lezgi-rus-azer-corpus
收藏Hugging Face2024-10-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/AlidarAsvarov/lezgi-rus-azer-corpus
下载链接
链接失效反馈官方服务:
资源简介:
该数据集用于Lezgian、Russian和Azerbaijani语言之间的神经机器翻译系统。它包括来自圣经、古兰经和Qusar百科全书的并行语料库,以及来自Lezgian语最大报纸Lezgi gazet的单语语料库。数据集分为训练、测试和单语数据文件,分别存储在parallel和mono文件夹中。
创建时间:
2024-10-06
原始信息汇总
Lezgian, Russian, and Azerbaijani Corpus
概述
该数据集包含用于训练和评估Lezgian、Russian和Azerbaijani语言之间神经机器翻译系统的并行和单语数据。
数据集信息
- 许可证: MIT
- 语言:
- Russian
- Azerbaijani
- Lezgian
- 数据规模: 10K<n<100K
配置
- 默认配置:
- 训练数据: parallel/train.csv
- 测试数据: parallel/test.csv
- 单语数据: mono/lezgi_gazet_05102025.csv
数据来源
并行语料库
- 圣经: 从https://bible.com解析,按章节编号对齐(必要时合并)。使用“东方翻译”(CARS)版本的俄语,因为它与Lezgian翻译更一致。
- 古兰经: 从https://quranacademy.org解析。使用Abu Adel的俄语翻译,因为它与Lezgian翻译更一致。
- Qusar百科全书: 从Sedaqet Kerimova的书籍《Qusar, qusarılar. КцӀар, кцӀарвияр》中手动解析和对其。仅包含Lezgian-Azerbaijani对。
单语语料库
- Lezgi gazet: Lezgian语言中最大的报纸。解析了截至2024年10月5日的所有可用档案。
引用
如果您的研究使用了该数据集的结果,请引用以下论文: bibtex @misc{asvarov2024neuralmachinetranslationlezgian, title={Neural machine translation system for Lezgian, Russian and Azerbaijani languages}, author={Alidar Asvarov and Andrey Grabovoy}, year={2024}, eprint={2410.05472}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2410.05472}, }
搜集汇总
数据集介绍
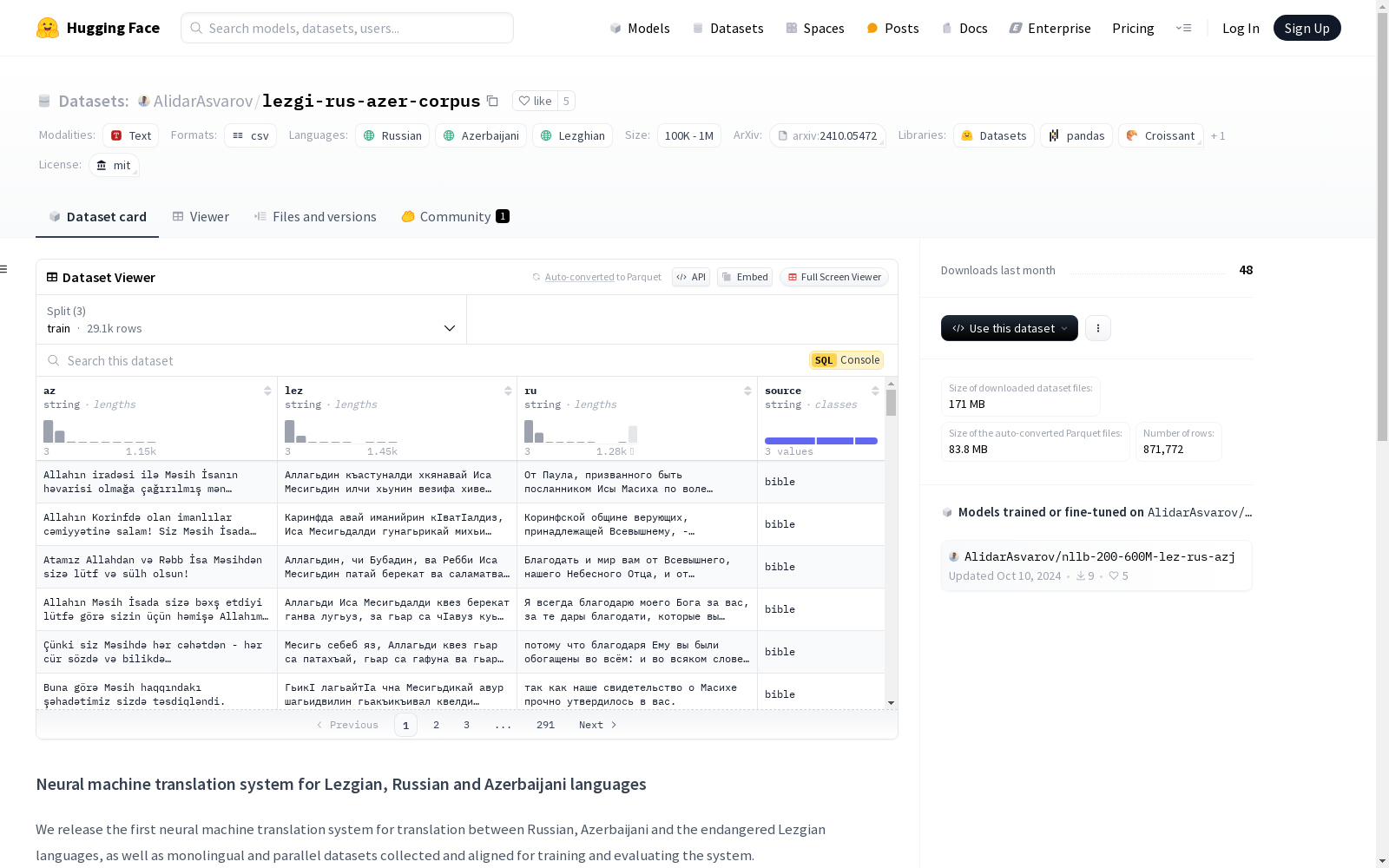
构建方式
该数据集的构建基于多种来源的文本数据,包括圣经、古兰经以及库萨尔百科全书等。圣经和古兰经的文本通过解析在线资源并按照章节编号进行对齐,确保翻译的连贯性。库萨尔百科全书的文本则通过手动解析和对齐,仅包含列兹金语和阿塞拜疆语的对齐数据。此外,数据集还包含从列兹金语报纸《Lezgi gazet》中提取的单语文本,涵盖了截至2024年10月5日的所有可用档案。
特点
该数据集的特点在于其多语言性,涵盖了列兹金语、俄语和阿塞拜疆语三种语言。数据集不仅包含平行语料,还提供了单语语料,特别是列兹金语的单语文本,为濒危语言的保护和翻译研究提供了宝贵的资源。此外,数据集的构建注重文本的连贯性和对齐质量,确保了翻译系统的训练和评估效果。
使用方法
该数据集主要用于神经机器翻译系统的训练和评估,支持列兹金语、俄语和阿塞拜疆语之间的互译。用户可以通过加载数据集的平行语料进行翻译模型的训练,或利用单语语料进行语言模型的预训练。数据集的分割方式明确,包含训练集、测试集和单语集,便于用户根据需求进行灵活使用。引用时请参考提供的论文以支持相关研究。
背景与挑战
背景概述
Lezgi-Rus-Azer-Corpus数据集于2024年由Alidar Asvarov和Andrey Grabovoy等人发布,旨在为濒危的列兹金语(Lezgian)与俄语、阿塞拜疆语之间的神经机器翻译提供支持。该数据集包含平行语料库和单语语料库,涵盖了《圣经》、《古兰经》以及《库萨尔百科全书》等多样化的文本来源。列兹金语作为一种高加索地区的濒危语言,其语言资源的稀缺性使得该数据集的发布具有重要的学术价值。通过构建这一数据集,研究人员不仅推动了多语言机器翻译技术的发展,还为濒危语言的保护和数字化提供了新的研究工具。
当前挑战
Lezgi-Rus-Azer-Corpus数据集的构建面临多重挑战。首先,列兹金语作为一种濒危语言,其可用文本资源极为有限,数据收集的难度显著增加。其次,平行语料库的构建需要对不同语言的文本进行精确对齐,尤其是《圣经》和《古兰经》这类宗教文本的翻译版本存在较大差异,对齐过程需要极高的语言学专业知识。此外,单语语料库的构建依赖于列兹金语报纸的数字化存档,其文本质量和格式的不一致性也为数据处理带来了额外挑战。这些问题的解决不仅需要技术上的创新,还需要跨学科的合作与资源整合。
常用场景
经典使用场景
在自然语言处理领域,lezgi-rus-azer-corpus数据集为研究人员提供了一个宝贵的资源,用于训练和评估神经机器翻译系统。该数据集特别适用于处理俄罗斯语、阿塞拜疆语以及濒危的列兹金语之间的翻译任务。通过其包含的平行语料库和单语语料库,研究人员能够深入探索这些语言之间的复杂关系,并开发出高效的翻译模型。
解决学术问题
lezgi-rus-azer-corpus数据集解决了多语言神经机器翻译中的关键问题,特别是在处理低资源语言如列兹金语时。通过提供高质量的平行语料库,该数据集使得研究人员能够克服数据稀缺的挑战,从而推动了对这些语言翻译技术的研究。这不仅有助于保存和推广濒危语言,还促进了跨文化交流和理解。
衍生相关工作
基于lezgi-rus-azer-corpus数据集,已经衍生出多项经典工作,包括但不限于多语言神经机器翻译模型的开发、语言对齐算法的改进以及濒危语言保护技术的研究。这些工作不仅推动了相关领域的技术进步,也为未来的研究提供了坚实的基础。
以上内容由遇见数据集搜集并总结生成


