lung_cancer_5K.jsonl
收藏Hugging Face2025-08-26 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/monfortbrian/lung_cancer_5K.jsonl
下载链接
链接失效反馈官方服务:
资源简介:
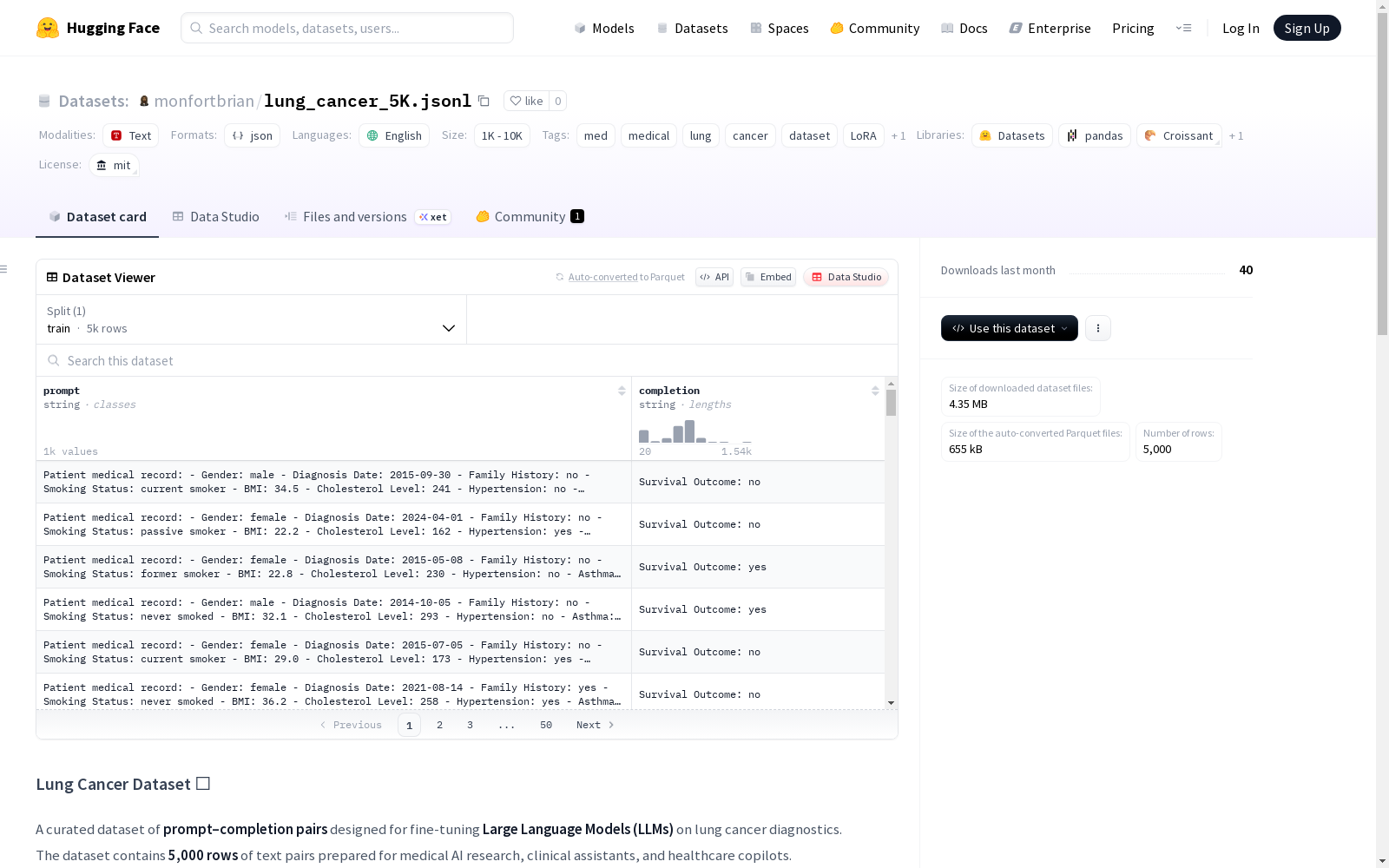
这是一个包含5000个用于肺癌诊断的提示-完成对的数据集,旨在微调大型语言模型(LLMs)。数据集涵盖了诊断、症状、治疗和随访等肺癌领域的文本对,适用于训练医生副驾驶和临床诊断支持系统。
This is a dataset containing 5,000 prompt-completion pairs for lung cancer diagnosis, aimed at fine-tuning Large Language Models (LLMs). The dataset covers text pairs in the lung cancer domain including diagnosis, symptoms, treatment and follow-up, and is suitable for training doctor copilots and clinical diagnosis support systems.
创建时间:
2025-08-25
原始信息汇总
Lung Cancer Dataset 🫁 概述
数据集基本信息
- 许可证:MIT
- 语言:英语(en)
- 标签:医学、医疗、肺部、癌症、数据集、LoRA、PEFT
数据规模与格式
- 规模:5,000 个提示-完成对
- 格式:JSONL、CSV
- 领域:肺癌(诊断、症状、治疗、随访)
数据来源与处理
- 来源:源自互联网内容,经过仔细释义和整理
- 处理:经过清理、规范化和匿名化,以移除敏感信息
- 结构:针对 PEFT / LoRA 微调优化,具有平衡的提示-完成对齐
应用场景
- 用于微调大型语言模型(LLMs),实现快速、特定领域的医学推理
- 为医生和医疗专业人员构建诊断协导系统
- 研究人工智能辅助的癌症检测和治疗规划
文件详情
lung_cancer_dataset.jsonl→ JSON Lines 格式(推荐用于训练)lung_cancer_dataset.csv→ CSV 格式(用于探索和预处理)
免责声明
- 本数据集仅用于研究和教育目的
- 不能替代专业医疗建议、诊断或治疗
背景灵感
- 本数据集是“医生协导系统最小可行产品(Doctor Copilot MVP)”的一部分
- 旨在创建安全、可靠、高效的人工智能辅助医疗系统,用于早期检测和改善患者预后
搜集汇总
数据集介绍
构建方式
在医学人工智能研究领域,高质量数据集的构建至关重要。本数据集通过互联网采集原始内容,经过细致的释义和筛选流程,确保信息的准确性与多样性。数据经过清洗、标准化和匿名化处理,有效剔除了敏感信息,最终形成结构化的提示-补全对。其设计专门针对参数高效微调技术,保持了提示与补全间的高度平衡,为模型训练提供了可靠基础。
特点
该数据集聚焦肺癌诊断领域,涵盖症状分析、治疗方案及随访管理等关键维度。其包含5000条高质量的文本对,以JSONL和CSV格式提供,兼顾训练效率与数据处理灵活性。数据经过严格匿名化处理,既符合伦理规范,又满足医疗AI模型对专业性和安全性的双重需求,为临床辅助系统的开发提供了坚实支撑。
使用方法
研究人员可利用该数据集进行大语言模型的领域特异性微调,尤其适合采用LoRA等参数高效方法。通过加载JSONL格式文件,模型能够学习肺癌诊断的专业知识,进而构建临床辅助推理系统。使用时需注意遵循研究伦理规范,确保输出结果仅作为专业医疗决策的参考依据,而非直接替代医学诊断。
背景与挑战
背景概述
肺癌作为全球范围内发病率和死亡率最高的恶性肿瘤之一,其早期诊断与精准治疗一直是医学界关注的焦点。lung_cancer_5K.jsonl数据集由医学人工智能研究团队于近年开发,旨在为大型语言模型提供高质量的肺癌诊断领域微调数据。该数据集包含5000条经过严格清洗和匿名化处理的提示-补全对,覆盖肺癌的症状识别、诊断流程、治疗方案及随访管理等核心临床问题,为构建医生辅助决策系统提供了关键数据支撑,推动了人工智能在肿瘤学领域的应用深化。
当前挑战
肺癌诊断领域面临临床表述多样性、医学术语复杂性及诊断逻辑严谨性等多重挑战,要求模型具备高精度医学知识理解与推理能力。数据集构建过程中需克服原始数据敏感性高、医学语境还原难度大等困难,通过人工 paraphrasing 与结构化对齐确保数据质量,同时平衡医学准确性与语言模型训练需求,避免隐私泄露与伦理争议。
常用场景
经典使用场景
在医学人工智能研究领域,该数据集被广泛用于训练大型语言模型进行肺癌诊断辅助。通过精心构建的提示-完成对,研究者能够微调模型以理解临床症状描述与诊断建议之间的复杂映射关系,为临床决策支持系统提供高质量的训练基础。
解决学术问题
该数据集有效解决了医学自然语言处理中专业领域数据稀缺的学术难题,为肺癌诊断的智能辅助研究提供了标准化语料。其匿名化处理保障了患者隐私,而精准的提示对齐机制则显著提升了模型在症状识别和治疗建议生成方面的表现,推动了医学AI的可信化发展。
衍生相关工作
基于该数据集衍生了多项经典研究,包括采用LoRA微调技术的肺癌诊断专用模型、结合多模态数据的智能分诊系统,以及符合医疗合规要求的风险控制框架。这些工作显著推动了医学大模型在临床场景中的安全落地与应用创新。
以上内容由遇见数据集搜集并总结生成


