BEAT
收藏arXiv2022-09-20 更新2024-06-21 收录
下载链接:
https://pantomatrix.github.io/BEAT/
下载链接
链接失效反馈官方服务:
资源简介:
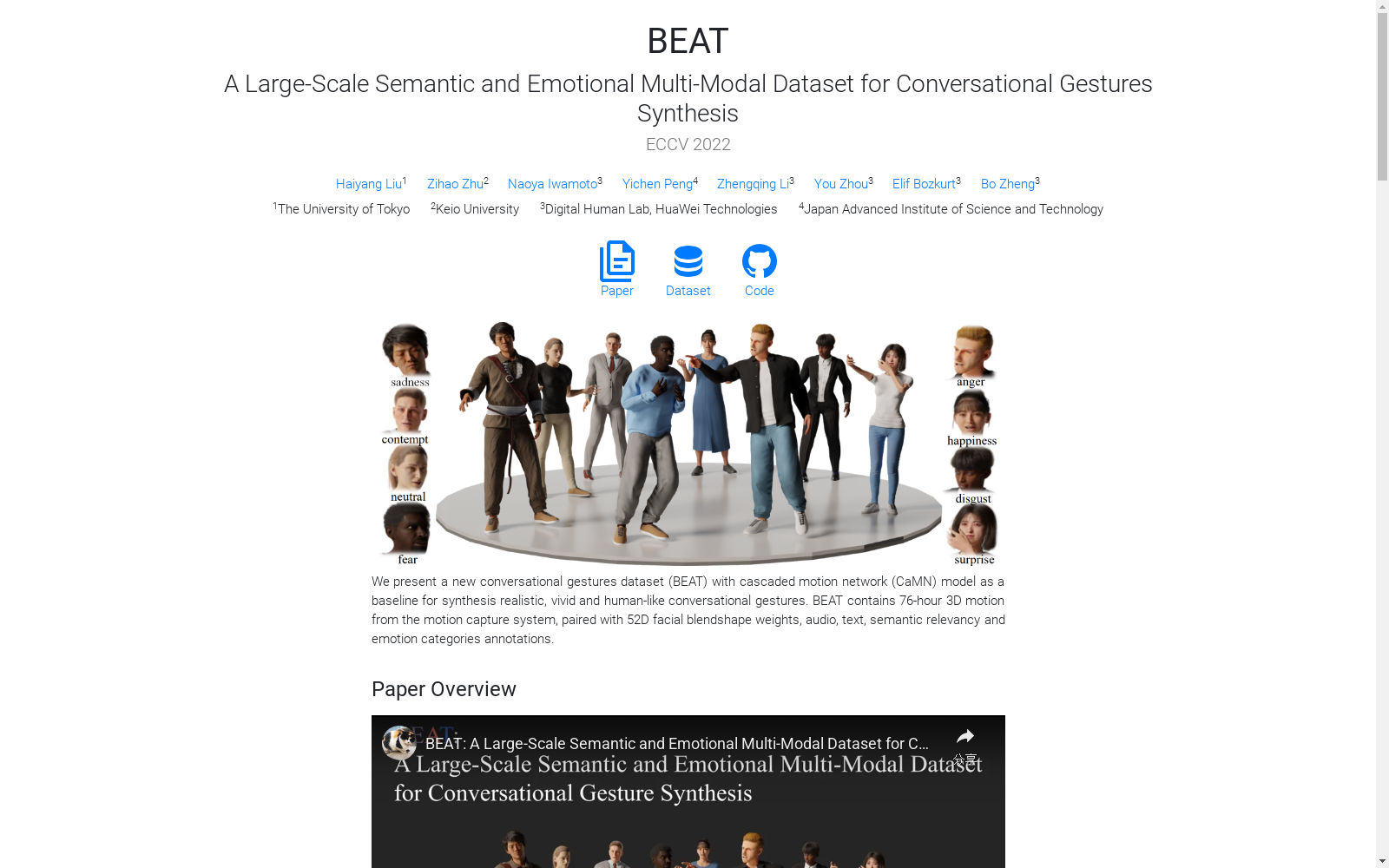
BEAT是一个大规模的多模态动作捕捉数据集,包含76小时的高质量数据,涵盖30位演讲者在四种不同语言中表达八种不同情绪的动作。数据集包含3200万帧级别的情绪和语义相关性标注,确保了数据的多样性和丰富性。创建过程中,通过严格的控制和设计,确保了数据的质量和多样性。BEAT数据集的应用领域广泛,包括可控手势合成、跨模态分析和情感手势识别等,旨在解决现实对话中手势合成的复杂性和多样性问题。
BEAT is a large-scale multimodal motion capture dataset that contains 76 hours of high-quality data, covering motions of 30 speakers expressing eight distinct emotions across four different languages. The dataset includes 32 million frame-level annotations of emotional and semantic relevance, ensuring the diversity and richness of the data. Strict control and design were implemented during its construction to guarantee both data quality and diversity. The BEAT dataset has a wide range of application scenarios, including controllable gesture synthesis, cross-modal analysis, emotional gesture recognition and other fields, aiming to address the complexity and diversity challenges of gesture synthesis in real-world conversations.
提供机构:
东京大学
创建时间:
2022-03-10
搜集汇总
数据集介绍
构建方式
在对话手势合成领域,高质量多模态数据的稀缺长期制约着研究的深入。BEAT数据集通过精心设计的动作捕捉方案构建,采用16台同步相机以120Hz频率记录身体运动,并结合ARKit系统以60Hz捕获52个面部混合形状权重。数据采集分为对话与独白两个环节,涵盖20个预定义话题和8种情感类别。30位来自不同国家的说话者使用四种语言进行录制,通过专业指导确保情感表达的真实性。所有音频以48kHz采样率记录,最终形成76小时高质量多模态数据。
特点
该数据集最显著的特征在于其前所未有的规模与标注完整性。BEAT包含超过3200万帧级别的语义相关性与情感标注,涵盖愤怒、快乐、恐惧等八种精细情感类别。数据模态的多样性尤为突出,同步提供身体关节旋转、手部运动、面部混合形状权重、语音波形及文本转录。说话者背景的精心设计确保了风格多样性,包含15位女性参与者与四种语言变体。语义标注通过众包平台获得,由118位通过资格测试的标注者完成,为研究手势与语义的关联提供了量化基础。
使用方法
研究者可利用该数据集开展多模态手势生成的模型训练与评估。数据以BVH格式存储身体手势,WAV格式存储音频,JSON格式存储面部权重,并附有TextGrid格式的文本对齐标注。典型使用流程包括:首先基于六种模态(文本、情感、说话者身份、音频、面部表情、语义分数)训练生成模型;其次利用提供的基准指标——语义相关手势召回率(SRGR)评估生成手势的语义一致性;最后可通过对比不同模态的消融实验探究各因素对手势合成的影响。数据集已划分训练/验证/测试集,支持端到端生成与跨模态分析任务。
背景与挑战
背景概述
在虚拟现实与数字人交互技术蓬勃发展的时代背景下,对话手势的逼真合成成为连接人机自然交互的关键桥梁。BEAT数据集由东京大学、庆应义塾大学及华为技术有限公司等机构的研究团队于2022年构建,旨在解决多模态条件下生成具有语义与情感表现力的对话手势这一核心研究问题。该数据集通过高精度动作捕捉技术,收录了30位说话者在四种语言、八种情感状态下的76小时多模态数据,并提供了3200万帧级别的语义与情感标注。BEAT以其前所未有的规模与标注深度,为可控手势合成、跨模态分析与情感计算等领域提供了至关重要的研究基石,显著推动了相关领域从单一模态驱动向多模态融合建模的范式演进。
当前挑战
BEAT数据集致力于攻克对话手势合成领域的核心挑战,即如何生成与语音、语义、情感及说话者身份高度协同的逼真且富有表现力的手势。具体挑战体现在:其一,领域问题层面,需解决多模态信息(音频、文本、面部表情、情感、说话者身份、语义)的复杂融合与解耦问题,以生成既符合语境又具有个人风格的自然手势;其二,数据构建层面,面临高质量动作捕捉数据采集成本高昂、多语言多情感标注一致性难以保证、大规模帧级语义标注主观性强且需高效质量控制等工程与算法挑战。这些挑战共同指向了构建一个能够支撑下一代手势合成模型训练与评估的标准化、高质量数据平台的复杂性。
常用场景
经典使用场景
在虚拟角色动画生成领域,BEAT数据集为多模态驱动的对话手势合成提供了核心训练资源。其经典应用场景在于构建端到端的生成模型,通过融合语音、文本、面部表情、情感标签及说话人身份等多维度信息,合成与语义内容高度相关且富有表现力的肢体动作。研究者利用该数据集的大规模高质量运动捕捉数据,训练如CaMN等级联网络架构,实现从多模态输入到自然手势序列的精准映射,显著提升了合成动作的逼真度与多样性。
解决学术问题
BEAT数据集有效解决了对话手势合成研究中长期存在的多模态数据缺失问题。传统方法因缺乏大规模、高质量且带有精细标注的配对数据,难以深入探究手势与面部表情、情感状态及语义内容之间的复杂关联。该数据集通过提供76小时的多模态运动捕捉数据,包含3200万帧级情感与语义相关性标注,使得研究者能够定量分析手势生成的跨模态依赖关系,并推动可控、个性化及情感化手势合成模型的发展,填补了该领域在数据规模与标注完整性上的空白。
衍生相关工作
BEAT数据集的发布催生了一系列围绕多模态手势合成的创新研究。其基线模型CaMN启发了后续工作对级联架构与多模态融合机制的深入探索。基于BEAT的语义与情感标注,研究者发展了更精细的语义相关性评估指标(如SRGR的改进版本)及情感条件生成模型。该数据集也促进了跨模态表征学习、说话人风格解耦及零样本手势生成等方向的研究,为GestureDiffusion、Emotion-Aware Gesture Synthesis等后续工作提供了至关重要的训练与评估基准。
以上内容由遇见数据集搜集并总结生成


