protein_secondary_structure_from_PDB
收藏Hugging Face2024-07-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/lamm-mit/protein_secondary_structure_from_PDB
下载链接
链接失效反馈官方服务:
资源简介:
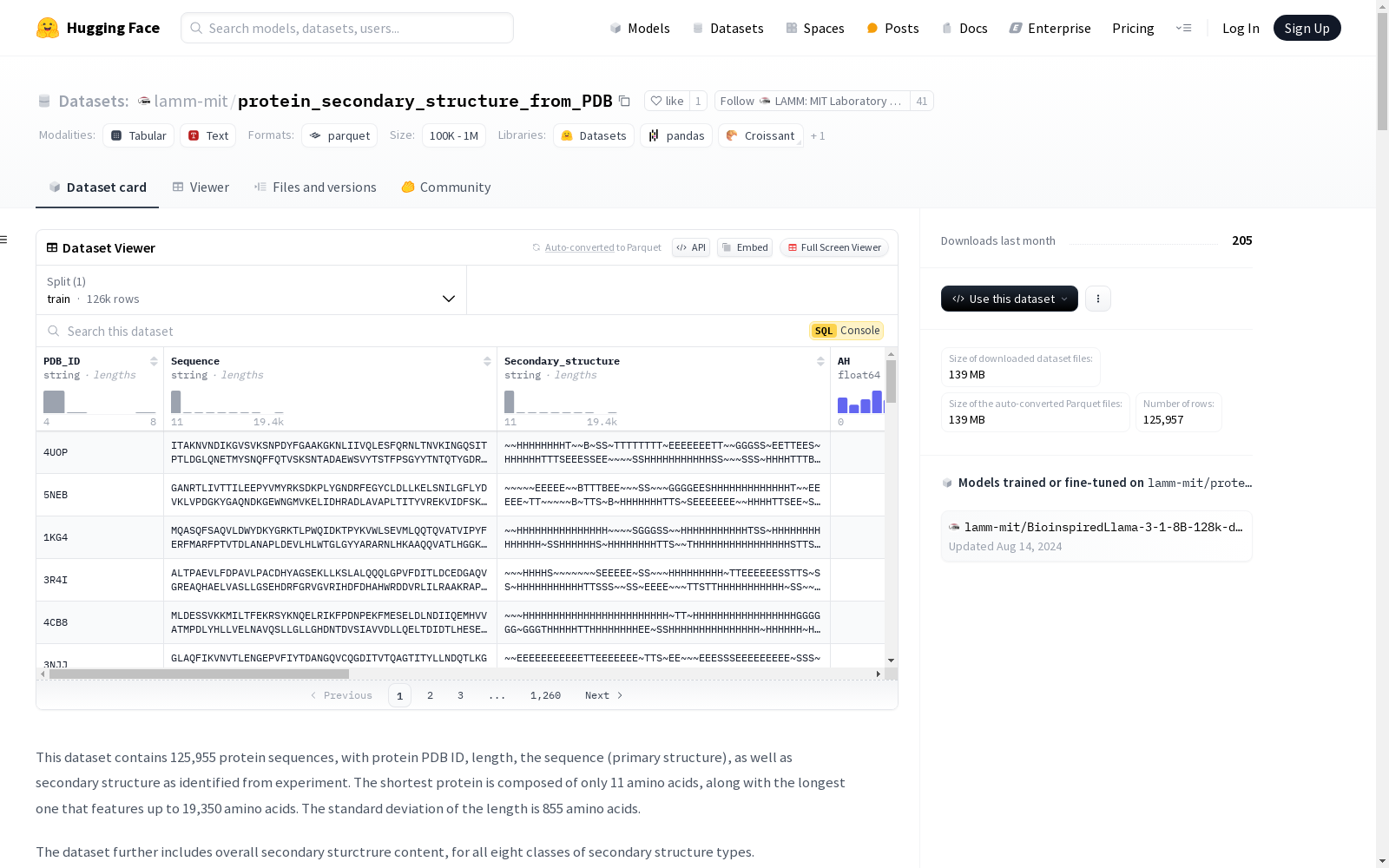
该数据集包含125,955个蛋白质序列,每个序列包含蛋白质的PDB ID、长度、序列(初级结构)以及通过实验识别的二级结构。数据集还包括八类二级结构的总体含量,以及每个序列的初级和次级二级结构类型。数据集用于训练模型,以基于序列预测蛋白质的二级结构含量。此外,数据集还展示了蛋白质设计示例,展示了点突变对α-螺旋和β-折叠含量的系统性影响。
This dataset comprises 125,955 protein sequences. Each entry includes the protein's PDB ID, sequence length, primary structure (amino acid sequence), and experimentally determined secondary structure. Furthermore, the dataset provides the overall content of eight classes of secondary structures, as well as the primary and secondary structure types for each sequence. This dataset is developed for training models to predict protein secondary structure content based on their amino acid sequences. Additionally, the dataset includes protein design examples that demonstrate the systematic effects of point mutations on the contents of α-helices and β-sheets.
提供机构:
LAMM: MIT Laboratory for Atomistic and Molecular Mechanics
创建时间:
2024-07-27
原始信息汇总
数据集概述
数据集信息
特征
- PDB_ID: 字符串类型
- Sequence: 字符串类型
- Secondary_structure: 字符串类型
- AH: 浮点数类型
- BS: 浮点数类型
- T: 浮点数类型
- UNSTRUCTURED: 浮点数类型
- BETABRIDGE: 浮点数类型
- 310HELIX: 浮点数类型
- PIHELIX: 浮点数类型
- BEND: 浮点数类型
- Sequence_length: 整数类型
- Sequence_spaced: 字符串类型
- Primary_SS_Type: 字符串类型
- Secondary_SS_Type: 字符串类型
数据分割
- train: 包含125957个样本,占用338419581字节
数据大小
- 下载大小: 139433982字节
- 数据集大小: 338419581字节
数据集描述
概述
- 包含125,955个蛋白质序列,包括蛋白质PDB ID、长度、序列(一级结构)以及实验识别的二级结构。
- 最短的蛋白质由11个氨基酸组成,最长的蛋白质包含19,350个氨基酸。
- 长度标准差为855个氨基酸。
二级结构内容
- 大多数序列的β片层含量低于30%,约20,000个序列的β片层含量低于10%。
- α螺旋比β片层比例通常更高。
- 大多数序列的α螺旋含量在30%到50%之间,但有一小部分序列的α螺旋含量超过80%。
- 数据集中有大量序列的α螺旋和β片层比例低于5%。
数据集统计
- 提供了长度分布和二级结构内容分布的图表。
- 包含主要和次要二级结构类型的分布图表。
蛋白质二级结构预测结果
- 该数据集用于训练模型,预测基于序列的蛋白质二级结构内容。
蛋白质设计示例
- 展示了系统性点突变对α螺旋和β片层含量的影响。
引用
bibtex @article{YuBuehler2022, title={End-to-End Deep Learning Model to Predict and Design Secondary Structure Content of Structural Proteins}, author={Chi-Hua Yu and Wei Chen and Yu-Hsuan Chiang and Kai Guo and Zaira Martin Moldes and David L Kaplan and Markus J Buehler}, journal={ACS Biomaterials Science & Engineering}, volume={8}, number={3}, pages={1156-1165}, year={2022}, month={Mar}, doi={10.1021/acsbiomaterials.1c01343}, pmid={35129957}, pmcid={PMC9347213} }
搜集汇总
数据集介绍
构建方式
该数据集基于蛋白质数据库(PDB)中的实验数据构建,涵盖了125,955条蛋白质序列。每条记录包含蛋白质的PDB ID、序列长度、一级结构(氨基酸序列)以及通过实验确定的二级结构信息。数据集的构建过程中,通过提取PDB中的结构信息,进一步计算了八种二级结构类型的含量,并生成了相关的统计特征。数据集的多样性和广泛性使其成为研究蛋白质结构与功能关系的宝贵资源。
特点
该数据集的特点在于其丰富的蛋白质二级结构信息,涵盖了从11个氨基酸到19,350个氨基酸的广泛长度范围。数据集中包含了八种二级结构类型的含量分布,其中α螺旋和β折叠的含量分布尤为显著。大多数序列的α螺旋含量介于30%至50%之间,而β折叠含量通常低于30%。此外,数据集中还包含了许多低α螺旋和β折叠含量的序列,为研究蛋白质结构的多样性提供了重要参考。
使用方法
该数据集可用于蛋白质二级结构预测模型的训练与验证。通过输入蛋白质的一级结构序列,模型可以预测其二级结构的含量分布。此外,数据集还可用于蛋白质设计研究,通过系统性地改变氨基酸序列,分析其对二级结构的影响。数据集中提供的统计特征和分布图可用于进一步分析蛋白质结构与功能之间的关系,为生物信息学和结构生物学研究提供支持。
背景与挑战
背景概述
蛋白质二级结构预测是生物信息学领域的重要研究方向,旨在通过蛋白质序列推断其二级结构。protein_secondary_structure_from_PDB数据集由Chi-Hua Yu、Markus J. Buehler等研究人员于2022年创建,收录了125,955条蛋白质序列及其二级结构信息。该数据集基于蛋白质数据库(PDB)的实验数据,涵盖了从11到19,350个氨基酸长度的蛋白质序列,并提供了八种二级结构类型的含量信息。该数据集为研究蛋白质序列与二级结构之间的关系提供了丰富的数据支持,推动了深度学习在蛋白质结构预测中的应用,相关成果发表于《ACS Biomaterials Science & Engineering》。
当前挑战
该数据集的核心挑战在于解决蛋白质二级结构预测的复杂性问题。蛋白质序列与二级结构之间的关系高度非线性,且受多种因素影响,如氨基酸序列的局部环境、氢键网络等。此外,数据集中蛋白质长度差异显著,最短仅11个氨基酸,最长可达19,350个氨基酸,这为模型的训练和泛化能力提出了更高要求。在数据集构建过程中,如何从实验数据中准确提取二级结构信息,并确保数据的多样性和代表性,也是一个重要挑战。尽管数据规模庞大,但某些二级结构类型(如β-折叠)在序列中占比偏低,可能导致模型对这些结构的预测能力不足。
常用场景
经典使用场景
在蛋白质结构预测领域,protein_secondary_structure_from_PDB数据集被广泛用于训练和验证深度学习模型,以从蛋白质序列中预测其二级结构。通过分析大量蛋白质序列及其对应的二级结构,研究者能够探索序列与结构之间的复杂关系,进而提升预测模型的准确性。
解决学术问题
该数据集解决了蛋白质二级结构预测中的关键问题,尤其是如何从一级序列推断出二级结构的分布。通过提供丰富的实验数据,研究者能够更深入地理解氨基酸序列如何影响蛋白质的折叠模式,从而推动蛋白质结构预测领域的发展。
衍生相关工作
基于该数据集,研究者开发了多种深度学习模型,如Yu和Buehler等人提出的端到端预测模型。这些模型不仅能够准确预测蛋白质的二级结构,还为蛋白质设计提供了新的工具和方法,推动了蛋白质结构预测与设计领域的交叉研究。
以上内容由遇见数据集搜集并总结生成


