recordabebe/tenacious_bench_v0_1
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/recordabebe/tenacious_bench_v0_1
下载链接
链接失效反馈官方服务:
资源简介:
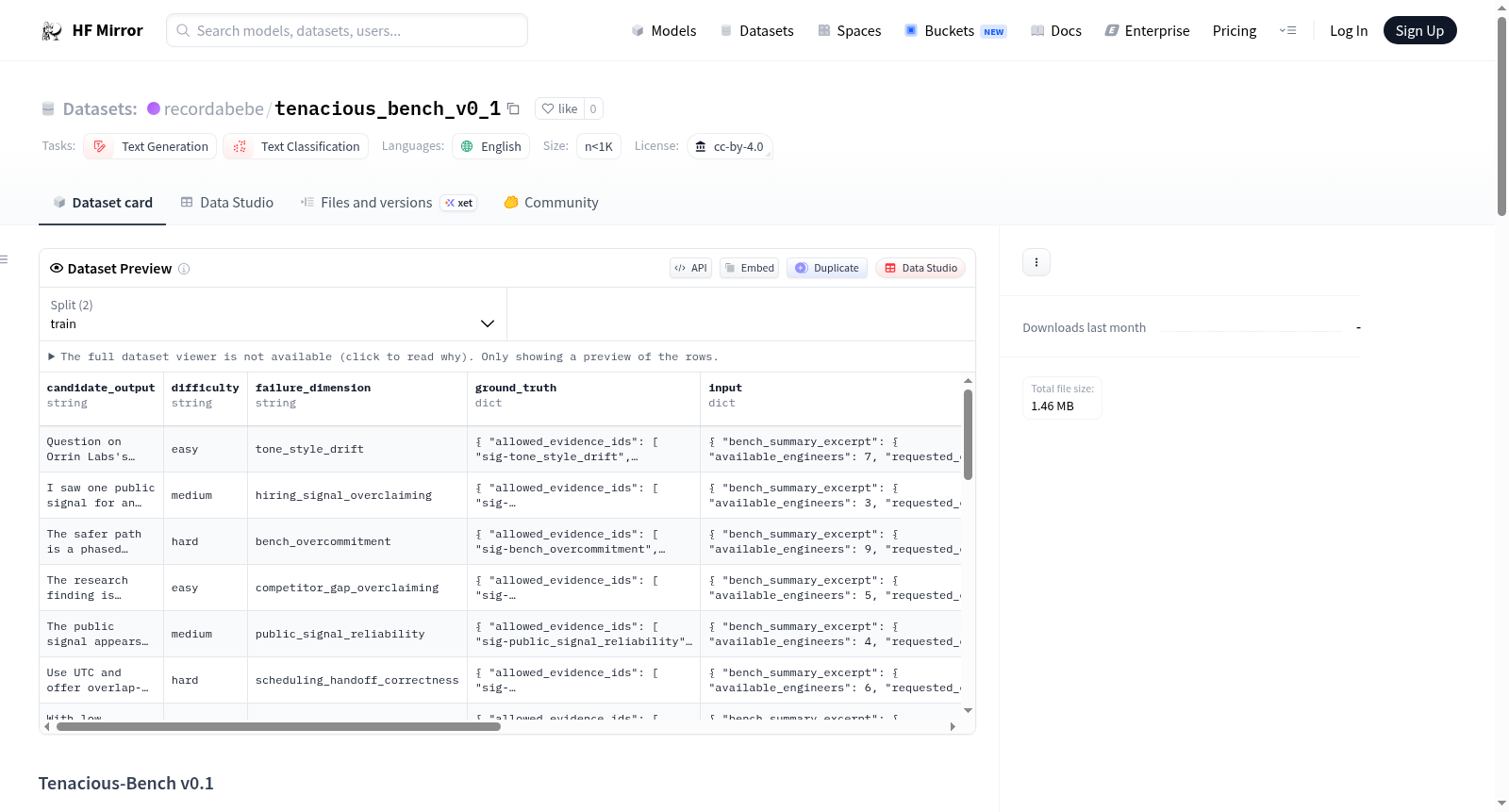
Tenacious-Bench v0.1是一个用于评估B2B销售代理可靠性的基准测试数据集,专注于通用销售或代理基准测试经常忽略的特定领域故障模式,如语调漂移、招聘信号过度宣称、工作台过度承诺、竞争对手差距过度宣称、公共信号可靠性、调度交接正确性和ICP错误分类等。数据集包含训练集(105个任务)和开发集(63个任务),来源于跟踪和运行时工件、探测库扩展、确定性程序化任务生成和手工编写的对抗性任务。数据集文件包括任务文件、示例文件和污染检查文件等,并提供了本地重建、评分、污染检查和快速开始的指南。
Tenacious-Bench v0.1 is a benchmark for Tenacious-style B2B sales-agent reliability. It focuses on domain-specific failure modes that generic sales or agent benchmarks often miss: tone drift, hiring-signal over-claiming, bench over-commitment, competitor-gap over-claiming, public-signal reliability, scheduling handoff correctness, and ICP misclassification. The dataset includes a training set (105 tasks) and a development set (63 tasks), derived from week 10 traces and runtime artifacts, probe-library expansions, deterministic programmatic task generation, and hand-authored adversarial tasks. The dataset files include task files, example files, and contamination check files, and provides guidelines for local rebuilding, scoring, contamination checking, and quick start.
提供机构:
recordabebe
搜集汇总
数据集介绍
构建方式
Tenacious-Bench v0.1是一个专为评估B2B销售代理可靠性而设计的基准数据集,其构建方式融合了多种数据来源与生成策略。数据源自销售流程的第十周运行时追踪与运行时产物,经过探针库扩展后,结合确定性程序化任务生成与人工编写的对抗性任务,形成了多样化的测试场景。在源模式混合上,约30%来自真实轨迹衍生,30%来自程序化生成,25%基于多大语言模型合成,15%为人工编写的对抗性样本,确保了数据集在覆盖实际业务场景的同时兼具对抗性与挑战性。
特点
该数据集的核心特色在于聚焦B2B销售代理特有的故障维度,如语气漂移、招聘信号过度宣称、竞品差距夸大、公共信号可靠性、日程交接正确性及理想客户画像误分类等,这些是通用销售或代理基准测试往往忽略的领域专属失效模式。数据集包含训练集105个任务、开发集63个任务,以及一个42个任务的保密留出集用于最终评估,规模虽小但任务针对性极强,且附带详细的附带文档如数据表、方法论与审计备忘录,增强了透明度与可复现性。
使用方法
使用者可通过Python读取JSONL格式的任务文件快速上手,每个任务包含任务ID、分区、难度、失效维度、输入、候选输出、真实答案及评分细则等字段。本地评估时,可运行内置的评分评估器脚本对开发集进行评分,并利用污染检测脚本检查数据泄露问题。若需完全重建数据集,可通过提供的生成脚本在本地执行构建,便于研究者深入理解数据生成流程或进行定制化扩展。
背景与挑战
背景概述
Tenacious-Bench v0.1是一个专注于B2B销售代理可靠性的基准测试数据集,由相关研究团队于近期创建并基于CC-BY-4.0许可发布。该数据集旨在评估和提升销售代理在特定领域内的表现,其核心研究问题在于识别和量化通用销售或代理基准测试中常被忽视的故障模式,包括语气漂移、招聘信号过度声明、基准过度承诺、竞争对手差距夸大、公共信号可靠性、日程交接正确性以及ICP分类错误。通过整合第10周迹线、探针库扩展、确定性程序化任务生成及人工编写的对抗性任务,该数据集为销售代理可靠性的系统评估提供了重要工具,对推动B2B销售自动化领域的评估标准化具有显著影响力。
当前挑战
Tenacious-Bench v0.1面临的挑战主要体现在两个方面。在领域问题层面,它需解决B2B销售代理在实际部署中遭遇的细微且领域特定的可靠性故障,这些故障难以被通用基准所捕捉,例如代理在对话中发生语气偏移或对招聘信号过度声称,导致客户信任缺失与商业机会流失。在构建过程中,挑战涵盖从仅168个公共任务的小规模样本中提取代表性故障模式,并确保约30%迹线衍生任务、30%程序化任务、25%多LLM合成任务及15%手工编写对抗任务之间的平衡与覆盖,同时还需严格隔离42个私有任务的评估集以维护基准的无污染性。
常用场景
经典使用场景
在B2B销售智能体可靠性评估领域,Tenacious-Bench v0.1作为一款专项基准测试集,主要用于检测和量化销售智能体在特定业务故障维度的表现。该数据集覆盖了语调漂移、招聘信号过度宣称、基准承诺过度、竞争对手差距过度宣称、公开信号可靠性、调度交接正确性及ICP误分类等七个核心失效模式。研究者可基于该数据集的168个公开任务(含105个训练样本与63个开发样本),通过对比候选输出与真实标注,系统评估智能体在复杂销售场景中的指令遵循能力、事实一致性及多轮对话鲁棒性。
实际应用
在实际商业部署中,该数据集为销售自动化系统的质量保障提供了关键测试依据。企业可将其嵌入持续集成流程,用于检测和修复B2B销售智能体在客户交互中可能出现的各类语境敏感错误。例如,通过调度交接维度的测试,确保智能体在不同业务系统间进行客户线索传递时的信息完整性与准确性;通过ICP误分类检测,防范智能体将非目标客户错误归类为优质线索。该基准已成为多家SaaS企业评估销售AI代理稳定性的重要参考工具。
衍生相关工作
该数据集的发布催生了一系列围绕销售智能体可靠性的后续研究工作。部分团队基于其证据图谱文件(evidence_graph.json)开发了归因推理模型,用于追踪错误输出与输入信号之间的因果关系;另一工作则利用数据集中的对抗性任务样本,改进模型对‘过度宣称’类错误的抵抗能力。此外,数据集附带的审计备忘录和污染检查脚本,推动了销售AI领域在基准测试透明化和数据质量控制方面的标准化实践,为后续同类基准的构建提供了方法论范式。
以上内容由遇见数据集搜集并总结生成


