documents.un.org_search_result
收藏Hugging Face2025-09-13 更新2025-09-14 收录
下载链接:
https://huggingface.co/datasets/bot-yaya/documents.un.org_search_result
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集包含了来自联合国文档搜索系统的文档数据,其中包括文档ID、符号、主题、发布日期、区域、分发情况、议程、会议、职位编号、发布日期、大小和标题等多种信息。数据集已被划分为训练集,可用于各种文本处理和分析任务。
创建时间:
2025-09-10
原始信息汇总
数据集概述
基本信息
- 数据集名称:documents.un.org_search_result
- 数据来源:联合国文件官网搜索系统(documents.un.org)
- 收集时间:2025年9月11日
- 总样本量:593,999条
- 总数据大小:466,314,405字节
- 下载大小:113,909,557字节
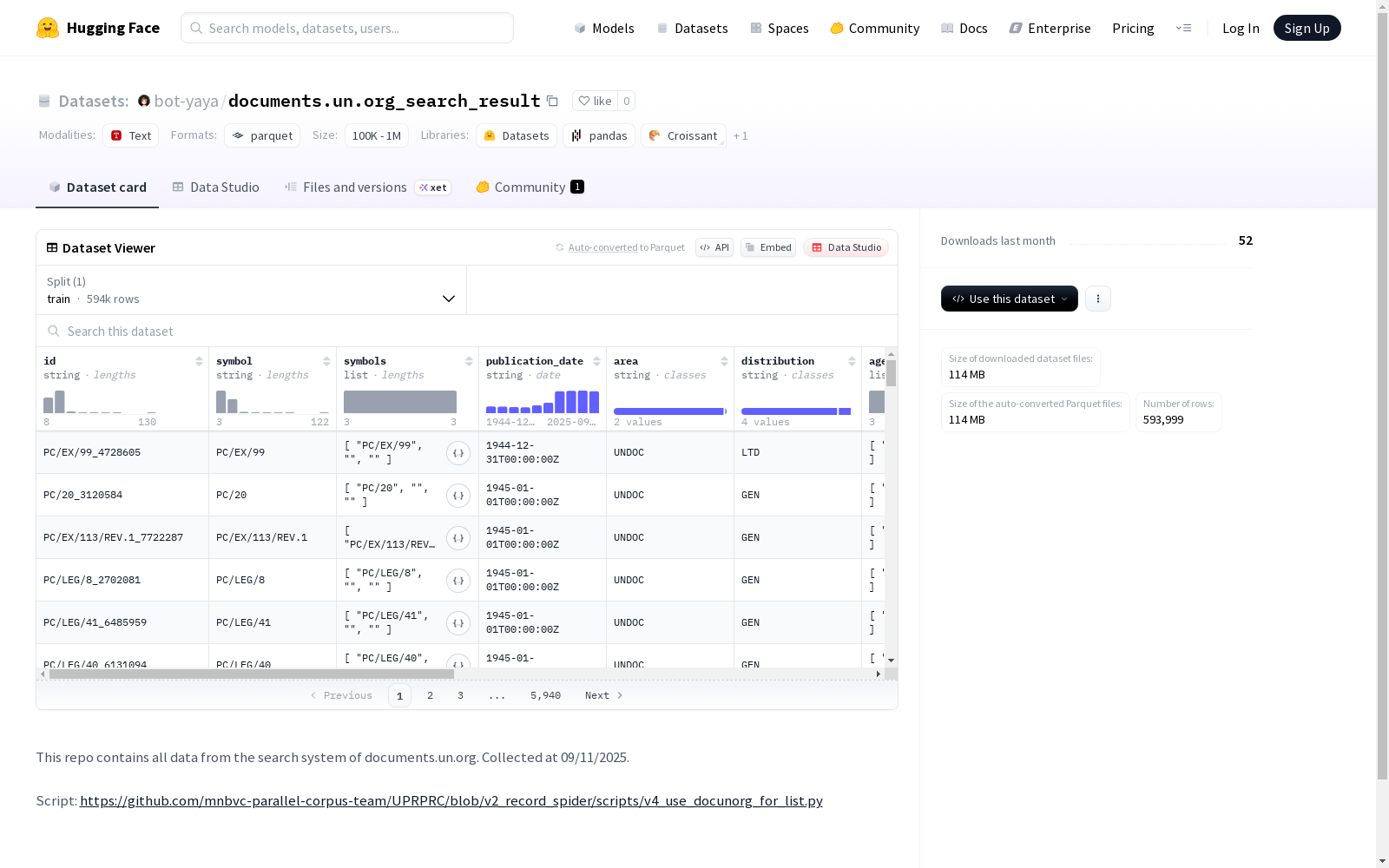
数据结构
特征字段
- id:字符串类型,唯一标识符
- symbol:字符串类型,文件符号
- symbols:字符串列表,文件符号集合
- publication_date:字符串类型,发布日期
- area:字符串类型,地区信息
- distribution:字符串类型,分发范围
- agendas:字符串列表,议程列表
- sessions:字符串列表,会议届次列表
- job_numbers:字符串列表,工作编号列表
- release_dates:字符串列表,发布日期列表
- sizes:整型列表,文件大小列表(单位:字节)
- title:字符串类型,文件标题
- subjects:字符串列表,主题列表
数据划分
- 训练集(train)
- 样本数量:593,999条
- 数据大小:466,314,405字节
数据采集
- 采集脚本:https://github.com/mnbvc-parallel-corpus-team/UPRPRC/blob/v2_record_spider/scripts/v4_use_docunorg_for_list.py
- 数据完整性:包含联合国文件官网搜索系统的全部数据
搜集汇总
数据集介绍
构建方式
在联合国文献数字化管理的背景下,documents.un.org_search_result数据集通过自动化脚本系统性地爬取联合国官方文件搜索平台的全部文档数据。采集过程基于GitHub开源代码库中的定制化脚本,精确提取了包括文件标识符、议程信息、会议届次及发布范围在内的结构化元数据,确保了数据来源的权威性与完整性。
特点
该数据集涵盖近60万条联合国文件记录,每条数据包含多维度特征如文件符号链、议程分类、会议届次和主题标签等。其突出特点在于采用嵌套列表结构存储关联数据(如多议程编号和会议届次),并保留原始文件大小与发布时间戳,为研究国际组织文书体系提供了高颗粒度的分析基础。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,利用其标准化的字段结构进行国际关系文本挖掘。典型应用包括基于主题字段的文档分类、按会议届次的时间序列分析,或结合文件符号体系构建跨文档关联网络。数据以Apache Parquet格式存储,支持分布式处理框架的高效读取。
背景与挑战
背景概述
联合国文件检索数据集documents.un.org_search_result由mnbvc-parallel-corpus-team于2025年9月构建,旨在系统化归档联合国官方文献的元数据信息。该数据集涵盖近60万条记录,包含文件编号、议程分类、发布周期等多维度特征,为国际关系、政策分析和多语言文档处理研究提供了结构化数据基础。其构建推动了国际组织文献数字化进程,为跨语言信息检索和外交文本挖掘领域提供了关键资源支撑。
当前挑战
该数据集核心挑战在于解决多语言外交文献的异构性整合问题,需克服联合国文件分类体系复杂、元数据字段跨语言不一致等难题。构建过程中面临网页结构动态变更导致的数据采集完整性风险,以及非标准化日期格式、多值字段的归一化处理等技术瓶颈,同时需确保敏感政治信息的合规性处理。
常用场景
经典使用场景
在联合国文献研究领域,该数据集为学者提供了系统性的文本分析基础。其经典使用场景包括国际关系学者对决议文本的语义挖掘、法律专家对公约条款的演变分析,以及政治学家对议程设置模式的量化研究。通过近60万份官方文档的结构化数据,研究者能够追踪特定议题的政策演变轨迹。
解决学术问题
该数据集有效解决了国际组织文献数字化治理中的关键学术问题。它使得研究者能够系统分析多边外交文本的生成规律,验证国际规范扩散理论,并量化评估议程设置的影响因素。通过机器可读的元数据体系,为国际关系计算社会科学提供了前所未有的实证基础,推动了传统定性研究向数据驱动范式的转型。
衍生相关工作
基于该数据集衍生的经典工作包括联合国决议文本自动摘要系统、国际议题关联网络分析模型以及多语言法律文档对齐工具。研究者开发了基于符号编码的文献溯源算法,建立了议程主题演化图谱,并构建了跨届会议文件关联体系,这些成果显著推进了计算外交学的发展进程。
以上内容由遇见数据集搜集并总结生成


