ChaoticEconomist/University-Research-Publications-Dataset_SRM-2019-2024
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ChaoticEconomist/University-Research-Publications-Dataset_SRM-2019-2024
下载链接
链接失效反馈官方服务:
资源简介:
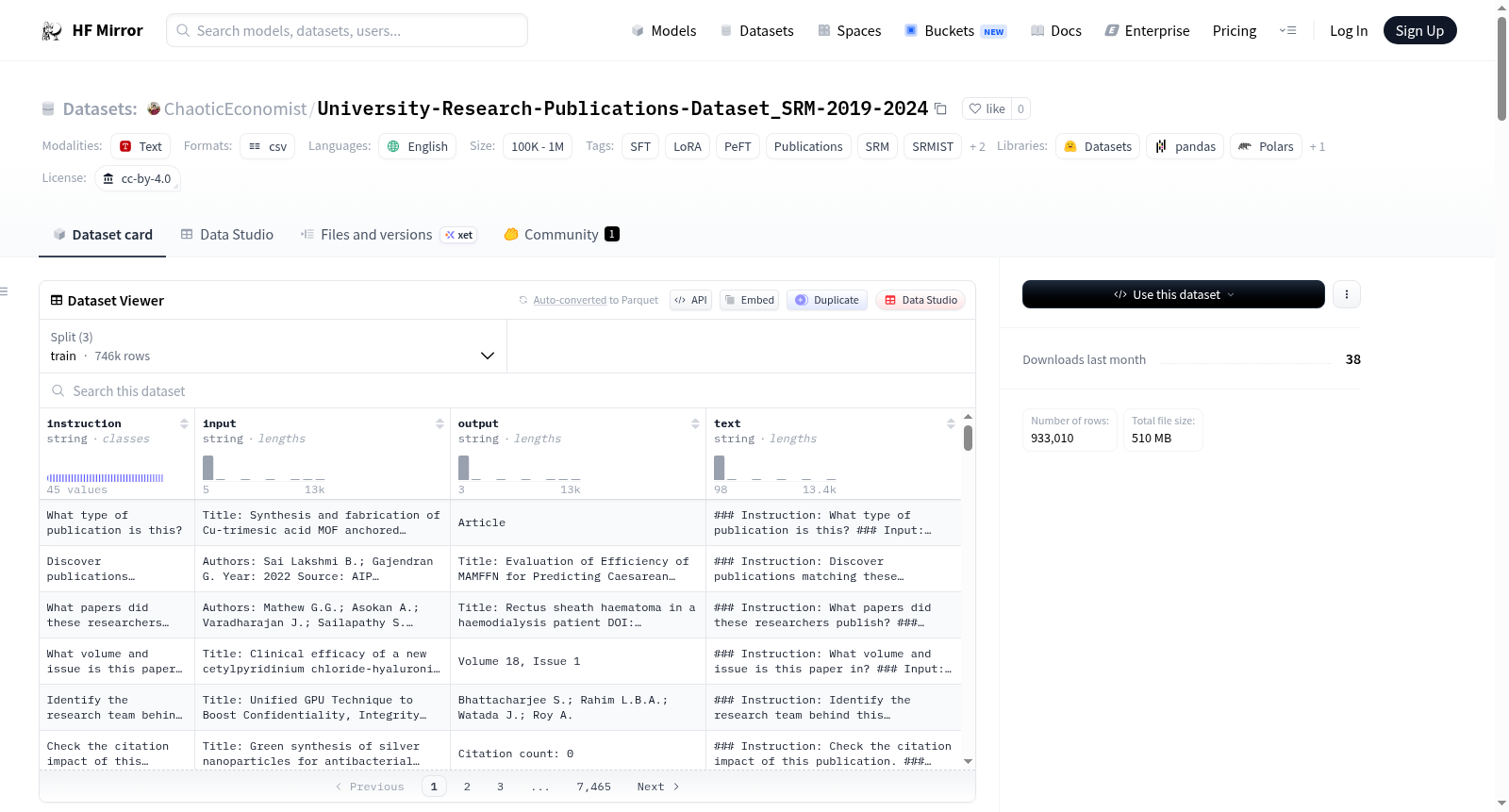
该数据集包含2019年至2024年SRM科学与技术学院的出版物元数据,专为指令跟随和问答任务设计。数据集将22,809篇独特出版物转化为933,010个指令-响应对,涵盖45种不同的指令类型。适用于训练AI模型理解和检索学术出版物信息。
This dataset contains publication metadata from SRM Institute of Science and Technology spanning 2019-2024, formatted for instruction-following and question-answering tasks. The dataset includes 22,809 unique publications transformed into 933,010 instruction-response pairs across 45 diverse instruction types. Perfect for training AI models to understand and retrieve academic publication information!
提供机构:
ChaoticEconomist
搜集汇总
数据集介绍
构建方式
该数据集源自SRM理工学院2019至2024年间于Scopus索引的学术出版物元数据。构建过程历经精心编排:首先,通过自动化工具从官方研究门户提取了22,809篇论文的完整元数据,涵盖作者、标题、DOI、来源期刊、引文数量及开放获取状态等核心字段。随后,基于每条记录,利用模板化与规则驱动的方法,生成了涵盖45种指令类型的多样化查询-响应对,例如作者识别、引文分析、时域检索及元数据摘要等任务。最终,这些对组被格式化为Alpaca指令模板结构,并以80%、10%、10%的比例划分为训练集、验证集和测试集,总计产出933,010个高质量示例。
特点
该数据集的核心特质在于其规模宏大且指令类型高度丰富。以22,809篇出版物为基础,扩展至近百万条指令-响应对,覆盖DOI查询、作者分析、引文评估、期刊检索、时域趋势、卷期信息、文献类型、开放获取状态及综合元数据等十大类共45种任务,确保了模型在学术信息检索领域的泛化能力。数据质量经过严格把控,所有条目均包含有效响应,无重复实例且指令分布均衡,每一类占比控制在0.6%至2.5%之间。此外,数据集严格遵循Alpaca指令格式,结构规整,便于直接用于监督微调与参数高效微调。
使用方法
该数据集专为训练与评估学术文献理解与检索能力的大语言模型而设计。用户可通过Hugging Face Datasets库加载,并直接将其作为指令微调任务的基础,支持如LoRA、PeFT等参数高效微调方法。数据集中的每条记录均包含instruction、input、output及text四个字段,可灵活用于构建问答系统、研究助手或文献检索工具。典型的应用场景包括模型在给定论文标题或DOI后输出作者列表、引文数量或开放获取状态,亦可用于多条件搜索或生成完整的引用条目。建议在微调时采用标准化分拆,以避免数据泄露并保证评估的公正性。
背景与挑战
背景概述
该数据集名为University-Research-Publications-Dataset_SRM-2019-2024,由Anuraag Rath于2026年4月发布,源自印度SRM科学与技术学院(SRM Institute of Science and Technology)2019至2024年间收录于Scopus索引的学术出版物。核心研究问题在于构建一个面向学术文献检索与问答的指令微调数据集,涵盖22,809篇出版物,衍生出933,010条指令-响应对,涉及45种指令类型。该数据集填补了特定机构层面、结构化学术元数据在大语言模型微调领域的空白,为学术AI助手、文献发现工具及引文分析系统的开发提供了高质量训练资源,对推动自然语言处理在教育与科研场景中的应用具有重要影响。
当前挑战
该数据集主要应对两大挑战。其一,在领域问题层面,传统学术检索系统难以理解自然语言查询的语义,无法灵活应答如作者合作、引文影响或时间趋势等多维问题,而本数据集通过多样化指令类型训练模型增强语义理解与精准回复能力。其二,在构建过程中,数据收集面临Scopus元数据字段不完整(如缺失摘要或关键词)的局限,需通过规则生成避免空输出;同时,从有限出版物中衍生近百万样本时,需平衡指令分布避免偏差,并确保无重复条目与格式统一,这些均对数据清洗与增强流程提出了较高要求。
常用场景
经典使用场景
该数据集在学术领域最经典的应用场景莫过于作为指令微调和检索增强生成的基石。通过将22,809篇斯洛伐克理工大学(SRM Institute)的Scopus索引出版物元数据,精心转化为933,010条覆盖45种指令类型的问答对,数据集为训练大型语言模型理解和处理学术文献提供了高质量的监督信号。研究者利用其Alpaca格式的结构,能够轻松微调模型以执行诸如作者识别、论文标题检索、DOI交叉引用、引用计数查询、期刊来源确定及时间范围过滤等细粒度信息抽取任务,从而构建智能化的学术搜索引擎和科研助手。
衍生相关工作
该数据集的发布催生了一系列极具影响力的衍生工作。一方面,研究者基于此数据集构建了专门针对学术领域的领域基座模型,通过在中英文语料上进行对比学习,显著提升了模型对学术命名实体(如作者名、期刊缩写、DOI格式)的识别鲁棒性。另一方面,它启发了“学术指令-响应”数据自动生成工具的开发,该工具能够将任意机构或学科的出版物清单转化为类似的指令数据集,实现了低资源领域学术助手构建的民主化。这些工作共同验证了结构化元数据在优化大语言模型领域专业能力方面的巨大潜力。
数据集最近研究
最新研究方向
当前,该数据集的前沿研究方向主要聚焦于基于指令微调(SFT)与参数高效微调(LoRA、PeFT)技术,构建面向高校科研文献的智能问答与信息检索系统。通过将22,809篇Scopus索引论文转化为933,010条结构化指令-回复对,覆盖作者、引用、时间、期刊等45类查询类型,显著提升了学术大语言模型对出版元数据的精准提取与多维度推理能力。该数据集的诞生象征着科研资产管理从简单统计向交互式知识服务的跃迁,为自动化研究助手、文献发现工具及跨机构学术影响力评估提供了关键训练基座,有望重塑学术搜索的人机交互范式。
以上内容由遇见数据集搜集并总结生成


