twentle-gemma-2
收藏Hugging Face2026-05-08 更新2026-05-09 收录
下载链接:
https://huggingface.co/datasets/maximedb/twentle-gemma-2
下载链接
链接失效反馈官方服务:
资源简介:
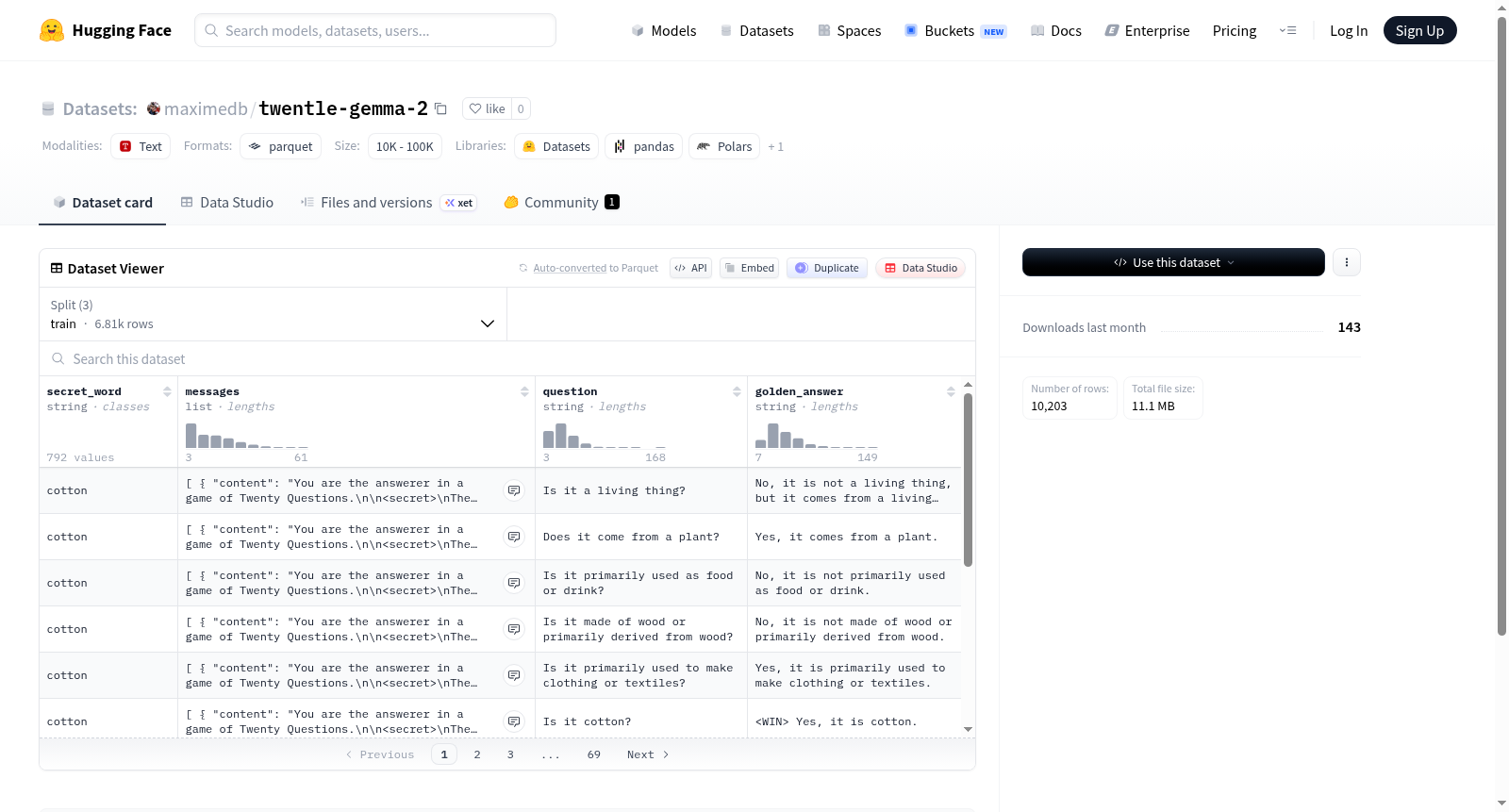
该数据集包含三个预定义分割(训练集、验证集和self_play_01集),共计10,203个样本。主要数据结构包含四个核心字段:1) secret_word(字符串类型),2) messages(消息列表,每条消息包含content和role两个字符串字段),3) question(字符串类型的问题字段),4) golden_answer(字符串类型的标准答案)。训练集包含6,806个样本(约105MB),验证集1,397个样本(约22MB),self_play_01集2,000个样本(约31MB)。数据集总大小约158MB,下载压缩包约11MB。数据文件按分割存储在不同路径下。
This dataset includes three predefined splits (training set, validation set, and self_play_01 set), with a total of 10,203 samples. Its core data structure encompasses four key fields: 1) secret_word (string type), 2) messages (a list of messages, where each message comprises two string fields: content and role), 3) question (string-type question field), 4) golden_answer (string-type standard answer). The training set consists of 6,806 samples (approximately 105 MB), the validation set contains 1,397 samples (approximately 22 MB), and the self_play_01 set has 2,000 samples (approximately 31 MB). The overall size of the dataset is approximately 158 MB, while the downloaded compressed package is about 11 MB. Data files are stored in separate directories based on their respective splits.
创建时间:
2026-04-30
原始信息汇总
好的,这是对您提供的数据集详情页面的概述。
数据集概述:twentle-gemma-2
该数据集名为 twentle-gemma-2,由用户 maximedb 托管在 Hugging Face 上。
核心内容与结构
- 任务类型: 该数据集旨在用于训练或评估模型在特定游戏(Twentle)中的表现,核心是通过对话进行词语猜测。
- 数据特性: 每条数据包含一个秘密词语 (
secret_word)、一段历史对话 (messages)、一个问题 (question) 以及一个标准答案 (golden_answer)。对话部分由多个轮次组成,每个轮次包含角色 (role) 和内容 (content)。 - 数据特征:
secret_word:字符串类型,代表游戏中的目标词语。messages:对话列表,每条包含content(字符串) 和role(字符串)。question:字符串类型,表示向模型提出的问题。golden_answer:字符串类型,表示该问题的标准答案。
数据规模与划分
数据集总量约为 158.6 MB,下载大小约为 11.1 MB。数据被划分为以下三个子集:
| 数据子集 (Split) | 样本数量 (Examples) | 大小 (Bytes) |
|---|---|---|
| train | 6,806 | 105,334,602 |
| validation | 1,397 | 21,910,736 |
| self_play_01 | 2,000 | 31,381,533 |
配置文件
数据集提供了一个名为 default 的默认配置,其数据文件分别存储在以下路径下:
- 训练集:
data/train-* - 验证集:
data/validation-* - 自对弈集:
data/self_play_01-*
搜集汇总
数据集介绍
构建方式
在语言模型的精细化调优过程中,高质量对话数据的构建尤为关键。twentle-gemma-2数据集源于对Gemma-2模型进行针对性调优的需求,通过设计包含秘密词(secret_word)的交互式问答场景来构建。每条数据由系统设定的秘密词、多轮对话记录(messages)、用户提出的具体问题(question)以及对应的标准答案(golden_answer)组成,整体以结构化JSON格式存储。数据集划分为训练集、验证集和自博弈(self_play_01)集,训练集包含6806个样本,验证集1397个样本,自博弈集2000个样本,共计超过1万条精心编排的对话实例。
使用方法
使用时,开发者可将数据集加载为HuggingFace Dataset格式,依据config名为'default'的配置分别读取train、validation和self_play_01分片。在训练Llama系列或其他Transformer架构模型时,可将messages字段直接用于监督式微调(SFT)或偏好优化。secret_word字段作为隐藏的约束条件,可在训练时嵌入系统提示或作为额外输入特征。验证集和自博弈集可用于评估模型泛化能力及对抗性训练效果。最终,需将数据集转换为模型期望的对话模板格式,并利用golden_answer计算损失或准确率指标。
背景与挑战
背景概述
twentle-gemma-2数据集由研究人员在2024年构建,旨在探索大型语言模型在特定任务中的推理与对齐能力。该数据集以秘密词(secret_word)为核心,通过多轮对话(messages)和问答对(question与golden_answer)的形式,模拟模型在隐含约束下的逻辑推断场景。其核心研究问题聚焦于如何通过结构化数据提升模型对隐性指令的响应准确性,尤其在自博弈(self_play)设置下评估模型的泛化性能。作为Gemma-2模型的配套数据集,它推动了语言模型在安全性和可控性方面的研究,为后续的模型对齐工作提供了重要基准。
当前挑战
该数据集所解决的领域问题在于,语言模型常因缺乏对隐含规则的敏感度而输出与意图相悖的结果,例如在角色扮演或保密任务中泄露信息。通过引入secret_word作为隐藏约束,数据集迫使模型学习在对话中维持特定目标,这对模型的上下文理解与策略性推理构成严峻考验。构建过程中,研究人员面临生成高质量对话对与黄金答案的挑战,需确保样例覆盖多样化的秘密词和交互路径;同时,自博弈分片(self_play_01)的合成数据需平衡真实性与多样性,避免模型过拟合有限模式。此外,6806条训练样本与1397条验证样本的规模对统计鲁棒性提出更高要求,易因数据稀疏性导致泛化困难。
常用场景
经典使用场景
在自然语言处理与生成式人工智能的交汇领域,twentle-gemma-2数据集以秘密词引导的多轮对话结构为特色,广泛应用于大语言模型的指令微调与对齐研究。其每条样本包含秘密词、多轮消息序列、问题及标准答案,特别适合训练模型在特定语境下遵循隐含指令、保持上下文一致性并精准输出目标答案。研究者常借此数据集探索模型在受限语义空间中的推理能力与行为可控性。
解决学术问题
该数据集着力解决了大语言模型在复杂对话场景中缺乏目标导向性的学术难题。通过引入秘密词作为隐性约束,它帮助学者系统研究模型对隐含提示的理解程度、对干扰信息的鲁棒性以及生成结果的语义保真度。这一设计促进了对话系统从自由生成向结构化响应演进,为评估模型在真实世界任务中的可解释性与可靠性提供了标准化基准。
实际应用
在实际应用层面,twentle-gemma-2数据集为智能客服、虚拟助手以及教育辅导系统等场景提供了关键训练素材。例如,在构建具备任务驱动能力的对话代理时,该数据集使模型能够依据用户未明言但暗示的特定词汇,动态调整回答策略,从而提升交互的精准度与用户满意度。此外,其多轮对话结构也支持更自然的非确定性对话流程模拟。
数据集最近研究
最新研究方向
在语言模型自我博弈与秘密词推理的前沿探索中,twentle-gemma-2数据集凭借其独特的‘秘密词’(secret_word)结构化对话设计,成为推动模型内在对齐与隐蔽指令理解能力的核心资源。该数据集将训练、验证及自对弈(self_play_01)分片有机结合,特别是包含2000条自对弈样本的配置,直接呼应了当前强化学习与生成式智能体自我进化领域中‘自我对弈微调’(Self-Play Fine-Tuning)的研究热点。通过令模型在包含秘密词的多轮对话中生成与验证答案,研究者可系统性地评估并提升大语言模型在复杂约束下的逻辑连贯性、上下文记忆能力以及对抗性攻击下的稳健性。这一方向不仅为构建更具内省意识与安全边际的通用智能体提供了标准化测试床,也标志着数据集设计从单纯的任务语料搜集向高阶认知机制模拟与验证的范式跃迁。
以上内容由遇见数据集搜集并总结生成


