Inst-IT-Bench
收藏Hugging Face2024-12-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Inst-IT/Inst-IT-Bench
下载链接
链接失效反馈官方服务:
资源简介:
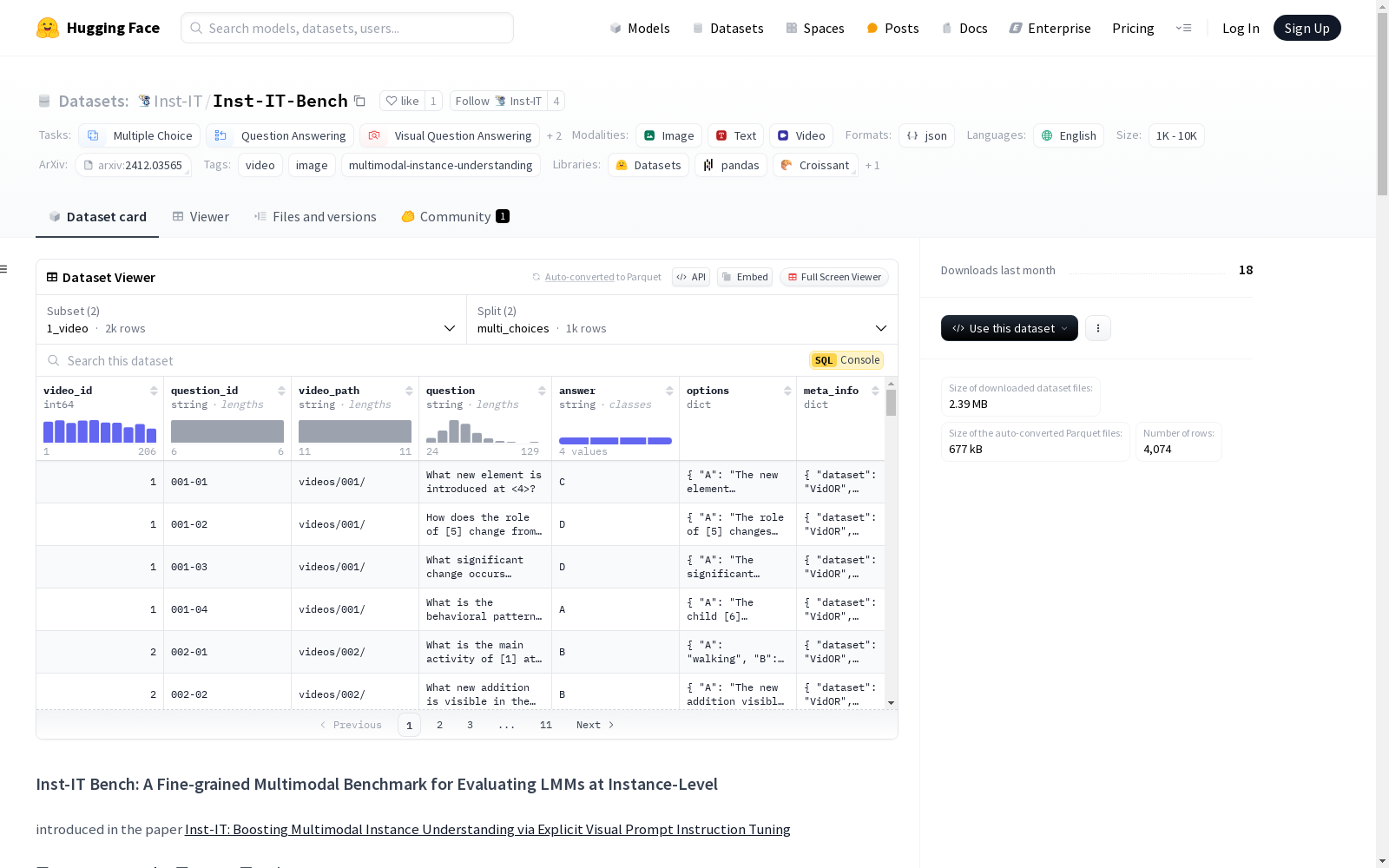
Inst-IT Bench是一个细粒度的多模态基准测试,用于评估大型多模态模型(LMMs)在实例级别的理解能力。该基准测试包括图像和视频两个部分,分别包含1,036个QA对和1,001个QA对,用于338张图像和206个视频。每个QA对都以开放式和多项选择题的形式提供。
创建时间:
2024-12-01
原始信息汇总
Inst-IT Bench: A Fine-grained Multimodal Benchmark for Evaluating LMMs at Instance-Level
数据集概述
- 任务类别:
- 多选题 (multiple-choice)
- 问答 (question-answering)
- 视觉问答 (visual-question-answering)
- 视频文本转文本 (video-text-to-text)
- 图像文本转文本 (image-text-to-text)
- 语言: 英语 (en)
- 标签:
- 视频 (video)
- 图像 (image)
- 多模态实例理解 (multimodal-instance-understanding)
- 数据集规模: 1K<n<10K
- 来源数据集:
- LVVIS
- BRUST
- VidOR
数据集配置
- 配置名称: 1_video
- 数据文件:
- 多选题 (multi_choices):
video_multi_choices.json - 开放式问答 (open_ended):
video_open_ended.json
- 多选题 (multi_choices):
- 数据文件:
- 配置名称: 2_image
- 数据文件:
- 多选题 (multi_choice):
image_multi_choices.json - 开放式问答 (open_ended):
image_open_ended.json
- 多选题 (multi_choice):
- 数据文件:
数据集详情
- 图像部分: 包含338张图像,1,036个问答对。
- 视频部分: 包含206个视频,1,001个问答对。
- 问答格式: 每个问答对都提供开放式和多选题两种格式。
模型评估
- 评估模型: 包括多个开源和专有的图像、视频模型。
- 评估结果: 展示了不同模型在开放式问答和多选题问答中的表现。
引用
bibtex @article{peng2024boosting, title={Inst-IT: Boosting Multimodal Instance Understanding via Explicit Visual Prompt Instruction Tuning}, author={Peng, Wujian and Meng, Lingchen and Chen, Yitong and Xie, Yiweng and Liu, Yang and Gui, Tao and Hang, Xu and Qiu, Xipeng and Wu, Zuxuan and Jiang, Yu-Gang}, journal={arXiv preprint arXiv:2412.03565}, year={2024} }
搜集汇总
数据集介绍
构建方式
在多模态领域,现有的基准测试主要集中于全局理解,而未能深入探讨模型在实例层面的理解能力。为此,Inst-IT-Bench数据集应运而生,旨在通过细粒度的多模态数据评估模型在实例级别的理解能力。该数据集分为图像和视频两个部分,分别包含338张图像的1,036个问答对和206个视频的1,001个问答对。每个问答对均提供开放式和多项选择两种格式,确保了评估的全面性和多样性。
特点
Inst-IT-Bench数据集的显著特点在于其细粒度的实例级别评估能力,涵盖了图像和视频两种模态,且每个问答对均提供开放式和多项选择两种格式,使得评估更加全面。此外,数据集的构建基于LVVIS、BRUST和VidOR等多个源数据集,确保了数据的多样性和广泛性。通过这种设计,Inst-IT-Bench能够有效评估模型在复杂场景下的实例理解能力。
使用方法
使用Inst-IT-Bench数据集进行模型评估时,用户可以根据需求选择图像或视频部分的数据进行测试。数据集提供了开放式和多项选择两种格式的问答对,用户可以根据模型的特点选择合适的评估方式。为了方便用户,数据集还提供了详细的GitHub代码和使用说明,用户可以参考这些资源进行模型评估。通过这种方式,用户能够全面了解模型在实例级别的多模态理解能力。
背景与挑战
背景概述
Inst-IT-Bench数据集由复旦大学等机构的研究人员于2024年提出,旨在评估多模态大模型在实例级理解能力上的表现。该数据集的核心研究问题聚焦于多模态模型在图像和视频中的细粒度实例理解能力,弥补了现有基准数据集在全局理解上的不足。Inst-IT-Bench通过包含图像和视频两个部分,提供了1,036个图像QA对和1,001个视频QA对,涵盖开放式和多选题两种格式,为模型在实例级理解上的评估提供了全面且细致的基准。该数据集的提出对多模态模型的发展具有重要意义,尤其是在视觉与语言结合的领域,推动了模型在复杂场景下的理解能力。
当前挑战
Inst-IT-Bench数据集在构建过程中面临多项挑战。首先,细粒度实例理解要求模型具备对图像和视频中微小细节的识别能力,这对模型的视觉感知和语言推理能力提出了极高的要求。其次,数据集的多样性和复杂性使得标注和验证过程变得异常复杂,尤其是在处理多模态数据时,如何确保标注的一致性和准确性是一个重大挑战。此外,尽管现有模型在全局理解上表现优异,但在细粒度实例理解任务中,即使是当前最先进的模型也表现出明显的不足,这表明该领域仍存在巨大的改进空间。
常用场景
经典使用场景
Inst-IT-Bench数据集的经典使用场景主要集中在多模态实例理解任务中,特别是在图像和视频的细粒度实例级别理解上。该数据集通过提供图像和视频的多项选择题和开放式问答对,评估模型在实例级别的理解能力。例如,模型需要识别图像或视频中的特定对象、行为或事件,并根据这些信息回答问题。这种细粒度的评估方式为多模态模型的开发和优化提供了重要的基准。
实际应用
在实际应用中,Inst-IT-Bench数据集的评估结果可用于指导多模态模型的优化和改进,特别是在需要高精度实例识别的场景中,如自动驾驶、智能监控和医疗影像分析等。通过提升模型在实例级别的理解能力,可以显著提高这些应用的准确性和可靠性,从而推动相关技术在实际场景中的广泛应用。
衍生相关工作
基于Inst-IT-Bench数据集,研究者们开发了一系列相关的经典工作,如LLaVA-Next-Inst-IT和Qwen2-VL-Instruct等模型。这些模型通过在数据集上的训练和评估,显著提升了多模态实例理解的能力。此外,该数据集还激发了更多关于多模态学习和视觉提示指令调优的研究,进一步推动了多模态技术的发展。
以上内容由遇见数据集搜集并总结生成


