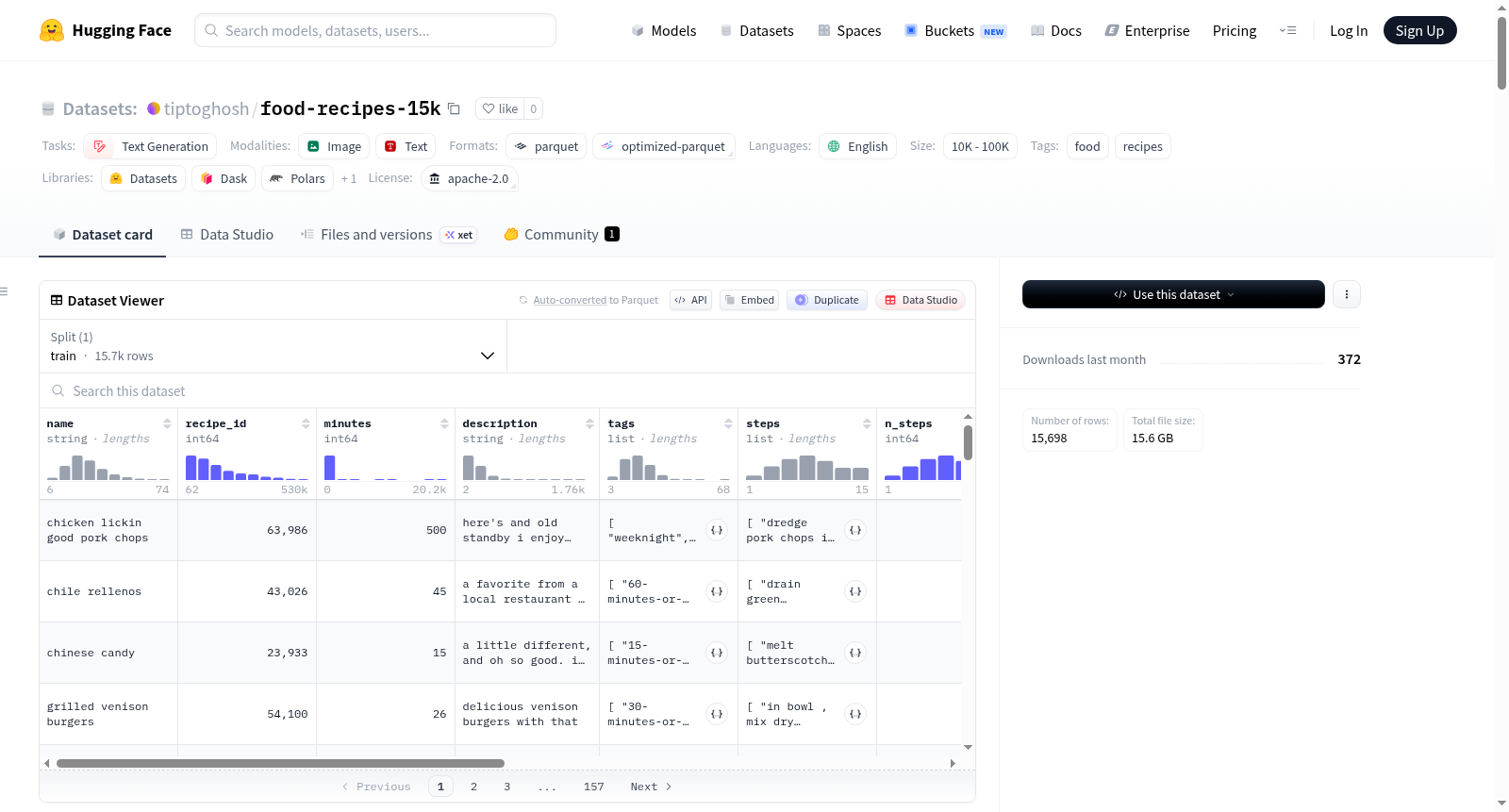
food-recipes-15k
收藏Hugging Face2026-04-23 更新2026-04-24 收录
下载链接:
https://huggingface.co/datasets/tiptoghosh/food-recipes-15k
下载链接
链接失效反馈官方服务:
资源简介:
Food.com多模态食谱数据集(15K)是一个精心策划的高质量多模态数据集,专为训练和评估视觉语言模型(VLMs)及多模态检索增强生成(RAG)系统而设计。数据集包含约15,000个样本,每个样本由渲染的食谱卡片图像(PNG格式,300 DPI)和结构化Markdown文本组成。数据来源于Food.com Recipes and User Interactions Kaggle数据集,经过六阶段处理流程,包括数据加载、交互信号聚合、过滤与采样、评论文本清洗、Markdown文本模态生成和食谱卡片图像模态生成。数据集适用于多模态RAG、VLM微调、跨模态检索和文档布局理解等任务。每个样本包含食谱名称、ID、烹饪时间、描述、标签、步骤、成分、营养信息和用户评分等字段。数据集还提供了详细的营养值说明和质量总结,推荐使用`nvidia/llama-nemotron-embed-vl-1b-v2`模型进行嵌入。
创建时间:
2026-04-22
原始信息汇总
数据集概述:Food Recipes 15k
基本信息
- 数据集名称:Food Recipes 15k
- 许可证:Apache-2.0
- 任务类别:文本生成
- 语言:英语
- 标签:食物、食谱
- 样本数量:约15,000个
- 模态:每个样本包含2种模态——PNG格式的食谱卡片图像(300 DPI,A4比例)和结构化Markdown文本
数据来源
- 原始数据集:Food.com Recipes and User Interactions(Kaggle)
- 原始食谱池:约231,637条食谱
- 输入文件:
RAW_recipes.csv:食谱元数据、成分、步骤、营养、标签(约231,637行)RAW_interactions.csv:用户评分和自由文本评论(数十万行)
数据集构建流程
- 数据加载与探索性分析:使用pandas加载原始CSV文件,进行缺失值、重复项和分布分析,丢弃所有包含空值的行。
- 交互信号聚合:按食谱聚合用户交互数据,计算平均评分、收集评论文本、统计用户评分数量,并与食谱数据合并。
- 过滤与采样:按评分降序排序,应用以下过滤条件:
- 成分数量 ≤ 15
- 步骤数量 ≤ 15
- 用户评分数量 > 10
- 去除剩余空值行
- 过滤后得到约15,700条食谱,最终生成约15,000个样本
- 评论文本清洗:对原始评论进行HTML实体解码、去除非ASCII字符、压缩空白和换行、过滤短字符串(少于5个字符),每个食谱保留最多5条评论用于Markdown文本,最多10条用于食谱卡片图像。
- Markdown文本模态生成:将每条食谱序列化为结构化Markdown字符串,包含标题、ID、烹饪时间、评分、描述、成分列表、步骤、营养摘要和用户评论。
- 食谱卡片图像模态生成:使用自定义Python管线将每个食谱渲染为单页A4 PDF,再转换为300 DPI的PNG图像。图像通过10种配色方案和4种图表类型组合,实现视觉多样性(共40种基础样式)。若卡片超出一页,自动减少评论数量或缩放字体。最终排除12个渲染失败的食谱和磁盘上缺失的图像。
数据集模式(Schema)
| 列名 | 类型 | 描述 |
|---|---|---|
name |
string | 食谱名称(标题大小写) |
recipe_id |
int64 | 唯一食谱标识符 |
minutes |
int64 | 总准备和烹饪时间(分钟) |
description |
string | 食谱描述文本 |
tags |
list[string] | 描述性标签(每张卡片最多8个) |
steps |
list[string] | 有序准备步骤(编号、句首大写) |
n_steps |
int64 | 准备步骤数量(≤ 15) |
ingredients |
list[string] | 成分字符串列表 |
n_ingredients |
int64 | 成分数量(≤ 15) |
nutrition |
struct | 营养值结构,包含浮点数字段 |
nutrition.calories |
float32 | 能量(千卡) |
nutrition.total_fat_pdv |
float32 | 总脂肪(%每日值) |
nutrition.sugar_pdv |
float32 | 糖(%每日值) |
nutrition.sodium_pdv |
float32 | 钠(%每日值) |
nutrition.protein_pdv |
float32 | 蛋白质(%每日值) |
nutrition.saturated_fat_pdv |
float32 | 饱和脂肪(%每日值) |
nutrition.carbs_pdv |
float32 | 总碳水化合物(%每日值) |
rating |
float32 | 所有评论者的平均星级评分(1.0–5.0) |
num_ratings |
float32 | 用户评分总数(所有样本 > 10) |
markdown |
string | 完整结构化Markdown食谱(文本模态) |
image |
Image | 渲染的食谱卡片PNG(300 DPI)(图像模态) |
营养值说明
营养值直接来自原始Food.com数据集,除卡路里(千卡)外,均以每日值百分比(PDV) 表示,基于2,000卡路里参考饮食。
数据质量摘要
| 指标 | 值 |
|---|---|
| 原始食谱池 | ~231,637 |
| 质量过滤后(步骤≤15、成分≤15、评分>10) | ~15,700 |
| 排除——图像渲染失败 | 12 |
| 排除——磁盘上缺失图像 | 因情况而异 |
| 最终数据集大小 | ~15,000个样本 |
| 每样本模态 | 2(PNG图像 + Markdown文本) |
| 每食谱最低评分 | > 10 |
| 图像分辨率 | 300 DPI(A4) |
推荐嵌入模型
该数据集设计用于nvidia/llama-nemotron-embed-vl-1b-v2,一个10亿参数的视觉-语言嵌入模型,可从图像和文本输入生成2048维向量。
预期用途
- 多模态检索增强生成(RAG):使用视觉-语言嵌入模型进行基于视觉和文本的食谱检索
- 视觉-语言模型(VLM)微调:结构化文档理解、成分提取和营养推理
- 跨模态检索:基于成分、营养和图像的食谱搜索
- 文档布局理解:食谱卡片遵循一致但视觉多样的模板(10种配色方案和4种图表样式)
仓库结构
data/ ├── all csv files/ │ ├── RAW_recipes.txt │ ├── RAW_interactions.txt │ └── recipes_15k_samples.txt └── output/ └── images/ └── recipe_id_<ID>.png
依赖库
pandas、ast、re、html、reportlab、PyMuPDF (fitz)、Pillow (PIL)、numpy、datasets、tqdm
搜集汇总
数据集介绍
构建方式
Food Recipes 15k数据集的构建根植于Food.com平台的海量食谱与用户交互数据,历经一条严谨的六阶段流程。首先,原始CSV文件经由pandas加载,并实施质量审计与缺失值剔除。继而,对用户交互记录进行食谱级别的聚合,计算平均评分并汇总评论文本。在筛选与采样阶段,依据评分降序排列,并设置配料数、步骤数均不超过15及评论数超过10的严格阈值,最终从约23万条食谱中精选出约1.5万条高质量样本。随后,对评论文本进行HTML解码与噪声去除的清洗。最后,分别生成结构化的Markdown文本与精美的食谱卡片图像,其中图像通过定制PDF渲染管线以300 DPI分辨率输出为PNG格式。
使用方法
Food Recipes 15k数据集专为支持前沿的多模态研究而设计,其使用方法灵活多样。研究者可直接利用该数据集对视觉-语言模型进行微调,例如,通过食谱卡片图像与Markdown文本的配对训练,增强模型在结构化文档理解、食材识别与营养推理方面的能力。在检索层面,数据集可与如nvidia/llama-nemotron-embed-vl-1b-v2这样的视觉-语言嵌入模型相结合,构建多模态检索增强生成(RAG)系统,实现基于图像、食材或营养信息的跨模态食谱检索。此外,其高度一致且多样的卡片布局也为文档版面分析与理解研究提供了宝贵的基准资源。
背景与挑战
背景概述
Food-recipes-15k数据集由Tipto Ghosh于2025年创建,源自Food.com上约23万条原始食谱及用户交互数据,经过严格筛选与多模态重构而成。该数据集聚焦于视觉-语言模型(VLM)与多模态检索增强生成(RAG)系统的训练与评估,核心研究问题在于如何将结构化文本与视觉卡片图像有效对齐,以实现跨模态检索与文档理解。每个样本包含一张300 DPI的食谱卡片图像及其对应的Markdown文本,覆盖10种配色方案与4种图表样式,视觉多样性丰富。其发布为食谱领域的多模态研究提供了标准化的基准资源,推动了食品信息检索、营养推理及文档布局理解等前沿方向的发展。
当前挑战
该数据集面对的挑战主要包括领域难题与构建困境两方面。在领域层面,食谱文本与图像间存在语义鸿沟,如何使模型精准跨模态关联成分列表、烹饪步骤与视觉布局成为技术瓶颈。构建过程中,从23万条原始数据中筛选出约1.5万条高质量样本需平衡评分、成分与步骤数量约束,且滤除缺失值后仍需处理12例渲染失败与磁盘缺失图像等异常。此外,营养值以每日百分比值表示而非绝对克数,增加了模型进行精确营养推理的复杂性,而多页面溢出自动缩放策略的实施则要求严格的质量控制,最终确保数据集的可复现性与一致性。
常用场景
经典使用场景
在视觉-语言模型(VLM)与多模态检索增强生成(RAG)系统的研究热潮中,food-recipes-15k数据集凭借其精心设计的成对食谱卡片图像与结构化Markdown文本,成为跨模态学习领域的标志性资源。该数据集最经典的使用场景聚焦于多模态检索任务,研究者可借助视觉-语言嵌入模型(如nvidia/llama-nemotron-embed-vl-1b-v2)对图像与文本进行联合编码,实现基于成分、营养信息或视觉风格的食谱互检索。同时,其标准化的文档布局与丰富的视觉变化体系(10种配色方案与4种图表样式)为文档结构理解与版面分析提供了理想实验平台,支持VLM在细粒度信息抽取(如成分识别、营养推理)与结构化输出生成等方向上的深度微调与评估。
解决学术问题
饮食计算领域的学术研究长期受到数据模态单一与质量参差的困扰,而food-recipes-15k数据集的问世有效弥合了这一鸿沟。该数据集系统性地解决了多模态食谱信息对齐中的两大核心难题:其一,通过严谨的过滤流水线(星级评分>10、成分与步骤数均≤15)从23万余原始配方中精选出约1.5万条高质量样本,排除了低信噪比数据对模型训练的干扰;其二,以成对图像-文本格式打破了传统纯文本食谱研究的模态壁垒,为跨模态表征学习、视觉问答与多模态推理提供了关键基准。其学术价值在于,不仅支持了食谱领域从单一文本理解向多模态联合推理的范式跃迁,更推动了多模态RAG系统在垂直场景中的验证与优化,为饮食推荐、营养分析与自动化食谱生成等研究分支注入了新的活力。
实际应用
在现实世界中,food-recipes-15k数据集的应用触角已延伸至饮食科技领域的多个前沿场景。智能厨电企业可借助其图像-文本配对数据训练视觉问答助手,用户仅需拍摄食材或菜品照片,系统便能精准识别并推荐匹配菜谱;数字健康平台则利用营养结构体字段(包含卡路里、脂肪、钠等七项指标)构建个性化的膳食管理引擎,结合用户评级历史实现营养均衡的食谱推荐。此外,该数据集驱动的多模态搜索引擎能够支持模糊查询,允许用户以“低热量高蛋白下午茶”等自然语言描述或上传图示进行食谱发现,显著提升了人机交互的直观性与效率。其内置的版式多样化设计(10种配色与4种图表样式)还使该数据集成为食品类文档自动化生成与智能排版技术的理想训练素材。
数据集最近研究
最新研究方向
该数据集聚焦于多模态食谱理解与检索的前沿探索,尤其在视觉-语言模型和检索增强生成系统领域掀起波澜。其核心创新在于将15,000份食谱同时呈现为高保真渲染的食谱卡片图像与结构化Markdown文本,为跨模态对齐研究提供了精良的试验田。当前,结合大型语言模型与图像嵌入的食谱推荐、营养推理及文档布局分析成为热点,该数据集恰好为训练能同时解析视觉元素与文本指令的模型奠定了基础。随着烹饪数字化与个性化饮食需求的攀升,这一资源正推动着从静态菜谱数据库向智能、可交互的多模态食谱助手的范式转变,其影响力已延伸至食品科技与健康计算等交叉学科。
以上内容由遇见数据集搜集并总结生成


