IndMedSTT-Synth
收藏Hugging Face2026-04-19 更新2026-04-20 收录
下载链接:
https://huggingface.co/datasets/osbornep8/IndMedSTT-Synth
下载链接
链接失效反馈官方服务:
资源简介:
IndMedSTT-Synth 是一个专注于印度多语言自动语音识别(ASR)转录中错误识别的药品品牌名称的数据集。该数据集旨在支持后ASR阶段的药品命名实体识别(NER)和ASR错误校正研究,特别是针对印度多语言和代码混合的患者语音。数据集包含87个样本,每个样本包括正确的印度药品品牌名称、药品处方背景、ASR输出的完整患者句子以及被错误替换的特定短语。数据通过GPT-4o模拟ASR自动校正行为生成,并经过人工审查和筛选。数据集适用于研究ASR错误校正、药品名称识别等任务,但存在仅使用单一LLM生成、每句仅提及单一药品、未包含通用药品名称和仅限英语等局限性。数据集采用CC BY 4.0许可证发布。
创建时间:
2026-04-05
原始信息汇总
IndMedSTT-Synth 数据集概述
数据集基本信息
- 数据集名称: IndMedSTT-Synth (v1.0)
- 许可证: CC BY 4.0
- 任务类别: 标记分类
- 语言: 英语(印度患者用语)
- 标签: 语音、自动语音识别、命名实体识别、医疗、医疗保健、语音转文本、生成式错误恢复
- 规模类别: 少于1K样本
- 样本数量: 87个样本
数据集简介
本数据集是IndMedSTT数据集集合的一部分,专注于印度多语言自动语音识别转录中被错误识别的药物品牌名称。当印度患者向医疗保健提供者或语音系统描述药物时,无论使用何种语言,他们通常使用英语品牌名称。多语言语音转文本模型在处理此类语音时,会将其语音学发音的品牌名称自动纠正为训练数据中最接近的英语单词,从而产生语法上合理但临床无意义的替换。
数据集详情
- 数据来源: 通过GPT-4o辅助生成,并由作者手动审查和整理。
- 药物名称来源: 从公开的印度药物数据库中抽样选取。
- 生成与审核过程: 通过提示GPT-4o模拟给定印度药物品牌名称的STT自动纠正行为,并生成包含误解短语的自然患者句子。所有生成的样本均经过人工审查;临床不可信、语言不真实或误解短语与上下文区分度不足的样本被修正或丢弃。大约12%的生成样本被丢弃,约30%的样本被大幅修订。
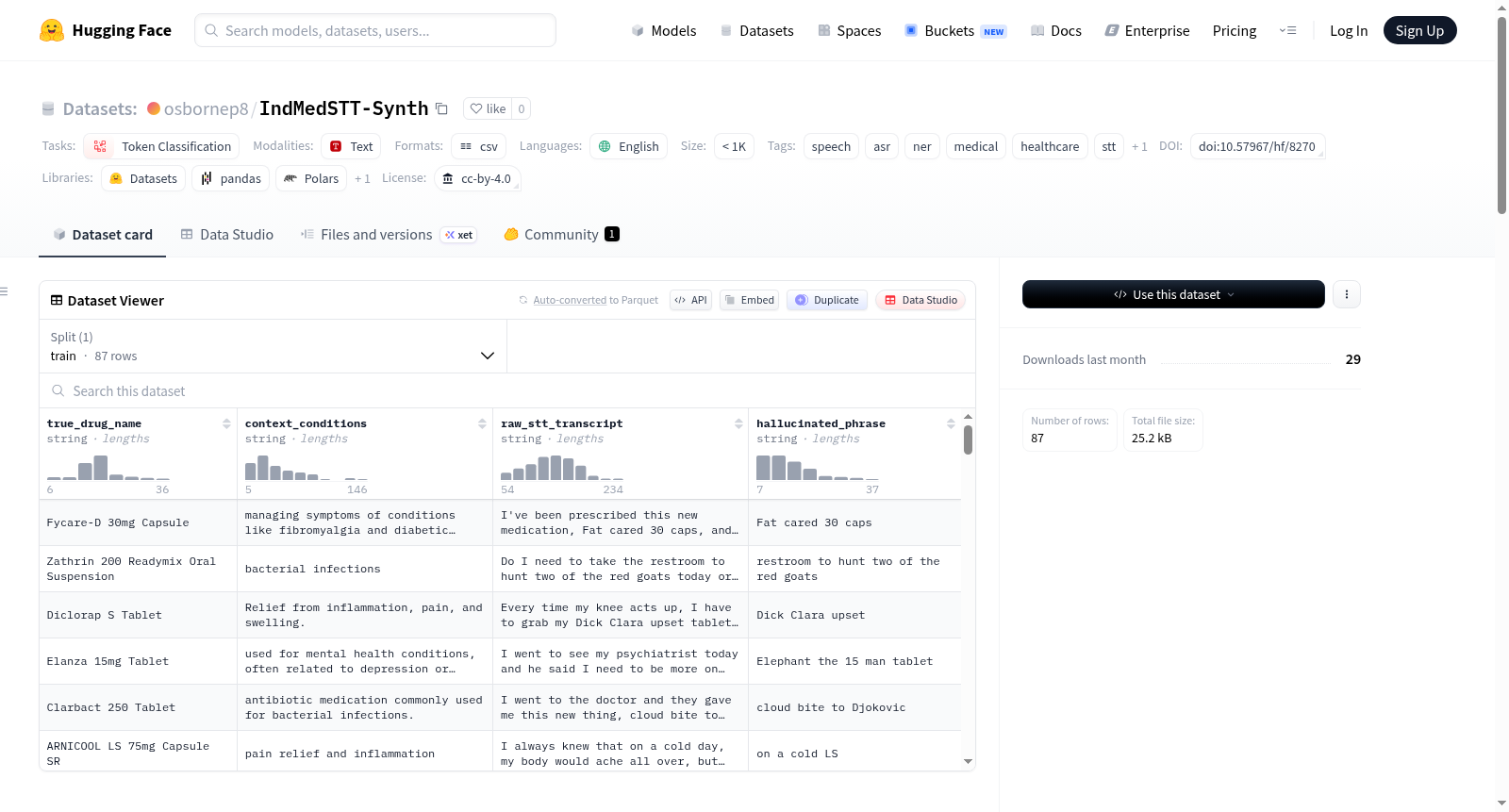
数据模式
| 字段 | 描述 |
|---|---|
| true_drug_name | 正确的印度药物品牌名称 |
| context_conditions | 药物被处方治疗的医疗状况 |
| raw_stt_transcript | STT输出中完整的患者句子 |
| hallucinated_phrase | 替代药物名称的具体单词或短语 |
数据示例
| true_drug_name | context_conditions | raw_stt_transcript | misconstrued_phrase |
|---|---|---|---|
| Azithral 500 Tablet | 细菌感染、尿路感染 | My doctor prescribed as it roll yesterday. | as it roll |
数据集局限性
- 仅使用单一大型语言模型生成;幻觉模式可能无法完全代表真实多样的STT自动纠正行为。
- 每个句子仅提及单一药物。
- 不包含通用药物名称(如扑热息痛、布洛芬等)。
- 仅限英语;不包含代码混合句子。
引用信息
bibtex @dataset{indmedstt_synthv1_2026, author = {Osborne Pereira}, title = {IndMedSTT-Synth: Synthetic STT Hallucination Dataset for Indian Medication Brand Names}, year = {2026}, publisher = {IndRAH.AI}, url = {https://huggingface.co/datasets/osbornep8/IndMedSTT-Synth}, license = {CC BY 4.0}, version = {1.0} }
许可证
本数据集根据知识共享署名4.0国际许可证发布。许可证链接:https://creativecommons.org/licenses/by/4.0/
搜集汇总
数据集介绍
构建方式
在医疗语音识别领域,印度患者常以英语品牌名称描述药物,而多语言语音转文字模型易将其误转为发音相近但语义无关的短语。本数据集通过GPT-4o模拟此类STT自动纠错行为生成初始样本,随后从公开印度药品数据库中选取真实品牌名称,构建包含正确药名、医疗背景、误转文本及误转短语的配对数据。生成样本经人工严格审查,剔除临床不合理或语言不自然的条目,约12%的样本被丢弃,30%经大幅修订,最终形成87条高质量标注数据。
使用方法
研究人员可利用本数据集开展医疗语音识别错误分析与修正模型训练,尤其适用于印度多语言或语码混合语音场景下的药物实体识别任务。使用时,可依据true_drug_name与hallucinated_phrase的对应关系,构建序列标注或文本生成模型,以识别并纠正STT输出中的药物名称误转。数据以表格形式组织,支持直接加载至自然语言处理框架,用户需注意数据仅含英语样本且每句仅提及单一药物,适用于探索有限但典型的误转模式,并可通过配套数据集IndMedSTT-Voice扩展研究范围。
背景与挑战
背景概述
在医疗语音识别领域,印度多语言环境下的药物名称识别长期面临独特挑战。IndMedSTT-Synth数据集由Osborne Pereira于2026年创建,旨在应对印度患者使用英语品牌名描述药物时,语音转文字系统产生的语义扭曲现象。该数据集聚焦于后ASR阶段的药物命名实体识别与错误校正研究,通过模拟STT系统对印度常见药品品牌的语音误译,为提升医疗对话系统的临床准确性提供了关键数据支持。其生成过程结合GPT-4o仿真与人工校验,体现了跨语言医疗信息技术的前沿探索。
当前挑战
该数据集致力于解决印度多语言医疗语音识别中药物实体误译的校正难题,其核心挑战在于如何准确捕捉STT系统将药物品牌名自动纠错为发音相近但语义无关词汇的复杂模式。构建过程中面临多重困难:首先,依赖单一大型语言模型生成样本可能导致幻觉模式无法全面反映真实STT系统的多样性错误;其次,人工筛选需平衡临床合理性与语言自然度,约12%的生成样本被剔除;此外,数据集目前仅包含英语单句样本,尚未涵盖代码混合语句与通用药品名称,限制了其在真实多语言场景的应用广度。
常用场景
经典使用场景
在印度多语言医疗语音识别领域,IndMedSTT-Synth数据集为研究自动语音识别系统在转录药物品牌名称时产生的典型错误提供了关键资源。该数据集通过模拟真实场景中STT模型将药物名称误转为近似发音的英文短语的现象,支持开发针对印度患者语音的命名实体识别与错误校正算法,尤其适用于处理英语药物名称在多种语言背景下的识别挑战。
解决学术问题
该数据集主要解决了医疗语音识别中药物名称误识别的学术难题,揭示了多语言ASR系统在印度语境下对专有名词的自动校正偏差。通过提供标注的误转录样本,它助力于构建更鲁棒的医疗NER模型,并推动了跨语言语音处理中错误分析与校正机制的研究,为提升临床语音助手的准确性奠定了数据基础。
实际应用
在实际应用中,IndMedSTT-Synth数据集可集成到医疗语音助手或电子健康记录系统中,用于检测和纠正患者描述药物时的转录错误。这有助于减少因ASR误解导致的医疗失误,增强印度多语言医疗环境的沟通效率,并为开发面向全球南方地区的个性化语音技术提供实践参考。
数据集最近研究
最新研究方向
在医疗语音识别领域,针对多语言环境下的药物名称识别错误问题,IndMedSTT-Synth数据集为前沿研究提供了关键支持。该数据集聚焦于印度患者语音中药物品牌名被自动语音识别系统误转写为音近英语短语的现象,推动了后ASR阶段的命名实体识别与错误纠正技术发展。当前研究热点集中于利用合成数据训练鲁棒性更强的NER模型,以应对真实临床场景中代码混合与多语言语音的挑战。这一方向不仅提升了医疗对话系统的准确性,也为全球多语言医疗AI应用奠定了重要基础,具有显著的临床与实践意义。
以上内容由遇见数据集搜集并总结生成


