tweetfeels-1m6
收藏Hugging Face2025-08-30 更新2025-08-31 收录
下载链接:
https://huggingface.co/datasets/mnemoraorg/tweetfeels-1m6
下载链接
链接失效反馈官方服务:
资源简介:
TweetFeels 1m6是一个包含超过一百万条英文推文的数据集,这些推文是在2009年通过Twitter API收集的。每条推文根据表情符号自动标记了情感极性,分为负面、中性(稀疏)和正面。数据集以CSV格式提供,包括情感极性、推文ID、发布日期、搜索查询、用户屏幕名称和推文文本。
创建时间:
2025-08-29
原始信息汇总
TweetFeels 1m6 数据集概述
数据集基本信息
- 许可证类型:ECL-2.0
- 任务类别:文本分类
- 支持语言:英语(en)
- 数据集标签:公共、文本、教育、情感分析
- 数据集规模:100万到1000万条样本之间(1M<n<10M)
数据内容与结构
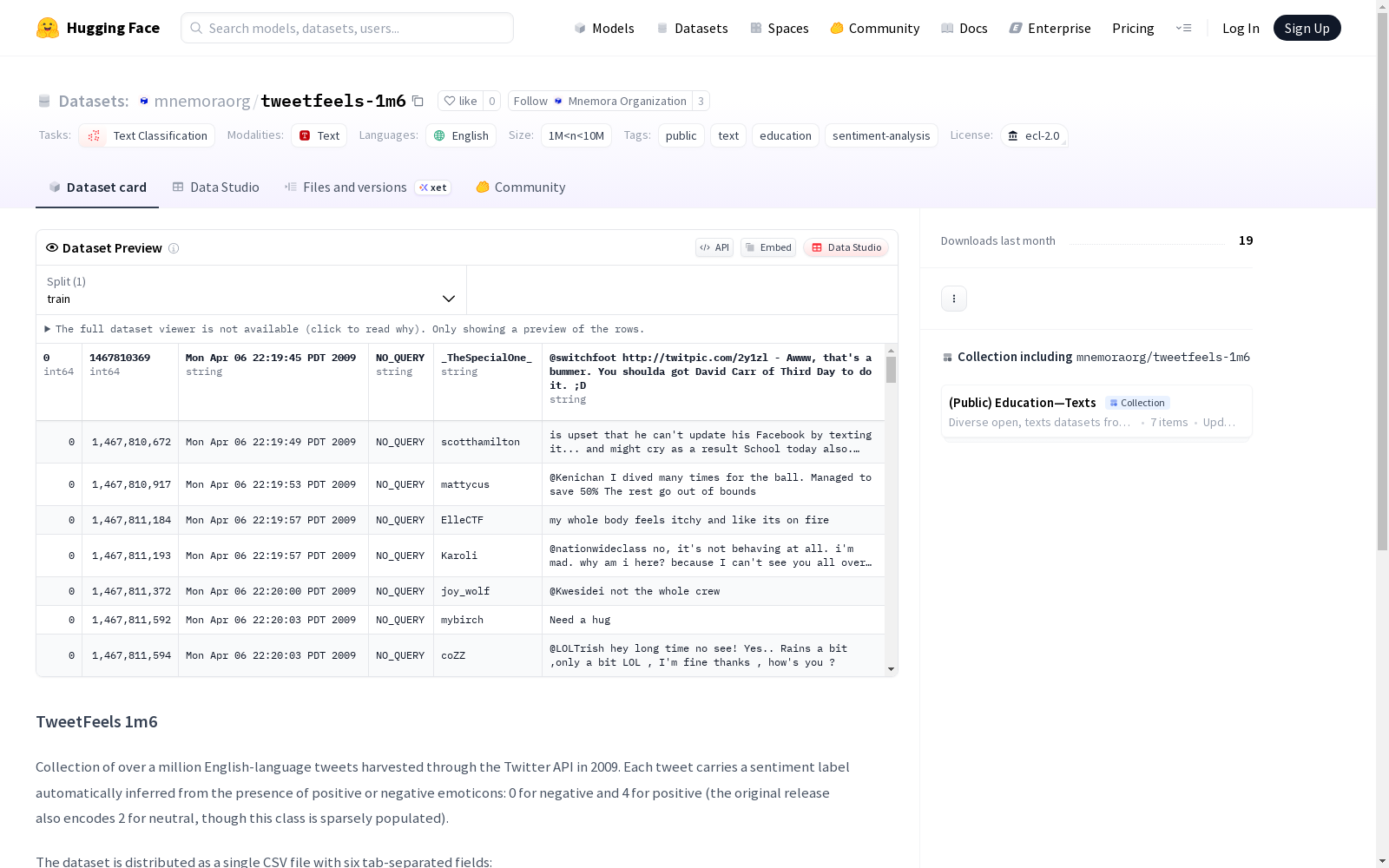
数据集包含超过100万条2009年通过Twitter API收集的英文推文。每条推文带有通过表情符号自动推断的情感标签:0表示负面,4表示正面(原始版本还包含2表示中性,但该类别样本稀疏)。
数据以单个CSV文件形式分发,包含以下六个制表符分隔的字段:
- target:情感极性(0、2、4)
- ids:唯一推文ID
- date:发布时的UTC时间戳
- flag:匹配推文的搜索查询,或“NO_QUERY”
- user:发布账户的屏幕名称
- text:完整的推文文本,保留表情符号和URL
数据特点
- 标注方式:未进行人工标注,通过基于表情符号存在的远程监督分配标签
- 内容特征:涵盖多样化主题和Twitter典型的非正式语言模式
- 应用场景:作为大规模情感分析和社交媒体文本挖掘任务的标准基准数据集
数据来源
数据集可通过Kaggle—Sentiment140获取:https://www.kaggle.com/datasets/kazanova/sentiment140?resource=download
搜集汇总
数据集介绍
构建方式
在社交媒体情感分析领域,TweetFeels-1m6数据集通过远距离监督方法构建,利用2009年Twitter API采集的超过一百万条英文推文。每条推文的情感标签基于正负面表情符号自动推断:负面情感标记为0,正面情感标记为4,原始版本虽包含中性标签2但样本稀少。数据以CSV格式存储,包含情感极性、推文ID、时间戳、查询标记、用户名称及完整文本六个字段,未经过人工标注,完全依赖表情符号的分布式特征实现自动化标注。
特点
该数据集显著特点在于其大规模真实社交媒体文本覆盖,涵盖多样主题和非正式语言模式,完美保留了表情符号与URL等原始数字痕迹。情感标签体系采用经典的三分类框架,但中性类别样本稀缺,形成以极性和非极性情感为主的分布格局。时间戳和用户元数据为时序分析和用户行为研究提供可能,而基于查询标记的追踪机制则增强了数据来源的可解释性,使其成为社交媒体文本挖掘领域的标准基准数据集。
使用方法
研究者可加载CSV文件后直接提取文本字段与目标标签,用于训练情感分类模型或进行社交媒体语言模式分析。建议预处理阶段保留表情符号以维持远监督标签的可靠性,同时可利用时间戳字段进行纵向情感趋势研究。由于标签通过自动化方式生成,验证时应考虑采用人工标注子集评估模型泛化能力,并可结合用户字段开展跨用户情感表达差异性分析。
背景与挑战
背景概述
情感计算作为自然语言处理的重要分支,其发展在社交媒体时代获得显著推动。TweetFeels-1m6数据集由斯坦福大学研究人员于2009年通过Twitter API构建,旨在捕捉大规模社交媒体文本中的情感极性。该数据集采用远距离监督方法,通过表情符号自动标注情感标签,涵盖超过一百万条英文推文,为情感分析研究提供了宝贵的实证基础。其创新性在于利用社交媒体原生特征进行自动标注,显著降低了人工标注成本,推动了基于弱监督学习的文本情感分析范式发展,对计算社会科学和商业智能领域产生深远影响。
当前挑战
该数据集核心挑战在于解决社交媒体文本情感分类的复杂性,包括非正式语言表达、讽刺隐喻识别以及领域适应性等问题。构建过程中面临多重技术挑战:首先,基于表情符号的远距离监督标注存在噪声干扰,部分中性文本被错误归类;其次,2009年推特数据采集受API限制导致主题覆盖不均衡;最后,文本预处理过程中需要保留原始语言特征(如URL和表情符号)同时确保数据匿名化,这对大规模数据处理管道设计提出较高要求。
常用场景
经典使用场景
在社交媒体情感分析领域,TweetFeels-1m6数据集作为早期大规模标注语料,被广泛用于训练和评估情感分类模型。研究者常利用其百万级带情感标签的推文数据,探索文本情感极性自动判别的算法效果,尤其在监督学习框架下验证特征提取与分类器的性能表现。
衍生相关工作
该数据集催生了多项经典研究,包括基于深度学习的端到端情感分类模型创新,以及跨领域情感迁移学习方法的探索。后续工作还拓展了多模态情感分析,结合文本与表情符号特征构建混合模型,显著提升了社交媒体情感识别的准确性与鲁棒性。
数据集最近研究
最新研究方向
在社交媒体情感分析领域,TweetFeels-1m6数据集持续推动基于远程监督的自动标注技术研究,其以表情符号为标签依据的构建方法成为弱监督学习的重要范例。当前前沿工作聚焦于结合预训练语言模型如BERT和RoBERTa,提升对推特非正式文本中讽刺、多义表达的识别精度。该数据集与新兴的多模态情感分析相结合,研究者尝试整合文本与表情符号的联合表征,以应对社交媒体语境中情感表达的复杂性。近年来,该数据集还被用于探索跨领域情感迁移学习,以及在虚假信息检测、社会情绪追踪等热点事件中的应用,为 computational social science 提供了大规模历史语料支撑。
以上内容由遇见数据集搜集并总结生成


