monster-monash/Traffic
收藏Hugging Face2025-04-14 更新2025-04-12 收录
下载链接:
https://hf-mirror.com/datasets/monster-monash/Traffic
下载链接
链接失效反馈官方服务:
资源简介:
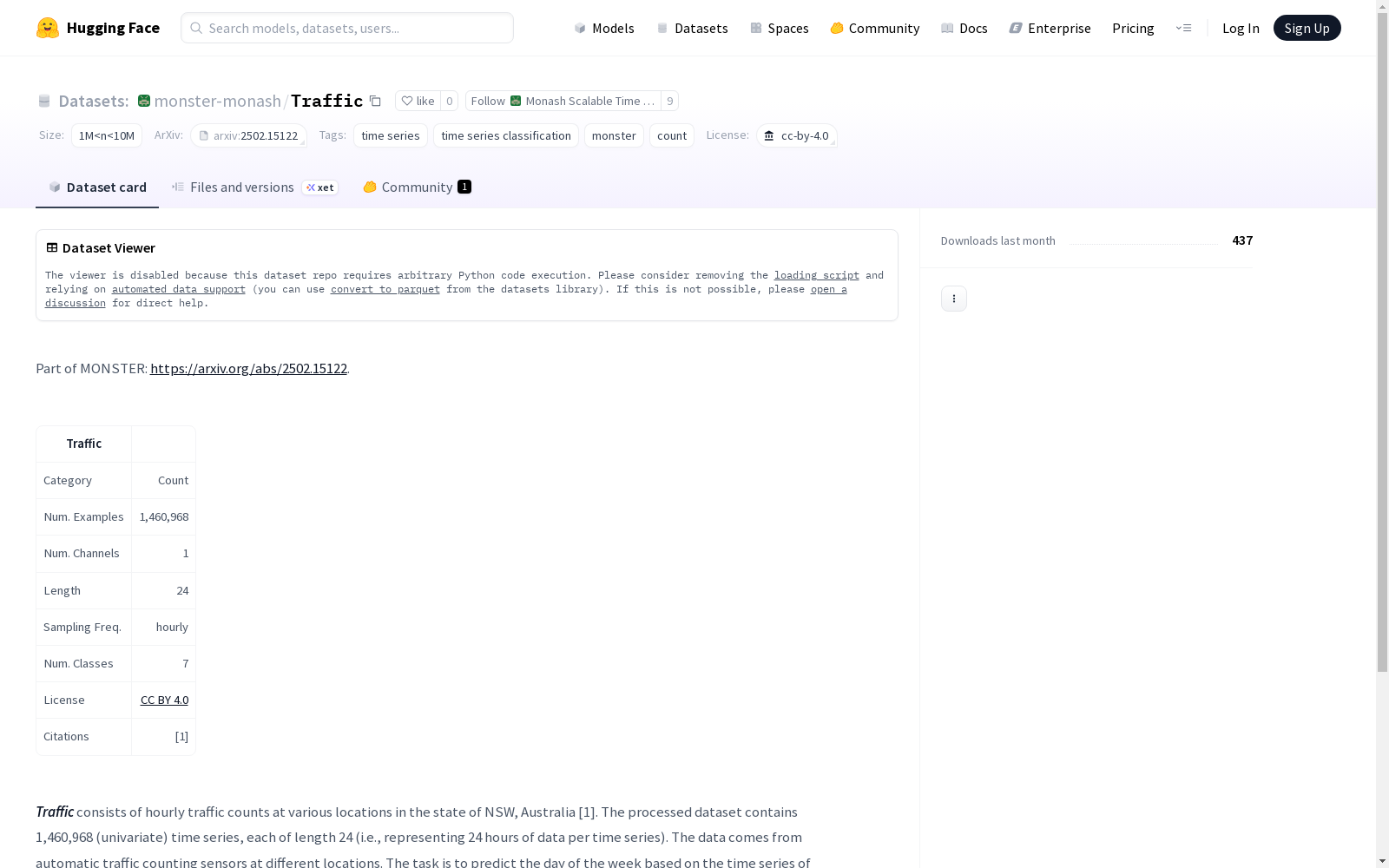
Traffic数据集包含了来自澳大利亚新南威尔士州不同地点的每小时交通计数时间序列,共1,460,968个单变量时间序列,每个序列长度为24小时。该数据集的目的是根据时间序列预测星期几。数据集遵循知识共享署名4.0国际许可,已被划分为分层随机交叉验证折。
The Traffic dataset consists of hourly traffic count time series from various locations in the state of New South Wales, Australia, with a total of 1,460,968 univariate time series, each of length 24 hours. The objective of the dataset is to predict the day of the week based on the time series counts. The dataset is licensed under the Creative Commons Attribution 4.0 International License and has been split into stratified random cross-validation folds.
提供机构:
monster-monash
搜集汇总
数据集介绍
构建方式
Traffic数据集的构建基于澳大利亚新南威尔士州各地点的自动交通计数传感器所收集的原始数据。数据集经过处理,形成了包含1,460,968条单变量时间序列,每条序列长度为24,代表每个时间序列24小时的数据。该数据集的构建旨在通过时间序列计数预测星期几,数据已按照分层随机方式划分为交叉验证折。
特点
Traffic数据集的特点在于其包含了来自不同地点的丰富的时间序列数据,具有1个通道,采样频率为每小时。该数据集包含7个类别,每个类别代表一周中的不同天数。数据集的开放性和许可协议(CC BY 4.0)使得其便于学者和研究人员进行共享和二次开发。
使用方法
使用Traffic数据集时,用户需关注其时间序列的特性和分类任务。数据集已经预处理为分层随机交叉验证折,便于进行模型训练和评估。用户可以直接从提供的数据链接获取数据,并根据具体的模型需求进行相应的数据加载和预处理。引用数据集时,应遵循CC BY 4.0协议,并正确引用数据源和文献。
背景与挑战
背景概述
Traffic数据集,作为MONSTER项目的一部分,由Transport for NSW机构提供,汇集了澳大利亚新南威尔士州不同地点的自动交通计数传感器的数据。该数据集创建于2023年,包含了1,460,968条单变量时间序列,每条序列长度为24小时,旨在通过时间序列数据预测一周中的具体日期。其核心研究问题是基于交通流量的时间序列数据对日期进行分类,对于智能交通系统的研究具有重要的参考价值,对交通工程、城市规划等领域产生了深远的影响。
当前挑战
Traffic数据集在解决基于时间序列的交通流量分类问题上面临诸多挑战。首先,如何准确捕捉并表征交通流量的周期性变化是一大挑战。其次,由于数据源自不同地点,环境因素和地理位置的差异性给构建统一模型带来了困难。此外,数据集构建过程中确保数据质量、处理缺失值和异常值等都是必须克服的挑战。
常用场景
经典使用场景
在时间序列分析领域,Monster-monash/Traffic数据集以其丰富的时序特征和明确的分类任务,成为研究者的首选。该数据集主要用于训练模型,以实现对交通流量时间序列的自动分类,预测特定位置在一天中的不同时间段内的车辆数量变化。
解决学术问题
该数据集解决了时间序列分类中的多个关键问题,包括如何处理非平稳时间序列、如何提高分类准确率、以及如何实现有效的特征提取。这对于交通流量管理、城市规划以及智能交通系统的设计具有重要意义。
衍生相关工作
基于该数据集,研究者们已经开展了一系列相关工作,包括提出新的时间序列分类算法、构建更复杂的预测模型以及探索时间序列数据的深度学习应用,进一步推动了时间序列分析领域的研究进展。
以上内容由遇见数据集搜集并总结生成


