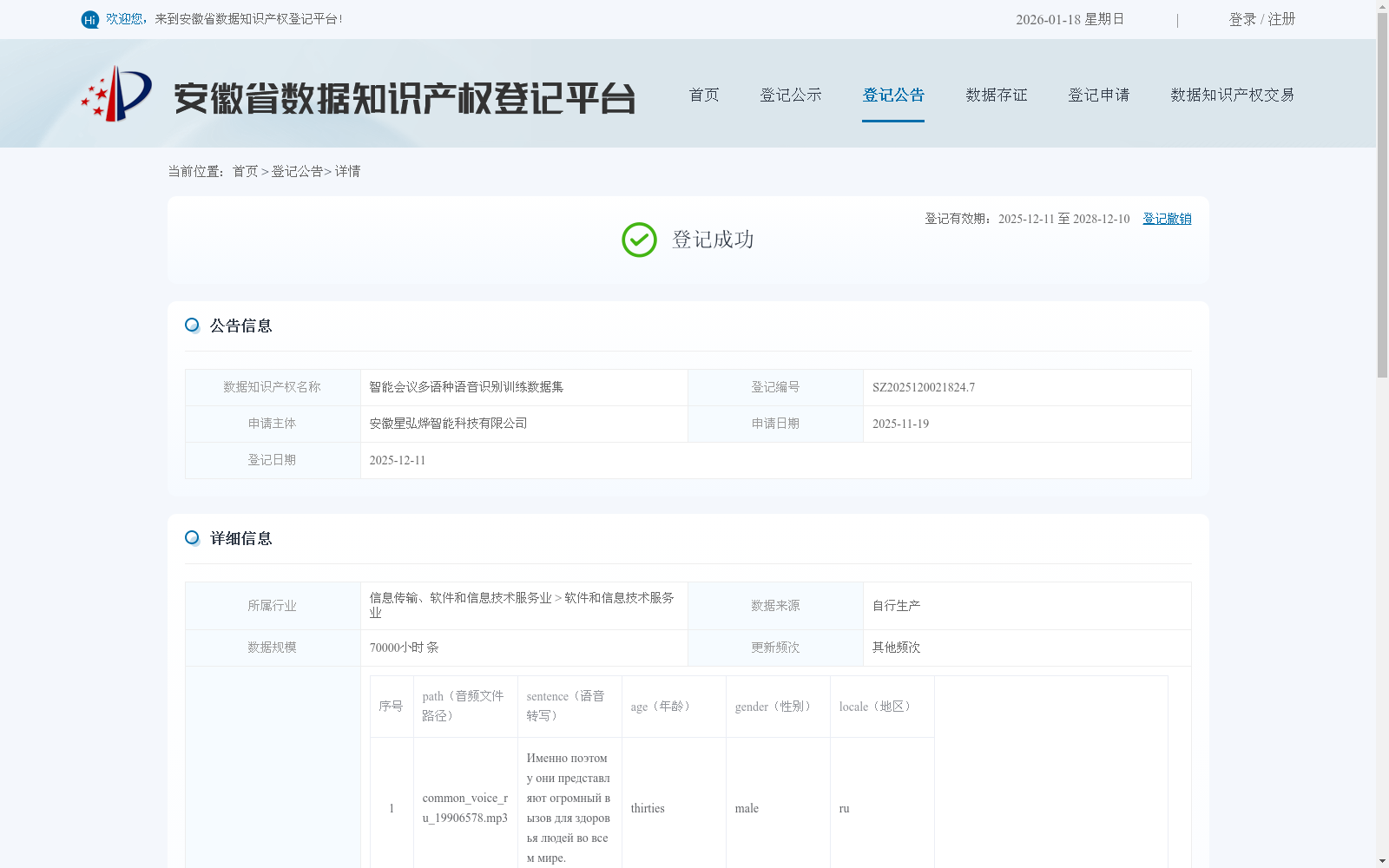
智能会议多语种语音识别训练数据集
收藏安徽省数据知识产权登记平台2025-11-19 更新2025-12-16 收录
下载链接:
http://58.56.66.75:14401/#/registerAnnouncementDetail?id=433d30f3-3c3c-4b19-a844-c1a7c82b2084&state=2
下载链接
链接失效反馈官方服务:
资源简介:
由安徽星弘烨智能科技有限公司自建系统采集的原始语音数据加工而来。
提供机构:
安徽星弘烨智能科技有限公司
创建时间:
2025-11-19
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个专为智能会议场景设计的大规模多语种语音识别训练资源,总规模达70000小时,包含多种语言的音频样本及对应的转写文本,并附带年龄、性别和地区等元数据。它主要用于训练高精度语音识别模型,以解决跨语言会议中的沟通障碍,实现会议内容的实时转写和结构化处理,从而提升企业会议效率和智能化水平。数据集的处理流程涵盖音频预处理、端到端模型推理和文本解码等步骤,确保输出流畅的文本记录。
以上内容由遇见数据集搜集并总结生成


