,但其结构清晰,划分明确,且通过每日追加更新机制不断扩充,为研究乌兹别克语这一资源相对有限的语言提供了宝贵资源。
使用方法
利用该数据集进行语音识别模型训练十分便捷,研究者可通过Hugging Face的datasets库直接加载。使用load_dataset函数可获取完整数据集或指定训练、验证及测试子集。每个数据样本包含可直接播放的音频数组、对应文本转录、时长及唯一标识符等信息,便于模型输入输出对齐。示例代码展示了如何遍历训练集并提取音频特征与文本,为后续特征提取、模型训练及评估提供标准化接口。
背景与挑战
背景概述
乌兹别克语语音识别数据集(ASR_Dataset)由研究人员或机构于近期创建,旨在应对低资源语言自动语音识别技术发展的迫切需求。该数据集聚焦于乌兹别克语(拉丁字母书写)的语音-文本对齐任务,核心研究问题在于为缺乏大规模标注语音资源的语言构建高质量、标准化的训练与评估基准。通过提供格式统一、标注规范的音频数据,该数据集有望推动乌兹别克语语音处理模型的开发,对促进多语言人工智能技术的包容性发展具有潜在影响力。
当前挑战
该数据集致力于解决低资源语言自动语音识别领域的关键挑战,即如何在数据稀缺条件下构建有效的语音识别系统。具体挑战包括:领域问题方面,乌兹别克语作为低资源语言,其语音数据的收集、标注及模型训练面临资源有限、方言变体处理以及声学模型适应性等难题;构建过程方面,数据集规模目前较小(仅0.08小时音频),需通过增量更新策略持续扩充,同时需确保数据分割避免信息泄漏、维持音频质量一致性,并处理日常更新中的去重与数据完整性维护等技术挑战。
常用场景
经典使用场景
在语音识别研究领域,低资源语言的数据稀缺问题长期制约着相关技术的发展。Uzbek Speech Recognition (ASR) Dataset作为乌兹别克语(拉丁字母)的专用语音数据集,其经典使用场景在于为乌兹别克语自动语音识别模型的训练与评估提供核心语料。研究者通常利用其标准化的音频-文本对齐数据,构建端到端的声学模型或端到端识别系统,以探索在有限数据条件下的模型泛化能力与鲁棒性。
实际应用
在实际应用层面,该数据集支撑着面向乌兹别克语用户的智能语音交互系统的开发。基于此训练的模型可集成于语音助手、实时字幕生成、语音指令控制及电话语音应答等场景,服务于教育、客服、媒体及无障碍技术领域。其增量更新的机制确保了数据集能持续反映语言使用的动态变化,为部署在真实环境中的语音应用提供了数据可持续性的保障。
衍生相关工作
围绕该数据集,已衍生出一系列专注于低资源语音处理的经典研究工作。这些工作主要集中于利用有限数据优化声学建模,例如探索基于自监督预训练的特征提取、多语言迁移学习框架的适配,以及针对乌兹别克语语音特性的端到端模型结构设计。此外,该数据集也常被用于评估跨语言语音识别系统的性能,推动了小语种语音技术生态的构建与相关开源工具链的发展。
以上内容由遇见数据集搜集并总结生成


