grammarly/coedit
收藏Hugging Face2023-10-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/grammarly/coedit
下载链接
链接失效反馈官方服务:
资源简介:
CoEdIT数据集是用于训练CoEdIT文本编辑模型的数据集。该数据集包含69k个实例,格式为JSON,每个实例包括任务类型、输入文本和输出文本。数据集主要用于通过指令调优进行文本编辑任务。由于许可限制,该公开版本缺少部分训练和验证数据,特别是简化和形式转换任务中的约13k训练实例和1.5k验证实例。
The CoEdIT dataset is designed for training CoEdIT text editing models. It contains 69k instances in JSON format, where each instance includes task type, input text and output text. This dataset is primarily used for text editing tasks via instruction tuning. Due to licensing restrictions, the public release version lacks some training and validation data, specifically around 13k training instances and 1.5k validation instances for simplification and formalization tasks.
提供机构:
grammarly
原始信息汇总
数据集卡片 for CoEdIT: 通过任务特定指令调优的文本编辑
数据集概述
该数据集用于训练CoEdIT文本编辑模型。详细的数据集信息可以在我们的论文中找到。
数据集结构
数据集采用JSON格式。
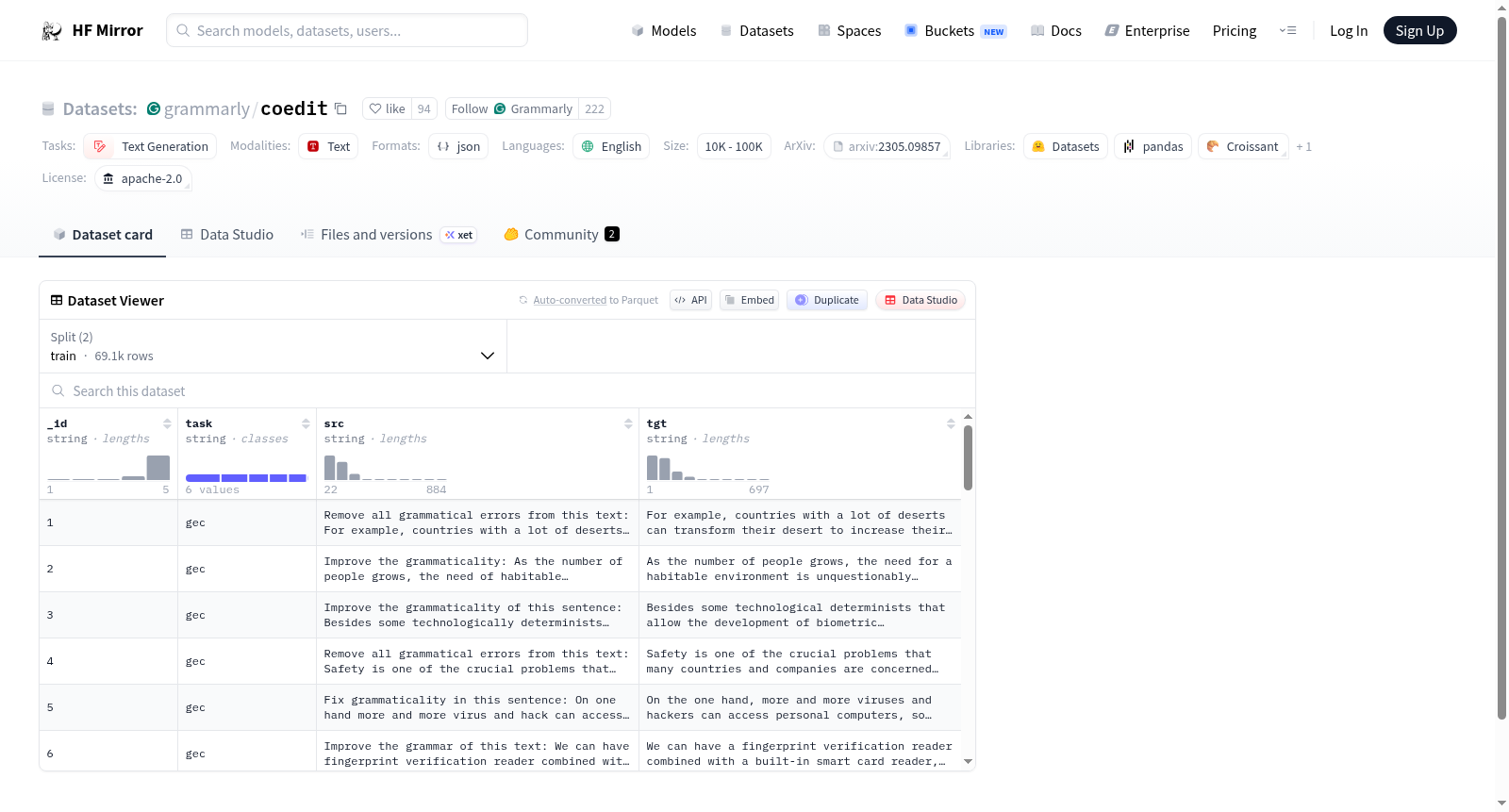
数据实例
json { "_id": 1, "task": "gec", "src": "Improve the grammaticality: As the number of people grows, the need of habitable environment is unquestionably essential.", "tgt": "As the number of people grows, the need for a habitable environment is unquestionably increasing." }
数据字段
_id: 实例IDtask: 文本编辑任务src: 输入文本(格式为instruction: input_text)tgt: 输出文本
使用数据的注意事项
请注意,该数据集包含69k个实例(相对于论文中使用的82k个实例)。这是因为公开发布仅包括从公开可用数据集中获取和整理的实例。具体来说,由于许可限制,它缺少约13k个训练实例和1.5k个验证数据实例,这些实例来自简化和正式转移任务。
引用
plaintext @article{raheja2023coedit, title={CoEdIT: Text Editing by Task-Specific Instruction Tuning}, author={Vipul Raheja and Dhruv Kumar and Ryan Koo and Dongyeop Kang}, year={2023}, eprint={2305.09857}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
构建方式
CoEdIT数据集由Vipul Raheja等人构建,旨在通过指令微调提升文本编辑模型的性能。该数据集以JSON格式存储,包含约6.9万个实例,每个实例由唯一标识符、任务类型(如语法纠错)、输入文本(以“指令:输入文本”形式组织)和输出文本组成。数据来源于公开可用的数据集,经过精心筛选与整合,但由于许可限制,未包含来自简化和形式迁移任务的约1.5万个实例,从而确保了数据集的合法性与可公开性。
特点
CoEdIT数据集的显著特点在于其任务导向的指令设计,每个样本均明确标注了文本编辑任务类型,如语法纠错,使模型能够针对特定任务学习。输入文本采用结构化的指令格式,增强了模型对任务意图的理解。此外,数据集规模适中,涵盖多种编辑场景,为指令微调提供了丰富且聚焦的训练材料,有助于提升模型在多样化文本编辑任务上的泛化能力。
使用方法
使用CoEdIT数据集时,可直接加载JSON格式的实例进行训练或评估。每个样本的输入字段包含任务指令与源文本,模型需根据指令生成对应的目标文本。研究者可将数据集用于指令微调框架,训练文本编辑模型,并参考相关论文中的训练细节。数据集的公开版本已规避许可限制,适合学术研究,但需注意其规模与论文中报告的数据存在差异,以便合理设计实验。
背景与挑战
背景概述
在自然语言处理领域,文本编辑任务长期以来依赖于针对特定错误类型设计的专用模型,缺乏一种统一且灵活的方法来应对多样化的编辑需求。由Vipul Raheja、Dhruv Kumar、Ryan Koo和Dongyeop Kang等研究人员于2023年提出的CoEdIT数据集,旨在通过指令微调(Instruction Tuning)技术,将语法纠错、风格转换、文本简化等多种文本编辑任务整合至单一框架中。该数据集源自公开可用的语料库,包含约6.9万条实例,其核心研究问题在于探索如何利用自然语言指令引导模型执行特定编辑操作,从而替代传统任务特定模型的繁琐设计。CoEdIT的发布为文本编辑领域提供了一种通用范式,显著提升了模型在多任务场景下的适应性与可扩展性,对后续研究如基于指令的生成式编辑模型产生了深远影响。
当前挑战
CoEdIT数据集所面临的挑战首先体现在领域问题的复杂性上:文本编辑任务涵盖语法纠错、形式性转换、文本简化等多种类型,每种任务对输出质量与语义保真度的要求各异,传统单一模型难以在所有任务上达到最优性能。此外,构建过程中遭遇了显著的数据瓶颈——由于许可限制,公共版本缺失了约1.3万条训练数据与1.5万条验证数据,这些数据来自文本简化和形式性转换任务,导致模型在这些子任务上的泛化能力可能受限。同时,指令格式的设计需要兼顾通用性与任务特异性,如何确保指令的清晰性以避免歧义,以及如何平衡多任务训练中的数据分布不均衡,构成了技术实现上的另一大挑战。这些因素共同制约了CoEdIT在真实场景中的鲁棒性与部署效果。
常用场景
经典使用场景
CoEdIT数据集专为基于指令的文本编辑任务而构建,其核心应用场景在于通过自然语言指令引导模型完成多样化的文本修正与润色工作。该数据集涵盖了语法纠错、风格转换、文本简化、流畅性提升等多种编辑任务,每个样本均以“指令+输入文本”的结构呈现,使得模型能够理解并执行具体编辑要求。这种设计不仅适用于训练端到端的文本编辑模型,还广泛应用于零样本或少样本场景下的文本优化研究,成为自然语言处理领域中指令微调范式的重要实践载体。
衍生相关工作
基于CoEdIT数据集,研究者衍生出多项经典工作。例如,后续工作探索了将编辑指令与强化学习结合以提升模型对长文本的修改一致性;另有研究利用该数据集训练轻量级编辑模型并部署于移动端,实现低延迟的文本优化。此外,CoEdIT的指令格式被借鉴用于构建多语言文本编辑数据集,推动跨语言编辑模型的发展。这些衍生工作进一步验证了指令调优在文本编辑领域的可扩展性,并启发了如迭代式编辑、交互式修订等更复杂的编辑范式研究。
数据集最近研究
最新研究方向
在自然语言处理领域,指令微调(Instruction Tuning)正成为提升文本编辑模型泛化能力的前沿范式。CoEdIT数据集专为文本编辑任务设计,涵盖语法纠错、风格转换、简化等多样化指令,推动了从单一任务模型向多任务统一框架的演进。其核心创新在于通过任务特定指令(如“Improve the grammaticality”)引导模型理解编辑意图,无需显式标注编辑操作,显著降低了数据构建成本。该数据集与近期大语言模型(LLMs)的指令跟随能力研究紧密关联,为构建更灵活、可控的文本编辑系统提供了关键训练资源。CoEdIT的发布不仅验证了指令微调在细粒度文本生成任务中的有效性,还为未来探索少样本编辑、跨语言指令迁移等方向奠定了数据基础,对提升AI辅助写作工具的实用性与可解释性具有深远影响。
以上内容由遇见数据集搜集并总结生成


