EcomMMMU
收藏arXiv2025-08-22 更新2025-11-25 收录
下载链接:
https://hf-mirror.com/datasets/NingLab/EcomMMMU
下载链接
链接失效反馈官方服务:
资源简介:
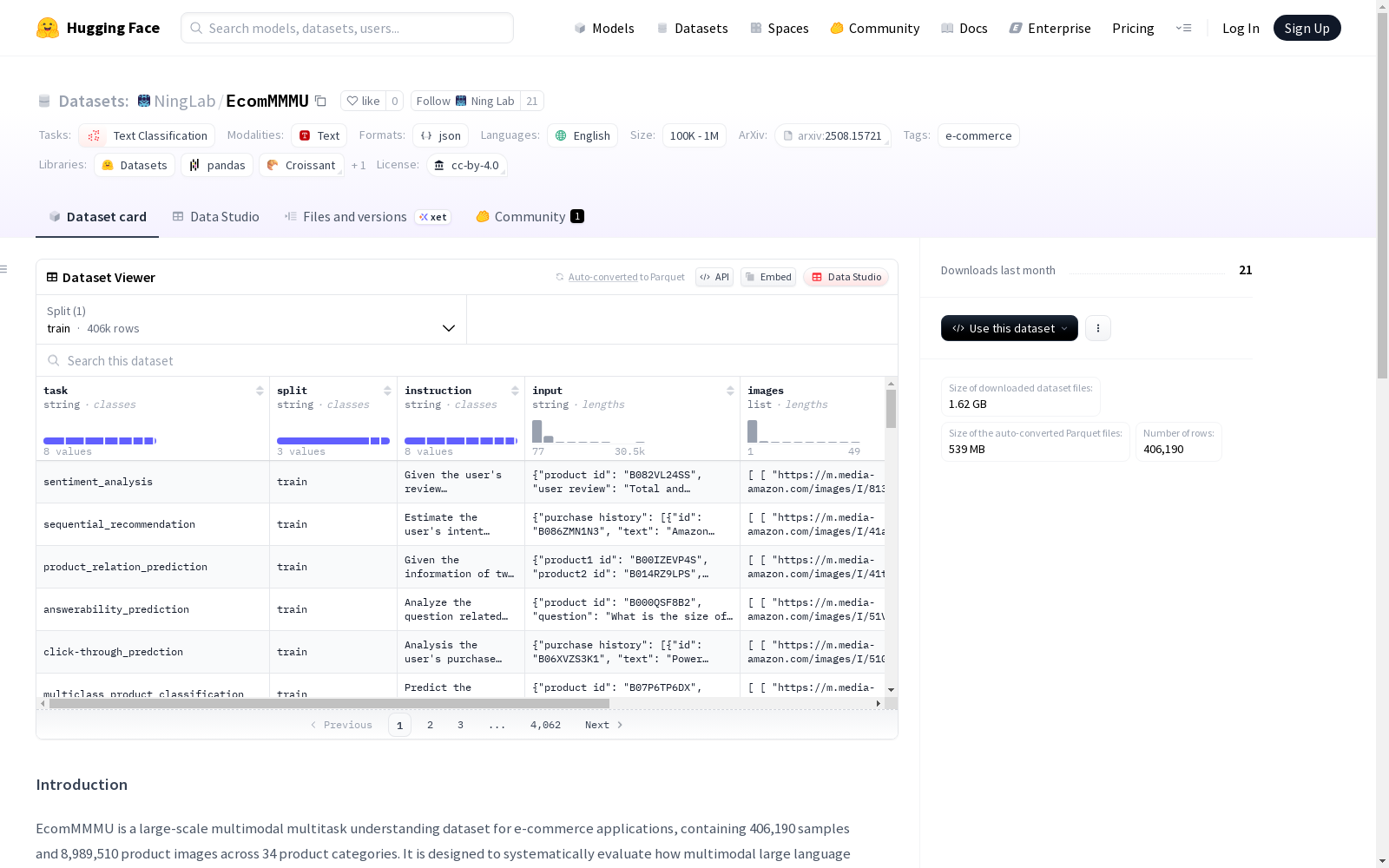
EcomMMMU是一个电子商务多模态多任务理解数据集,包含406,190个样本和8,989,510张产品图片,涵盖了34个类别。该数据集旨在评估和基准测试电子商务任务中视觉内容的实用性。EcomMMMU包含了13,381个视觉显著样本(VSS),用于探索模型在电子商务应用中对图像的利用。数据集由真实世界电子商务应用中的多图像视觉语言数据组成,并设计了8个基本任务和一个专门的VSS子集,以基准测试多模态大型语言模型(MLLMs)有效利用视觉内容的能力。EcomMMMU揭示了产品图像并不总是能提高性能,有时甚至可能降低性能。这表明MLLMs可能在有效利用丰富的视觉内容进行电子商务任务方面存在困难。基于这些洞察,我们提出了SUMEI,这是一种数据驱动的方法,它通过在将图像用于下游任务之前预测视觉效用,有策略地利用多个图像。综合实验表明,SUMEI的有效性和鲁棒性。
EcomMMMU is an e-commerce multimodal and multitask understanding dataset, which contains 406,190 samples and 8,989,510 product images covering 34 categories. This dataset aims to evaluate and benchmark the practicality of visual content in e-commerce tasks. EcomMMMU includes 13,381 visually salient samples (VSS) for exploring how models leverage images in e-commerce applications. The dataset is composed of multi-image visual-language data from real-world e-commerce scenarios, and it designs 8 core tasks and a dedicated VSS subset to benchmark the ability of multimodal large language models (MLLMs) to effectively utilize visual content. EcomMMMU reveals that product images do not always boost model performance, and may even degrade it in certain cases, which indicates that MLLMs may encounter difficulties in effectively leveraging abundant visual content for e-commerce tasks. Based on these insights, we propose SUMEI, a data-driven method that strategically utilizes multiple images by predicting their visual utility before feeding them into downstream tasks. Comprehensive experiments validate the effectiveness and robustness of SUMEI.
提供机构:
俄亥俄州立大学计算机科学与工程学院,俄亥俄州立大学转化数据分析研究所,俄亥俄州立大学生物医学信息学系
创建时间:
2025-08-22
搜集汇总
数据集介绍
构建方式
在电子商务多模态研究领域,EcomMMMU数据集通过整合真实平台的结构化产品元数据、用户评论与行为日志构建而成。该数据集采用严谨的数据收集流程,从亚马逊评论、购物查询等公开资源中筛选出406,190个样本,涵盖34个商品类别。每个样本包含至少8张产品图像及对应文本描述,通过任务指令模板将原始数据转化为覆盖8类核心电商任务的标准化多模态样本,并基于多模型共识机制构建了视觉显著性子集以强化视觉效用的评估。
使用方法
研究者可通过加载数据集中预定义的指令模板,将多图像输入与文本描述共同嵌入多模态大模型进行端到端评估。针对视觉显著性子集的测试需单独提取,通过对比纯文本与多模态输入的性能差异来量化视觉效用。该数据集支持零样本评估范式,用户可直接输入查询指令获取模型响应,同时提供训练集用于微调视觉效用预测器等组件。数据集的标准化输出格式确保了不同模型在相同度量标准下的可比性,为电商多模态研究提供统一评估框架。
背景与挑战
背景概述
EcomMMMU数据集由俄亥俄州立大学计算机科学与工程系的研究团队于2025年创建,旨在解决电子商务多模态理解中的核心问题。该数据集聚焦于评估多模态大语言模型在电子商务任务中有效利用视觉内容的能力,包含406,190个样本和8,989,510张图像,覆盖8个关键任务。其设计通过大规模多图像视觉语言数据,系统性地探索产品图像在增强模型性能时的实际效用,填补了现有数据集在规模和结构上的不足,推动了电子商务多模态学习的发展。
当前挑战
EcomMMMU面临的挑战主要包括两方面:在领域问题方面,电子商务多模态理解需处理图像冗余或误导性内容,这些视觉信息可能降低模型性能而非提升任务准确性;在构建过程中,数据集需从真实电子商务平台聚合多源数据,并设计视觉显著子集以识别文本信息不足的样本,同时确保数据质量和匿名性,这增加了数据清洗和标注的复杂性。
常用场景
经典使用场景
在电子商务多模态研究领域,EcomMMMU数据集作为大规模视觉语言基准,其经典应用场景聚焦于评估多模态大语言模型对商品图像的战略性利用能力。该数据集通过涵盖问答可预测性、用户行为对齐等八大核心任务,系统检验模型在文本信息受限时从多图像中提取关键视觉特征的表现,尤其在视觉显著性子集上凸显了图像筛选对提升模型认知的关键作用。
解决学术问题
该数据集有效解决了多模态学习中视觉内容效用评估的学术难题,揭示了商品图像在特定场景下可能引发性能衰退的现象。通过构建视觉显著性子集与自动化效用评估机制,EcomMMMU为量化视觉冗余性与误导性提供了实证基础,推动了面向电子商务场景的视觉内容战略性筛选方法论的发展,对优化多模态模型决策逻辑具有里程碑意义。
实际应用
在实际电子商务场景中,EcomMMMU支撑了智能导购系统与个性化推荐引擎的优化。通过精准识别商品图像中对用户决策具有实质影响的视觉元素,该数据集助力构建能动态过滤冗余图像的多模态系统,显著提升了跨品类商品检索的准确率与用户交互体验,为平台降低视觉信息过载提供了技术路径。
数据集最近研究
最新研究方向
在电子商务多模态理解领域,EcomMMMU数据集的研究聚焦于探索视觉内容在商品理解中的战略价值。前沿分析揭示了多模态大语言模型在处理丰富商品图像时面临的挑战,即视觉信息并非总能提升任务性能,反而可能因冗余或干扰细节导致性能下降。为此,研究提出了SUMEI方法,通过预测视觉效用实现图像的战略筛选与整合,显著增强了模型在视觉显著场景下的鲁棒性。这一进展不仅推动了多模态学习在电子商务中的精细化应用,也为构建高效能、低噪声的视觉语言模型提供了关键方法论支撑。
相关研究论文
- 1通过俄亥俄州立大学计算机科学与工程学院,俄亥俄州立大学转化数据分析研究所,俄亥俄州立大学生物医学信息学系 · 2025年
以上内容由遇见数据集搜集并总结生成


