home-credit-default-risk
收藏Hugging Face2026-05-20 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/mohameddhameem/home-credit-default-risk
下载链接
链接失效反馈官方服务:
资源简介:
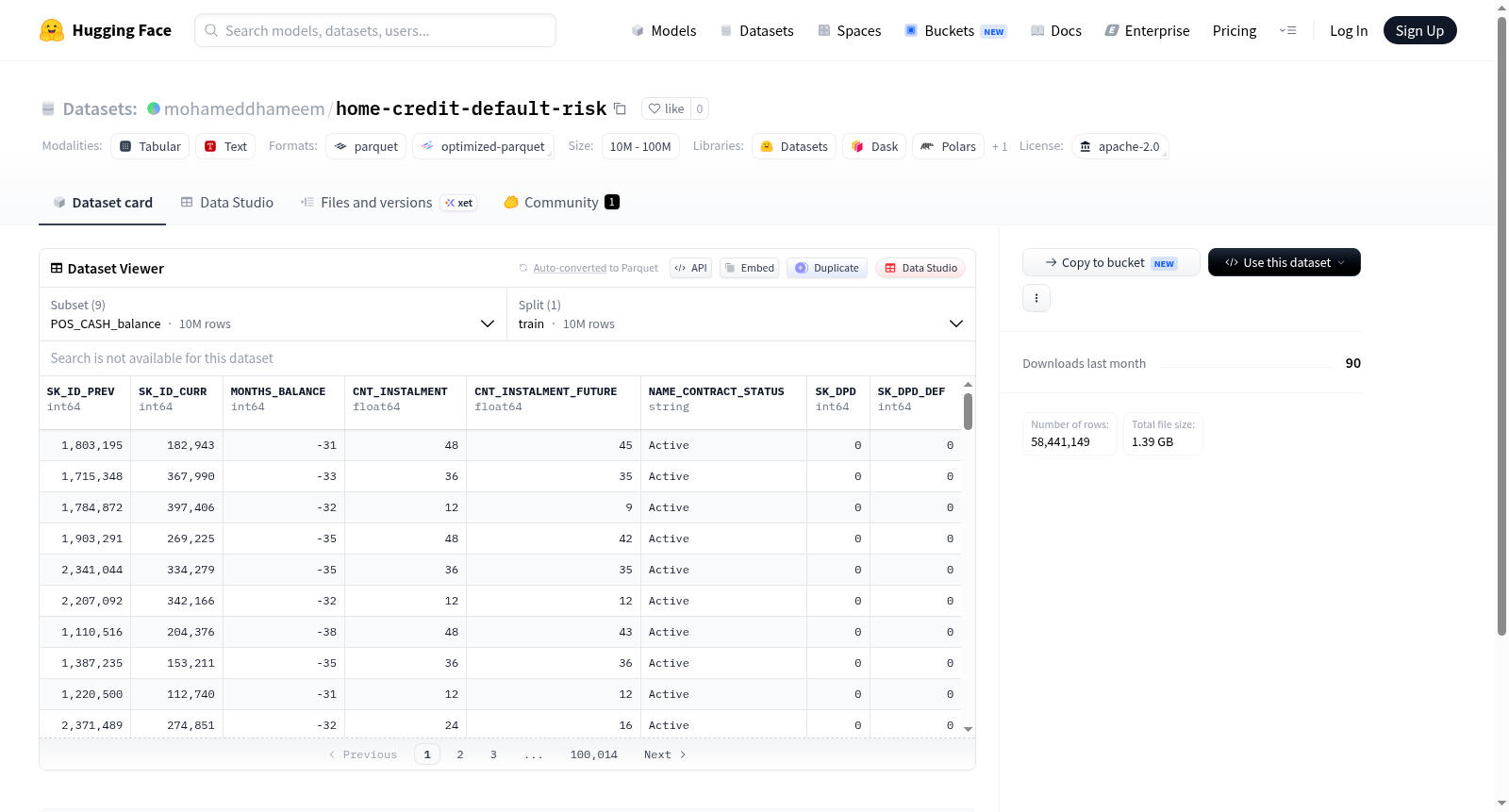
该数据集是一个结构化的金融信贷数据集,包含多个相互关联的数据表,主要用于信贷风险评估和违约预测任务。数据集由9个独立表格组成:POS_CASH_balance(POS现金余额,1000万样本)、application_test(申请测试集,4.8万样本)、application_train(申请训练集,30.7万样本)、bureau(征信局记录,171万样本)、bureau_balance(征信局余额记录,2730万样本)、credit_card_balance(信用卡余额,384万样本)、installments_payments(分期付款记录,1360万样本)、previous_application(历史申请记录,167万样本)以及sample_submission(提交样例)。数据字段涵盖客户基本信息(如性别、年龄、职业、收入)、财务信息(如信用额度、年金、商品价格)、申请信息(如合同类型、申请时间)、信用历史(如征信记录、逾期天数、付款状态)、资产信息(如房产面积、楼层数、建筑年份)以及行为数据(如社交圈观察、电话变更、文档标志)。表格通过客户ID(SK_ID_CURR)和先前申请ID(SK_ID_PREV)进行关联,形成一个完整的信贷生命周期视图。该数据集适用于监督学习中的二分类预测任务(例如application_train中的TARGET字段),典型应用场景包括客户信用评分、贷款违约预测和风险管理模型开发。
This dataset is a structured financial credit dataset containing multiple interrelated data tables, mainly used for credit risk assessment and default prediction tasks. It consists of 9 independent tables: POS_CASH_balance (POS cash balance, 10 million samples), application_test (test application set, 48,000 samples), application_train (training application set, 307,000 samples), bureau (credit bureau records, 1.71 million samples), bureau_balance (credit bureau balance records, 27.3 million samples), credit_card_balance (credit card balance, 3.84 million samples), installments_payments (installment payment records, 13.6 million samples), previous_application (historical application records, 1.67 million samples), and sample_submission (submission template). The data fields cover customer basic information such as gender, age, occupation, income, financial information such as credit limit, annuity, commodity price, application information such as contract type, application time, credit history such as credit bureau records, overdue days, payment status, asset information such as property area, number of floors, construction year, and behavioral data such as social circle observations, phone number changes, document flags. The tables are linked via customer ID (SK_ID_CURR) and previous application ID (SK_ID_PREV), forming a complete credit lifecycle view. This dataset is suitable for binary classification prediction tasks in supervised learning, e.g., the TARGET field in application_train, with typical application scenarios including customer credit scoring, loan default prediction and risk management model development.
创建时间:
2026-05-19
搜集汇总
数据集介绍
构建方式
在消费金融与风险评估的研究领域中,高维异构数据的整合对预测违约行为至关重要。Home Credit Default Risk数据集由Home Credit公司提供,旨在通过机器学习技术挖掘信贷申请人的违约风险。该数据集构建于真实业务场景之上,包含多个关联数据表,通过唯一的客户标识符(SK_ID_CURR)和贷款标识符(SK_ID_PREV)进行联结。具体而言,核心表为application_train,记录了每笔贷款申请时的客户人口统计、资产状况及信用历史等特征;同时配套了bureau、bureau_balance、POS_CASH_balance、credit_card_balance、installments_payments和previous_application等辅助表,分别从征信机构、历史贷款、信用卡及分期付款等维度追踪客户的动态信用行为。所有数据均以表格形式存储,并划分为训练集与测试集,便于模型训练与评估。
特点
该数据集最显著的特点在于其多源异构信息的深度融合与时间序列动态捕捉能力。其涵盖特征维度极为丰富,包括客户基本属性、收入与信贷金额、住房与职业信息、外部信用评分(EXT_SOURCE)以及来自征信局的百项以上历史指标。此外,通过分期付款余额表、信用卡月度账单和还款明细表,数据集能够反映客户在数月乃至数年内的还款行为演变,为预测模型提供了时序化视角。数据规模庞大,总计包含超过3000万条记录,各子表数据量从数万至数千万条不等,充分体现了现实金融数据的复杂性与稀疏性。值得注意的是,数据集中存在大量缺失值,这真实映射了实际业务中信息缺失的常态,从而对算法的鲁棒性提出了更高要求。
使用方法
研究人员可利用Hugging Face Datasets库便捷地加载该数据集。首先通过load_dataset函数指定数据集名称'home-credit-default-risk',并选择所需的配置名,例如'application_train'用于主训练数据,'bureau'用于征信局数据。加载后返回的数据集对象支持转换为Pandas DataFrame格式,以便利用Scikit-learn、XGBoost或PyTorch等框架进行特征工程与建模。由于数据以多表形式存在,典型的使用流程包括:以application_train为核心,通过SK_ID_CURR主键依次左连接bureau、previous_application等辅助表,并辅以聚合操作提取客户的历史行为统计特征。TARGET列作为二分类标签(0表示正常还款,1表示违约),是模型预测的目标变量。此外,提供的application_test与sample_submission可用于生成与提交预测结果,便于参与竞赛或复现实验。
背景与挑战
背景概述
Home Credit Default Risk数据集诞生于2018年,由Home Credit集团与Kaggle平台联合发布,旨在推动信贷风险评估领域的机器学习研究。该数据集聚焦于信用贷款违约预测这一核心问题,通过整合客户人口统计学信息、历史交易记录、信贷机构数据等多维度信息,构建了一个包含30余万训练样本及多个子表(如POS_CASH_balance、bureau等)的复杂结构化数据资源。作为金融科技领域的标志性基准,该数据集极大促进了LightGBM等梯度提升模型在信用评分中的应用,启发了大量关于特征工程、不平衡分类及可解释人工智能的研究,对普惠金融的风险控制具有深远影响。
当前挑战
该数据集面临两大核心挑战。在领域问题层面,信贷违约预测需处理极度类别不平衡(正样本不足5%)、高维稀疏特征与多源异构数据融合的难题,传统逻辑回归与集成学习方法在召回率与精确率间难以取得平衡。在构建过程中,数据集遭遇了跨表数据对齐的复杂性——7个子表包含超过700个离散与连续特征,时间跨度长达数年的分期付款、余额变动等时序数据需要精细的聚合操作,同时存在大量缺失值(如EXT_SOURCE外部评分字段缺失率超过30%),对数据清洗与预处理策略提出了严苛要求。
常用场景
经典使用场景
Home Credit Default Risk数据集是金融风控领域极具代表性的基准数据资源,由Home Credit集团在Kaggle竞赛中发布,旨在利用机器学习方法预测客户贷款违约风险。该数据集涵盖了约30万条训练样本和丰富的多源信息,包括客户人口统计学特征、信贷历史、信用局记录、信用卡余额及分期付款行为等,总计超过170个特征变量。其经典使用场景集中于构建二分类模型以预测借款人是否会违约,研究者常借助逻辑回归、梯度提升树、神经网络等算法来挖掘特征与违约标签之间的复杂关联,同时处理类别不平衡、缺失值填充和时序特征聚合等挑战。该数据集不仅为信用评分模型提供了天然试验场,也推动了结构化数据预处理与特征工程技术的进步。
实际应用
实际应用中,Home Credit Default Risk数据集直接服务于消费金融行业的信贷审批与贷后管理。金融机构可基于该数据集训练的风险预测模型,对贷款申请者的还款能力进行实时评估,从而优化授信决策、降低坏账率。例如,模型输出的违约概率可作为审批阈值的参考依据,辅助人工审核或实现自动化决策流。此外,该数据集还可用于开发客户分层系统,对不同风险等级的借款人制定差异化的利率与还款方案,提升资金配置效率。其真实业务场景中的变量(如外部信用评分、职业类型、住房状况)均直接映射到实际风控指标,使得模型具备跨组织迁移的潜力。
衍生相关工作
该数据集衍生了大量经典研究工作,涵盖自动化特征工程、可解释机器学习与对抗验证等方向。例如,LightGBM作者团队在其官方示例中多次引用该数据集,验证了GOSS与EFB算法的高效性;Kaggle竞赛中涌现的Top解决方案广泛采纳了均值编码、目标编码及时间窗口聚合等特征构造技巧。此外,研究者基于该数据提出了针对不平衡数据的集成采样框架,以及利用SHAP值进行全局与局部解释的违约归因分析。近期工作则延伸至图神经网络的借贷关系建模,将客户与历史申请构建为异构图,利用消息传递机制捕捉交互特征。这些衍生贡献不仅丰富了风控模型的技术栈,也树立了金融数据挖掘的迭代标杆。
以上内容由遇见数据集搜集并总结生成


