f1_corner_telemetry_2024_2025
收藏Hugging Face2026-02-09 更新2026-02-10 收录
下载链接:
https://huggingface.co/datasets/FlorindoDev/f1_corner_telemetry_2024_2025
下载链接
链接失效反馈官方服务:
资源简介:
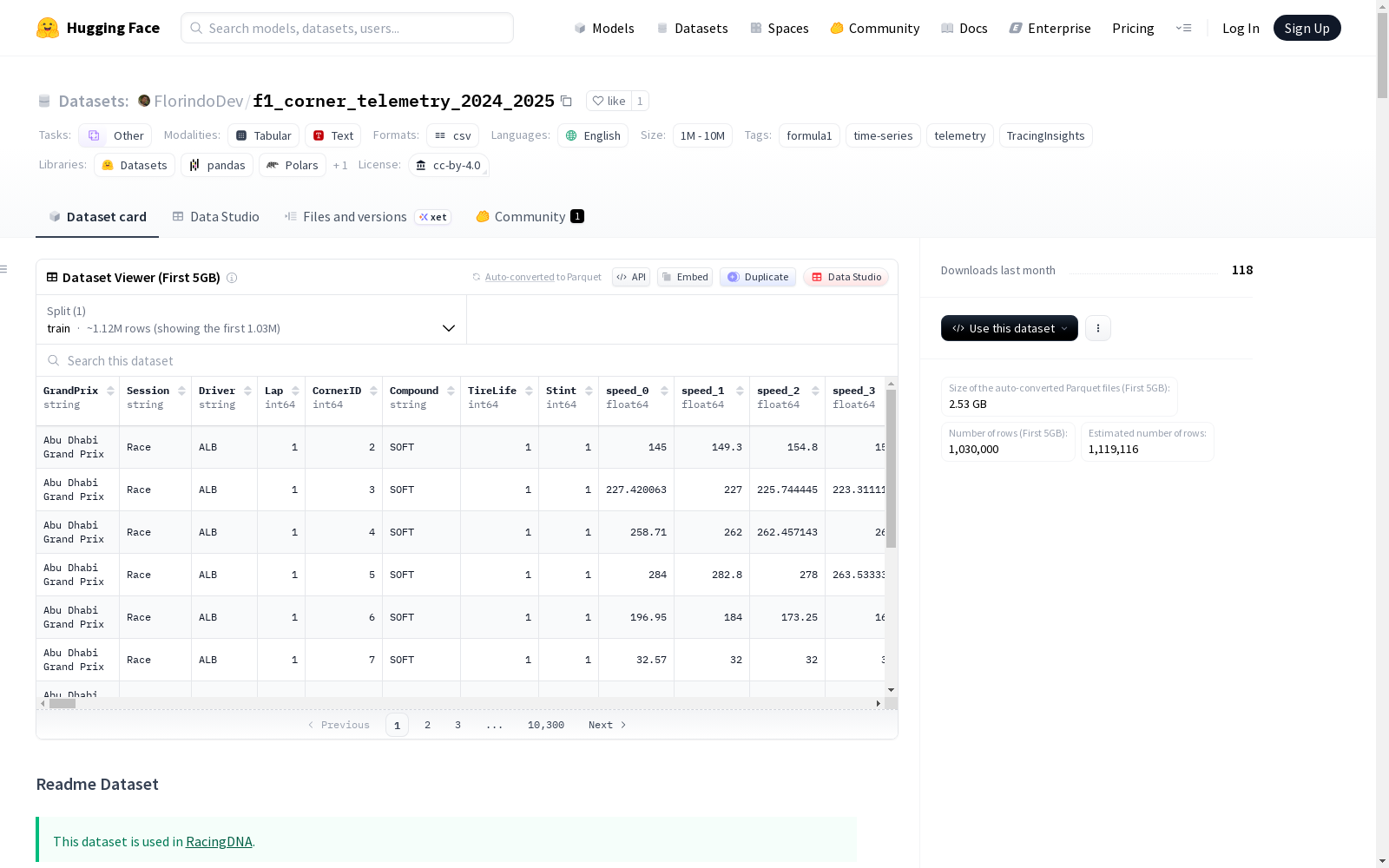
F1 Telemetry Curves 2024-2025 数据集包含了2024至2025赛季Formula 1比赛和排位赛中的遥测数据。数据集以CSV格式存储,每一行代表车手在特定圈数中通过的一个弯道。数据集包含以下内容:
1. **元数据列**:用于标识赛事和弯道的信息,包括大奖赛名称、赛事阶段(如Race或Qualifying)、车手代码、圈数、弯道ID、轮胎配方、轮胎寿命和赛段编号。
2. **遥测数据列**:包含在弯道内采样的时间序列数据,每个特征有50个时间点采样(索引0至49)。特征包括速度、发动机转速、油门百分比、刹车百分比、三轴加速度、空间坐标、行驶距离和圈时。
3. **数据填充**:为确保每个弯道数据固定为50个点,不足部分用-1000.0填充。
数据集经过标准化处理,采用Z-Score方法,并特别处理了分类变量(如轮胎配方)的编码。数据提取过程通过四个主要阶段确保弯道数据的准确性和一致性,包括空间窗口定义、物理检测、顶点验证和切割居中。
该数据集适用于时间序列分析、驾驶行为研究和机器学习模型训练等任务。
创建时间:
2026-02-08
搜集汇总
数据集介绍
构建方式
在赛车运动数据科学领域,构建高保真度的赛道弯道数据集是分析车手行为与车辆性能的关键。本数据集通过一套严谨的算法流程,从连续的原始遥测流中提取出独立的弯道片段。其核心逻辑首先依据已知弯道的空间边界框定义搜索窗口,随后基于侧向加速度的阈值检测弯道的物理起止点,并强制要求检测到的片段必须包含几何顶点以确保数据相关性。最终,每个弯道片段被裁剪并中心化至顶点前后最多25个采样点,形成最多50个时间点的标准化序列,不足部分以特定填充值补足,从而为后续建模提供了结构一致的输入。
特点
该数据集在赛车工程分析中展现出鲜明的结构化特征。每条记录代表一个特定弯道,并附有丰富的元数据,包括大奖赛、车手、圈数及轮胎信息等。其核心在于包含了时间序列的遥测数据,涵盖速度、转速、油门刹车百分比、三轴加速度及空间坐标等十多个物理量,每个量均在50个时间点上均匀采样。为确保序列长度统一,数据集采用了填充机制,并以负一千作为填充标识。此外,数据已完成了基于特征分组的全局Z-Score标准化,并对轮胎配方进行了独热编码,同时妥善处理了填充值,生成了便于神经网络直接使用的归一化矩阵与掩码矩阵。
使用方法
对于从事赛车性能建模或车手风格分析的研究者而言,该数据集提供了即用型的分析基础。预处理后的数据以CSV和NPZ格式存储,用户可直接加载归一化后的矩阵进行模型训练。数据集中的掩码矩阵能够有效区分真实数据点与填充区域,适用于支持掩码机制的深度学习架构。若需还原原始物理量,可利用随附的均值和标准差向量进行反标准化。该数据集专为RacingDNA等项目设计,适用于时间序列预测、异常检测或驾驶策略聚类等任务,为深入探索Formula 1赛场上的微观动力学提供了高质量、标准化的数据资源。
背景与挑战
背景概述
在赛车运动工程与数据分析领域,高精度遥测数据的系统化采集与解析对于理解车辆动力学与车手行为至关重要。F1 Corner Telemetry 2024-2025数据集由TracingInsights机构于2024至2025年间创建,旨在通过结构化方法提取一级方程式赛车在弯道中的多维度时间序列数据。该数据集聚焦于将连续遥测流分割为独立的弯道片段,涵盖速度、转速、油门刹车百分比、三轴加速度及空间坐标等丰富特征,为核心研究问题——即车手在特定弯道中的操控模式识别与性能优化——提供了标准化基准。其规范化处理与统一表征形式,显著推动了赛车策略分析、人工智能驱动驾驶模型及实时性能预测等相关领域的研究进展。
当前挑战
该数据集致力于解决赛车遥测分析中弯道行为细粒度建模的挑战,其核心在于从高噪声、高维度的连续数据流中准确分割并表征每个弯道的物理过程。构建过程中的主要挑战包括:弯道起止点的鲁棒检测需克服传感器噪声与赛道特定扰动,算法通过空间窗口约束与基于横向加速度的滞后阈值设计以提升识别精度;为满足神经网络输入要求,数据需进行长度标准化,采用以弯心为中心的固定窗口裁剪与特定填充值处理,但可能损失部分长弯道的完整动力学信息;此外,多源异构特征(如连续数值变量与轮胎配方分类变量)的协同归一化与编码,需在保留物理意义的同时确保数据一致性,增加了预处理流程的复杂性。
常用场景
经典使用场景
在赛车运动分析领域,该数据集为研究车手过弯行为提供了标准化的时间序列数据。其经典使用场景集中于利用机器学习模型,如循环神经网络或时间卷积网络,对车手在特定弯角的表现进行模式识别与分类。通过整合速度、转速、油门刹车百分比以及三轴加速度等多元时序特征,研究者能够构建模型以区分不同车手的驾驶风格,或评估同一车手在不同轮胎配方与损耗状态下的过弯策略差异。数据集的归一化处理与固定长度采样确保了模型输入的稳定性,为后续的深度学习应用奠定了坚实基础。
实际应用
该数据集的实际应用场景紧密围绕一级方程式赛车及相关竞技运动的性能优化与策略制定。车队工程师可利用其分析车手在比赛或排位赛中的过弯数据,识别时间损失环节,并为车手提供具体的驾驶改进建议。在模拟训练中,该数据集可用于构建高保真的驾驶模拟器,帮助车手提前熟悉赛道特性。同时,媒体与赛事分析机构能够基于这些数据制作深度技术解读内容,提升观众观赛体验。数据集的衍生项目RacingDNA也展示了其在构建赛车人工智能代理方面的直接应用潜力。
衍生相关工作
围绕该数据集,已衍生出多个具有代表性的研究工作。其直接关联项目RacingDNA旨在利用此类时序数据训练能够理解并模拟赛车行为的智能体。在更广泛的学术范畴内,该数据集的结构启发了针对时序动作分割与模式识别的新型算法设计,特别是在处理带有空间约束与物理阈值的复杂事件检测方面。此外,其数据归一化与填充处理策略也为其他运动科学或工业时序数据分析提供了参考范式,促进了时间序列数据标准化预处理方法的发展。
以上内容由遇见数据集搜集并总结生成


