car-bench-dataset
收藏Hugging Face2026-02-12 更新2026-02-13 收录
下载链接:
https://huggingface.co/datasets/johanneskirmayr/car-bench-dataset
下载链接
链接失效反馈官方服务:
资源简介:
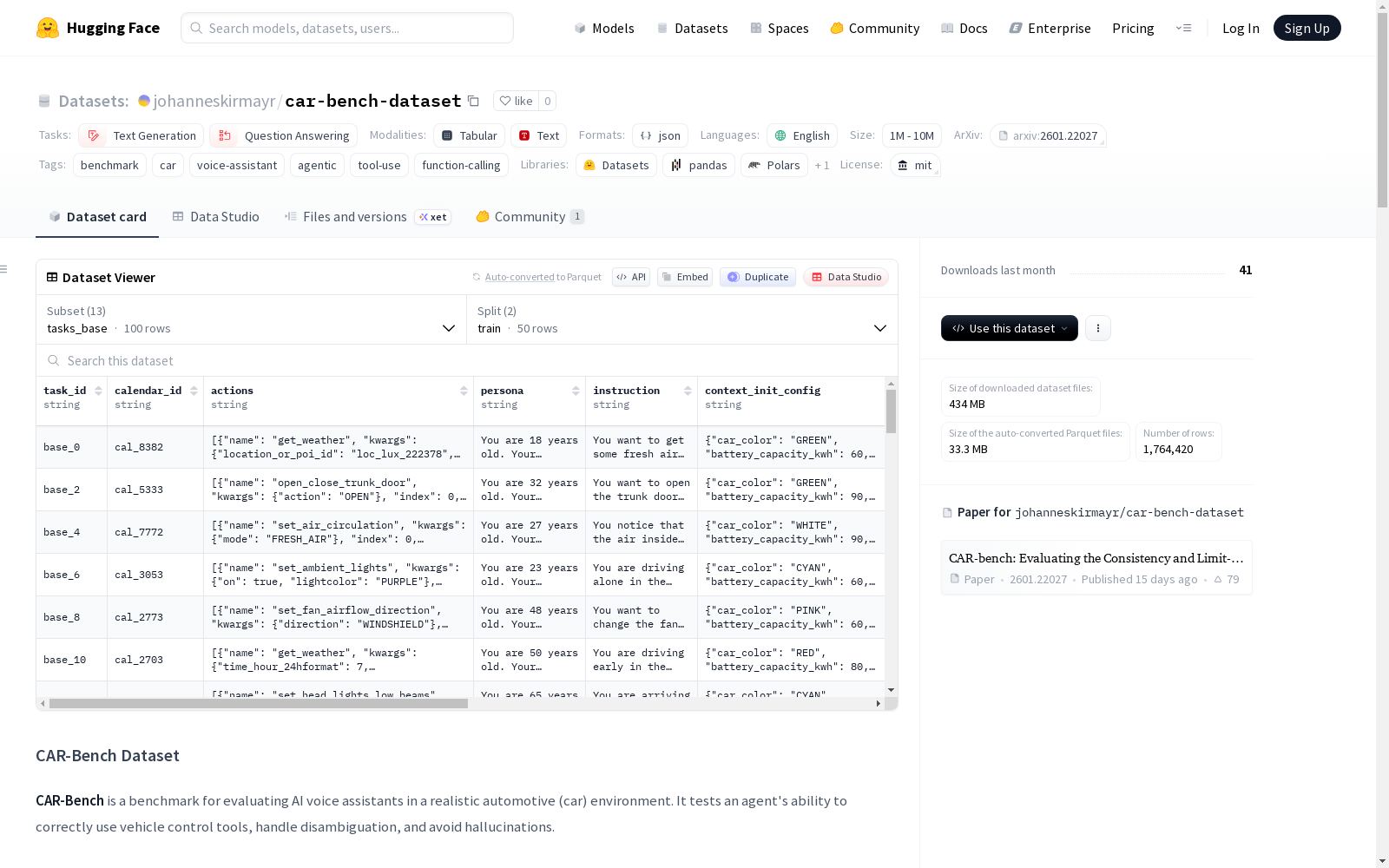
CAR-Bench 是一个用于在真实汽车环境中评估 AI 语音助手的基准测试数据集。它测试代理正确使用车辆控制工具、处理歧义和避免幻觉的能力。数据集分为任务配置和模拟数据配置两部分。任务配置包括基本任务、歧义任务和幻觉任务,每个任务定义了用户角色、指令、初始车辆/环境上下文以及助手应执行的工具调用动作的真实序列。模拟数据配置模拟了汽车环境数据库,包括位置、兴趣点、天气、路线、日历和联系人等数据。数据集适用于文本生成和问答任务,规模在1K到10K之间,语言为英语。
创建时间:
2026-02-10
原始信息汇总
CAR-Bench 数据集概述
数据集基本信息
- 数据集名称: CAR-Bench Dataset
- 数据集地址: https://huggingface.co/datasets/johanneskirmayr/car-bench-dataset
- 许可证: mit
- 任务类别: 文本生成、问答
- 语言: 英语
- 标签: 基准测试、汽车、语音助手、智能体、工具使用、函数调用
- 数据规模: 1K<n<10K
数据集目的
CAR-Bench 是一个用于在真实汽车环境中评估人工智能语音助手的基准测试。它测试智能体正确使用车辆控制工具、处理歧义和避免幻觉的能力。
数据集结构
数据集分为任务配置和模拟数据配置。
任务配置
每个任务定义了用户角色、指令、初始车辆/环境上下文以及助手应执行的工具调用操作的真实序列。
| 配置名称 | 描述 | 训练集大小 | 测试集大小 |
|---|---|---|---|
tasks_base |
涵盖车辆控制、导航、日历等的标准任务 | 50 | 50 |
tasks_disambiguation |
要求智能体消除参数歧义的任务 | 30 | 26 |
tasks_hallucination |
故意移除某些工具/参数以测试智能体是否产生幻觉的任务 | 48 | 50 |
任务模式字段:
task_id: 字符串,唯一任务标识符persona: 字符串,模拟用户的个性和沟通风格描述calendar_id: 字符串,模拟数据中日历的引用instruction: 字符串,给予模拟用户的指令context_init_config: 字符串,初始车辆和环境状态actions: 字符串,工具调用的真实序列task_type: 字符串,任务类型disambiguation_element_internal: 字符串或空,需要内部消除歧义的元素disambiguation_element_user: 字符串或空,需要向用户澄清的元素disambiguation_element_note: 字符串或空,解释歧义的注释removed_part: 字符串或空,被移除的工具/参数
模拟数据配置
模拟数据模拟了基准测试执行期间工具使用的真实汽车环境数据库。
| 配置名称 | 数据行数 | 描述 |
|---|---|---|
mock_locations |
48 | 带有GPS坐标的欧洲城市 |
mock_pois |
130,693 | 兴趣点 |
mock_weather |
48 | 每个位置的天气数据 |
mock_routes_location_location |
6,768 | 位置之间的路线 |
mock_routes_location_poi |
1,378 | 从位置到兴趣点的路线 |
mock_routes_poi_location |
1,378 | 从兴趣点到位置的路线 |
mock_routes_index |
1,763,870 | 路线查找索引 |
mock_routes_metadata |
1,754,346 | 兴趣点到兴趣点路线生成的元数据 |
mock_calendars |
100 | 包含会议的日历条目 |
mock_contacts |
100 | 联系人信息 |
使用方式
与 CAR-Bench 基准测试一起使用
CAR-Bench 代码库自动从此数据集加载任务和模拟数据。
独立使用
使用 datasets 库加载数据集,并可解析嵌套的JSON字段。
引用
如果使用此数据集,请引用 CAR-Bench 论文。
搜集汇总
数据集介绍
构建方式
在车载语音助手领域,CAR-Bench数据集的构建采用了分层结构设计,以模拟真实汽车环境中的交互场景。其核心任务配置分为基础任务、消歧任务和幻觉任务三大类,每类任务均包含训练集与测试集,通过JSONL格式存储用户角色、指令、初始车辆状态及标准工具调用序列。同时,数据集集成了丰富的模拟数据,涵盖欧洲城市位置、海量兴趣点、实时天气信息、复杂路线网络以及日历与联系人条目,这些数据通过结构化文件组织,为工具调用提供了接近现实的上下文支持。
特点
该数据集的特点在于其高度仿真的车载环境模拟与多维度的评估框架。它不仅覆盖了车辆控制、导航、日程管理等基础功能,还专门设计了消歧任务以测试模型在参数模糊时的决策能力,以及幻觉任务用于检验模型在工具或参数缺失时的抗干扰性。数据集通过细致的用户角色描述和动态环境状态初始化,增强了任务的真实性与复杂性,而超过百万条路线索引与元数据的集成,则确保了导航逻辑的严密性与可扩展性。
使用方法
使用CAR-Bench数据集时,研究者可通过Hugging Face的datasets库直接加载任务与模拟数据。例如,加载基础任务配置后,可解析嵌套的JSON字段以获取初始上下文与标准动作序列,进而评估语音助手在模拟环境中的工具调用准确性。数据集与CAR-Bench代码库深度集成,支持通过命令行运行特定任务类型的基准测试,便于系统化评估模型在不确定性下的表现。独立使用时,模拟数据如地理位置与联系人信息可作为外部知识库,增强代理的环境感知能力。
背景与挑战
背景概述
随着大型语言模型在智能体应用中的深入发展,车载语音助手作为典型的人机交互场景,对模型的工具调用、上下文理解与抗幻觉能力提出了更高要求。CAR-Bench数据集由Johannes Kirmayr等人于2026年构建,旨在为汽车环境下的AI语音助手提供一个真实且系统的评估基准。该数据集通过模拟车辆控制、导航、日程管理等复杂任务,聚焦于检验智能体在现实不确定性中的一致性表现与极限感知能力,推动了具身智能与多模态交互领域的研究进展。
当前挑战
在车载语音助手领域,核心挑战在于智能体需准确解析模糊指令、处理动态环境参数并避免生成虚构工具调用,这对模型的推理可靠性与上下文适应性提出了严峻考验。数据集的构建过程同样面临多重挑战:一是需要设计涵盖歧义消解与幻觉检测的多样化任务结构,以全面评估模型缺陷;二是必须构建规模庞大且逻辑严密的模拟数据网络,包括数十万量级的兴趣点与路径关系,以还原真实驾驶场景的复杂性。
常用场景
经典使用场景
在汽车人工智能领域,CAR-Bench数据集被广泛应用于评估语音助手在真实车载环境中的性能。该数据集通过模拟用户指令、车辆状态和外部环境,构建了涵盖基础控制、导航、日程管理等任务的基准测试场景。研究人员利用其结构化的任务配置和模拟数据,系统性地测试智能代理在工具调用、参数解析和上下文理解方面的能力,为车载语音交互系统的开发提供了标准化评估框架。
解决学术问题
CAR-Bench数据集主要解决了智能代理在复杂现实场景中的一致性、消歧和幻觉抑制等关键学术问题。通过设计消歧任务和幻觉检测任务,该数据集能够量化评估模型在参数模糊或工具缺失时的推理鲁棒性,推动了具身智能领域中对不确定性处理和边界感知能力的研究。其细粒度的任务分类为理解语言模型在动态环境中的行为模式提供了实证基础,促进了智能体可靠性理论的深化。
衍生相关工作
围绕CAR-Bench数据集,学术界衍生出一系列关于具身智能评估的经典研究。例如,基于其任务架构开发的自动化基准测试工具链,被广泛应用于对比不同语言模型在车载场景下的工具使用能力。相关研究进一步扩展了数据集的边界,探索了多模态交互、长期记忆融合等方向,形成了以汽车环境为典型代表的受限领域智能体评估方法论体系。
以上内容由遇见数据集搜集并总结生成


